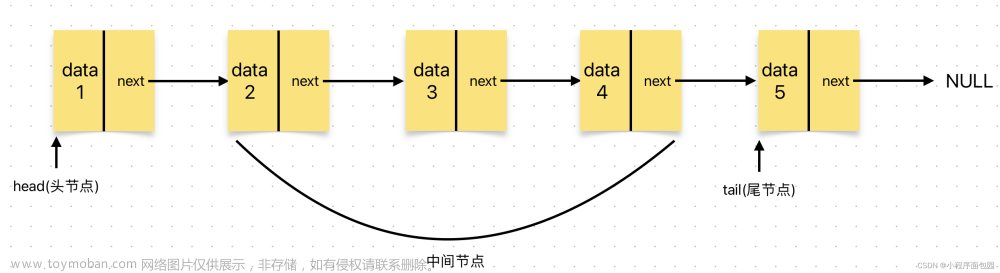
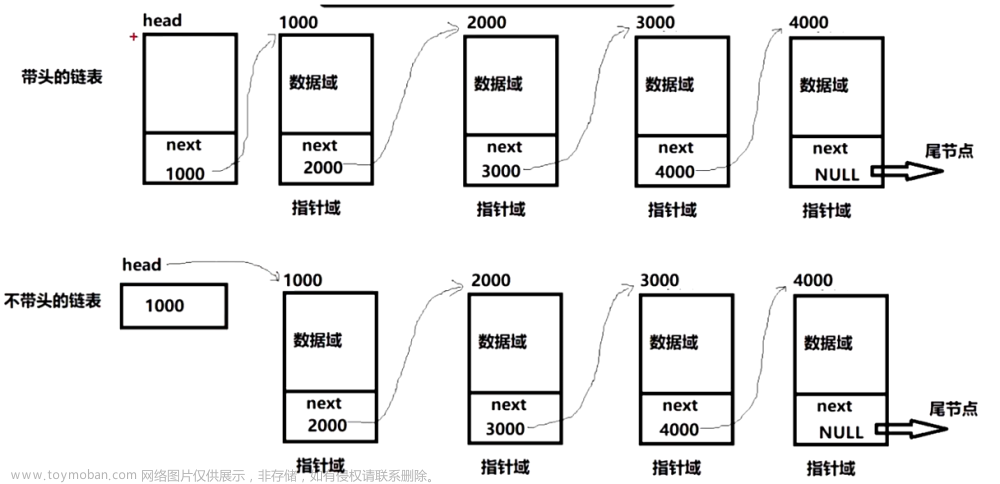
链表
单链表的结构体定义及其初始化。
typedef struct LNode {
int data;
struct LNode* next;
}LNode, *LinkList;
①强调结点 LNode *p;
②强调链表 LinkList p;
//初始化
LNode* initList() {
//定义头结点
LNode* L = (LNode*)malloc(sizeof(LNode));
L->next = NULL;
return L;
}
01 遍历打印
//带头结点单链表遍历打印
void Listvisit(LinkList L) {
LNode* p = L->next;
while (p != NULL) {
printf("%d", p->data);
p = p->next;
}
}
//不带头结点单链表遍历打印
void Listvisit_2(LinkList L) {
LNode* p = L;
while (p != NULL) {
printf("%d", p->data);
p = p->next;
}
}
02 按位查找(有一个带头结点的单链表 L,请设计一个算法查找其第 i 个结点位置,若存在则返回指向该结点的指针,若不存在则返回 NULL。)
LNode* Search_i(LinkList L,int i) {
if (i < 1) {//判断i是否合法
return NULL;
}
LNode* p = L->next;
int k = 1;//计数
while (p != NULL && k<i) {
p = p->next;
k++;
}
return p;
}
03 按值查找(有一个带头结点的单链表 L,请设计一个算法查找其第 1 个数据值为 e的结点,若存在则返回指向该结点的指针,若不存在则返回 NULL。)
LNode* Search_e(LinkList L, int e) {
LNode* p = L->next;
while (p != NULL && p->data != e) {
p = p->next;
}
return p;
}
也可以采用下面的代码,方便理解
LNode* Search_e(LinkList L, int e) {
LNode* p = L->next;
while (p != NULL) {
if (p->data == e) {
return p;
}
else {
p = p->next;
}
}
return NULL;
}
04 采用头插法在头指针为L处建立一个带头结点的单链表,输入-1表示结束,结果返回建立的单链表
- 因为返回类型为单链表,因此使用LinkList
- 头插法,因此不需要定义其他的结点,直接L->next=xx即可
- 首先创建然后初始化头结点,然后进行头插法,其中每次创建结点需要为其分配内容与赋值,然后指针域进行变化
- while循环最后需要scanf()保证循环得以继续
LinkList List_HeadInsert(LinkList& L) {
L = (LinkList)malloc(sizeof(LNode));//创建头结点
L->next = NULL;//初始化头结点
LNode* s;//定义辅助指针 s
int x;//定义辅助变量 x
scanf("%d", &x);//输入新结点数据域中的值
while (x != -1) {//输入-1 表示输入结束
s = (LNode*)malloc(sizeof(LNode));//为新结点分配内存
s->data = x;//为新结点数据域赋值
s->next = L->next;//头插法核心代码
L->next = s;//头插法核心代码
scanf("%d", &x);//继续输入下一结点数据域中的值
}
return L;
}
05 采用尾插法在头指针为L处建立一个带头结点的单链表,输入 - 1表示结束,结果返回建立的单链表
- 尾插法需要尾指针时刻指向链表末尾,为了后续能找到插入位置;
- 尾插法是尾指针指向新创建的结点,尾插法结束需要将尾指针置空;
LinkList List_TailInsert(LinkList& L) {
L = (LinkList)malloc(sizeof(LNode));//创建头结点
L->next = NULL;//养成习惯
LNode* s, * r = L;//尾插法核心代码(定义尾指针)
int x;//定义辅助变量 x
scanf("%d", &x);//输入新结点数据域中的值
while (x != -1) {//输入-1 表示输入结束
s = (LNode*)malloc(sizeof(LNode));//为新结点分配内存
s->data = x;//为新结点数据域赋值
r->next = s;//尾插法核心代码
r = s;//尾插法核心代码(更新尾指针位置)
scanf("%d", &x);//继续输入下一结点数据域中的值
}
r->next = NULL;//尾插法核心代码(尾插结束后尾结点指针域留空)
return L;
}
06 试编写算法将带头结点的单链表就地逆置,所谓“就地”是指空间复杂度为 O(1)。
- 逆置可以想到单链表中的头插法,实现逆序排列;
- 从头结点后断开,将后续结点当作新节点插入到头结点后;
- 需要一个防断链指针指向需要操作的结点的下一个结点(防止断开找不到联系);
void Reverse(LinkList& L) {
LNode* p = L->next;//定义遍历指针 p,r 为防断链指针(头插法)
LNode* r;
L->next = NULL;//分离出 L 作为空表的头结点
while (p != NULL) {//遍历链表,将遍历到的结点重新进行头插
r = p->next;//防断链指针指向下一个需要遍历的结点位置,防止断链
p->next = L->next;//头插法核心代码
L->next = p;//头插法核心代码
p = r;//p 指针更新到下一遍历结点位置
}
}
07 将一个带头结点的单链表 A 分解为两个带头结点的单链表 A 和 B,使得A 表中含有原表中序号为奇数的元素,而 B 表中含有原表中序号为偶数的元素,且保持相对顺序不变,最后返回B表。
- 顺序不变,尾插法,需要尾指针ra和rb;
- 两个两个为一组,因此while循环里面进行2次插入结点,先将奇数序列元素插入到A表中,然后将偶数序列元素插入到B表中,然后进入下一个while循环;
LinkList Create_A_B(LinkList& A) {
LinkList B = (LinkList)malloc(sizeof(LNode));//创建 B 表头结点
B->next = NULL;
LNode* p = A->next;//定义遍历指针 p
LNode* ra = A, * rb = B;// 定义A 表 B 表尾指针
A->next = NULL;//断开 A 表头结点(这行代码可去掉)
while (p != NULL) {//遍历原表
ra->next = p;//将 p 指针所指结点尾插到 A 表
ra = p;//更新 A 表尾指针
p = p->next;//更新 p 指针,继续遍历
if (p != NULL) {//防止最后一次循环因为只有一个结点而报错
rb->next = p;//将 p 指针所指结点尾插到 B 表
rb = p; //更新 B 表尾指针
p = p->next;//更新 p 指针,继续遍历
}
}
ra->next = NULL;//A 表尾结点指针域置空
rb->next = NULL;//B 表尾结点指针域置空
return B;
}
08 编写算法将一个带头结点的单链表 A={a1,b1,a2,b2,…,an,bn}分解为两个带头结点的单链表 A 和 B,使得 A = { a1,a2,…,an },B = { bn,…,b2,b1 }。
- An顺序,尾插法-顺序,需要尾指针,且最后需要将尾指针置空,
- Bn逆序,头插法-逆序,需要防断链指针;即头插—防断链,尾插—置空;
- 定义遍历指针 p,A 表尾指针和 B 表防断链指针
- 由于An和Bn交错,因此可以两个两个处理,同上一题
LinkList Create_A_B(LinkList& A) {
LinkList B = (LinkList)malloc(sizeof(LNode));//创建 B 表头结点
B->next = NULL;//头插法需要先对头结点指针域进行初始化
LNode* p = A->next, * r = A, * q;//定义遍历指针 p,A 表尾指针和 B 表防断链指针
A->next = NULL;//断开 A 表头结点(这行代码可去掉)
while (p != NULL) {//遍历原表
r->next = p;//将 p 指针所指结点尾插到 A 表
r = p;//更新 A 表尾指针
p = p->next;//更新 p 指针,继续遍历
if (p != NULL) {//防止最后一次循环因为只有一个结点而报错
q = p->next;//防止使用头插法出现断链情况
p->next = B->next; //头插法核心代码
B->next = p;//头插法核心代码
p = q;//更新遍历指针位置
}
}
r->next = NULL;//A 表尾结点指针域置空
}
09 假设有两个按元素值递增次序排列的线性表,均以单链表形式存储。请编写算法将这两个单链表归并为一个按元素值递减次序排列的单链表,并要求利用原来两个单链表的结点存放归并后的单链表。
- 有序单链表归并;
- 递减—头插法—防断链;
- 这里20行将两种判断及其操作变为一种,可以少写点;
- 记得释放B的空间
- 首先定义两个遍历指针遍历两个线性表,哪个元素小哪个就头插到A表中,直到有个表没有元素了,
LinkList MergeList(LinkList& A, LinkList& B) {
LNode* p = A->next;//定义遍历指针
LNode* q = B->next;//定义遍历指针
LNode* r;//定义防断链指针
A->next = NULL;//将A作为最终合并后的单链表,使用头插法前需初始化头结点指针域
while (p != NULL && q != NULL) {//若两个表有任意一个处理完毕则停止循环
if (p->data <= q->data) {//比较当前两个链表数值最小的结点
r = p->next;//防止头插法断链
p->next = A->next;//p 遍历到的结点更小则将其头插到新表 A
A->next = p;
p = r;//更新遍历指针位置
}
else {//q 遍历到的结点更小则将其头插到新表 A
r = q->next;
q->next = A->next;
A->next = q;
q = r;
}
}
//以下将对两个判断操作合并到一步
if (q != NULL)//若 B 表未处理完则让 p 指针指向 B 表剩余所需遍历的结点
p = q; //若 A 表未处理完此行不用执行,p 已经指向 A 表需要遍历的结点
while (p != NULL) {//将剩余的结点挨个头插到新建立的 A 表
r = p->next;//防止头插法断链
p->next = A->next;//头插法核心代码
A->next = p;//头插法核心代码
p = r;//更新遍历指针位置
}
free(B);//释放 B 表头结点空间
return A;
}
10 试编写在带头结点的单链表 L 中删除一个最小值结点的高效算法(假设最小值结点是唯一的)。
- 找,删除;
- 需要四个指针,两个用来比较当前结点与前一个结点的大小,另外两个是用来存放目前最小值结点及其前一个结点
- 如果p不为空且找到目前最小的,则更改minp和minpre
- 不管是不是最小值,判断结束后pre和p指针都需要往后移动
void Del_Min(LinkList& L) {
LNode* pre = L, * p = L->next;//定义遍历指针 p 及其前驱指针 pre
LNode* minpre = pre, * minp = p;//记录所遍历过的结点中最小值结点的位置
//查找
while (p != NULL) {//遍历单链表
if (p->data < minp->data) {//判断所遍历结点是否小于之前记录的最小结点
minp = p;//若小于,则更新最小值结点位置
minpre = pre;
}
pre = p;//继续遍历
p = p->next;
}
//删除最小值
minpre->next = minp->next;//遍历结束,删除最小值结点
free(minp);//释放最小值结点空间
}
删除操作使用minpre和minp指针。
11 试编写在不带头结点的单链表 L 中删除一个最小值结点的高效算法(假设最小值结点是唯一的)。
- 注意不带头结点,删除第一个元素时会有差异;
- 初始化时pre和minpre指针不用指向
void Del_Min1(LinkList& L) {//不带头结点时 L 指向的是链表中第一个数据结点
LNode* pre, * p = L;//定义遍历指针 p 及其前驱指针 pre
LNode* minpre, * minp = p;//定义最小值记录指针 minp 及其前驱指针 minpre
while (p != NULL) {//遍历该链表
if (p->data < minp->data) {//判断遍历结点是否小于之前所记录的最小结点
minp = p;//若小于,则更新最小值结点位置
minpre = pre;
}
pre = p;//继续遍历
p = p->next;
}
//删除操作需要特殊考虑是否为第一个元素
if (minp == L) {//如果链表第一个数据结点是最小值结点需特殊考虑
L = L->next;//更新头指针位置
free(minp);//释放最小值结点空间
}
else {//如果链表最小值结点不是第一个数据结点,则直接删除
minpre->next = minp->next;//删除最小值结点
free(minp);//释放最小值结点空间
}
}
12 带不带头结点的通用做法:自己定义一个头结点,然后常规操作,最后更新头指针位置,将之前创建的头结点free掉
void Del_Min2(LinkList& L) {
LinkList head = (LinkList)malloc(sizeof(LNode));//创建头结点
head->next = L;//将原始链表链接到创建的头结点后面
LNode* pre = head, * p = head->next;//定义遍历指针 p 及其前驱指针 pre
LNode* minpre = pre, * minp = p;//定义记录最小值结点的指针 minp 及其前驱
while (p != NULL) {//遍历链表
if (p->data < minp->data) {//判断所遍历结点是否小于之前记录的最小结点
minp = p;//若小于,则更新最小值结点位置
minpre = pre;
}
pre = p;//继续遍历
p = p->next;
}
minpre->next = minp->next;//遍历结束,删除最小值结点
free(minp);//释放最小值结点空间
L = head->next;//更新头指针位置
free(head);//删除创建的头结点
}
13 在带头结点的单链表 L 中,删除所有值为 x 的结点,并释放其空间,假设值为 x 的结点不唯一,试编写算法以实现上述操作。
第一次自己写的,漏洞百出
LinkList Del_x(LinkList& L,int x) {
LNode* p = L->next;
LNode* pre = L;
while (p != NULL) {
if (p->data == x) {
pre->next = p->next;
free(p);
}
pre = p;
p = p->next;
}
}
边找边删
上面我写的代码错误主要在
①pre = p;和p = p->next;应该是else的情况,因为if中已经删除结点和更新p指针,不把它放在else中会导致p又一次指向后一个结点;
②if里面的代码可以自己模拟一下,首先需要将p结点单独拿出来,所以pre->next = p->next;然后free掉,最后的话,p变成pre的下一个结点,此时p已经发生变化,不需要进行其他代码的编写。
LinkList Del_x(LinkList& L,int x) {
LNode* p = L->next;//定义遍历指针 p 及其前驱指针 pre
LNode* pre = L;
while (p != NULL) {
if (p->data == x) {//判断遍历结点数据域是否为 x
pre->next = p->next;//删除数据域为 x 的结点
free(p);//释放被删结点的空间
p = pre->next;//遍历指针更新到下一遍历结点位置
}
else {
pre = p;//两个遍历指针顺序后移,继续遍历
p = p->next;
}
}
}
14 设在一个带头结点的单链表L中所有元素结点的数据值无序,试编写一个函数,删除单链表中所有数据域中值介于给定的两个值之间的结点。(假设给定的两个值分别为 min 和 max)
- 本题和上题几乎一样
void Del_min_max(LinkList& L, int min, int max) {
LNode* pre = L, * p = L->next;
while (p != NULL) {
if (p->data >= min && p->data <= max) {
pre->next = p->next;
free(p);
p = pre->next;
}
else {
pre = p;
p = p->next;
}
}
}
15 设有一个单链表 L,L 中结点非递减有序排列,设计一个算法删除单链表 L 中数值相同的结点,使单链表中不再有值重复的结点
- 因为需要比较,而第一个元素肯定不会和之前元素相同,这里将pre指向第一个元素,p指向第二个元素;
int Del_same(LinkList& L) {
if (L == NULL) {//代码健壮性
return -1;
}
LNode* pre = L->next;
LNode* p = pre->next;//遍历指针 p 指向第二个数据结点
while (p != NULL) {//遍历该链表
if (p->data == pre->data) {//若遍历结点与前驱结点数据值相同则证明重复
pre->next = p->next;//若重复删除 p 指针所指向的重复结点
free(p);//释放删除结点所占空间
p = pre->next;//更新遍历指针位置
}
else {//若不重复则继续遍历,指针后移
pre = p;
p = p->next;
}
}
}
}
16 设 A 和 B 是两个带头结点的单链表,其中结点值递增有序。设计一个算法从 A 和 B 中找出值相同的结点并生成一个新的单链表 C,要求不破坏 A、B 的 结点。
- 假设尾插法插入C,因此需要尾指针(尾指针最后置空);
- 不破坏A、B的结点,说明需要自己创建结点;
- else的最后两步别忘了,当我们找到相同值的结点后,A和B都得往后移一个。
- while判断:两个链表中均有元素才需要比较,其中一个没元素了,就不用比较了。
LinkList Create_C(LinkList& A, LinkList& B) {
LinkList C = (LNode*)malloc(sizeof(LNode));
LNode* p = A->next, * q = B->next;
LNode* r = C, * s;//定义 C 表尾指针 r 和创建新结点所需的辅助指针 s
while (p != NULL && q != NULL) {//说明两个单链表中还有元素,因此需要比较
if (p->data < q->data) {//若 A 表中遍历结点值更小则 p 指针后移
p = p->next;
}
else if (p->data > q->data) {//若 B 表中遍历结点值更小则 q 指针后移
q = q->next;
}
else {//寻找到值相同的结点则建立新结点尾插到 C 表
s = (LNode*)malloc(sizeof(LNode));
s->data = p->data;
s->next = NULL;
r->next = s;//将新建立的结点尾插到 C 表中
r = s;//更新尾指针位置
//这两步别忘了,两指针继续遍历寻找值相同的结点
p = p->next;
q = q->next;
}
}
r->next = NULL;//尾插结束后尾结点指针域需置空
return C;
}
17 设 A 和 B 是两个带头结点的单链表,其中结点值递增有序。请设计一个算法求单链表 A 与 B 的交集,并存放于 A 链表中,其它结点均释放其空间。
- 当删除结点时,需要辅助指针记录,否则后续结点找不到了;
- 因为要释放空间,因此一个表为空时,要去释放另外一个表的结点;
- 本题的思路是使用尾插法插入交集结点,因此需要尾指针记录链尾,每次找到不相同元素时候,需要s指针去记录位置,然后将其free,找到相同元素时,需要将A链表中的结点尾插到A中,然后将B表中的元素删除,最后剩下一个表中含有元素,将其删除,最后将尾指针域置空,删除B的头结点。
LinkList Create_same_A(LinkList& A, LinkList& B) {
LNode* p = A->next, * q = B->next;
LNode* r = A;//尾指针
LNode* s;//辅助记录被删结点
while (p != NULL && q != NULL) {
if (p->data < q->data) {//若 p 指针所指结点数值较小则释放此结点并后移 p
s = p;//s 指针记录此结点需释放空间,方便 p 指针先顺利后移
p = p->next;//p 指针顺利后移
free(s);//释放刚遍历到的数值较小结点
}
else if (p->data > q->data) {
s = q;
q = q->next;
free(s);
}
else {//寻找到两个链表的交集结点则将其中一个尾插入新 A 表
r->next = p;//将其中一个交集结点尾插到新 A 表中
r = p;
p = p->next;
s = q;//s 指针辅助删除另一个交集结点
q = q->next;//q 指针继续遍历,两指针继续比较
free(s);
}
}
//别忘了A表或B表还有剩余的情况
while (p != NULL) {//若循环结束原 A 表有剩余结点则全部删除释放空间
s = p;
p = p->next;
free(s);
}
while (q != NULL) {//若循环结束原 B 表有剩余结点则全部删除释放空间
s = q;
q = q->next;
free(s);
}
r->next = NULL;//尾插结束后尾结点指针域需置空
free(B);
return A;
}
18 有一个带头结点的单链表,其头指针为 head,试编写一个算法,按递增次序输出单链表中各结点数据域中的值,并释放所有结点所占的存储空间(要求不允许使用数组作为辅助空间)。
void Del_Min(LinkList& L) {
LNode* pre = L, * p = L->next;//定义遍历指针 p 及其前驱指针 pre
LNode* minpre = pre, * minp = p;//记录所遍历过的结点中最小值结点的位置
//查找
while (p != NULL) {//遍历单链表
if (p->data < minp->data) {//判断所遍历结点是否小于之前记录的最小结点
minp = p;//若小于,则更新最小值结点位置
minpre = pre;
}
pre = p;//继续遍历
p = p->next;
}
//删除最小值
minpre->next = minp->next;//遍历结束,删除最小值结点
free(minp);//释放最小值结点空间
}
这是之前的删除最小值的代码,和本题相似。
- 单链表无序,递增输出,先要找到最小值,然后释放;
- 本题是删除所有结点,while循环判断是否还有结点,没有结点才结束,此外初始化这些结点需要在while循环里面
void Print_min(LinkList& head) {
while (head->next != NULL) {//说明链表中还有元素
//之前写的那个寻找最小值的操作
LNode* pre = head, * p = head->next;
LNode* minpre = pre, * minp = p;
while (p != NULL) {//寻找最小值
if (p->data < pre->data) {//记录最小值
minp = p;
minpre = pre;
}
//不管上一步找到的是不是最小值,p和pre都得往后移
pre = p;
p = p->next;
}
//找到最小值了
printf("%d", minp->data);//输出此次循环找出的最小值结点数据
minpre->next = minp->next;//删除此次循环找出的最小值结点
free(minp);
}
free(head);
}
19 设有一个带头结点的循环单链表 L,其结点值均为正整数。设计一个算法,反复找出单链表中结点值19最小的结点并输出,然后将该结点从中删除,直到单链表空为止,再删除头结点。
- 本题目是对于循环单链表的,
- 判断如何退出大循环,最后结点都没了,导致L->next=L;
- 小循环,由于循环单链表,p遍历到最后会指向L头结点,因此p==L时,可以退出本次循环
void Del_loop_min(LinkList& L) {
while (L->next != L) {//先while再定义结点,循环寻找最小值,直至数据结点都被找到并输出
LNode* pre = L, * p = L->next;//定义遍历指针 p 及其前驱指针 pre
LNode* minpre = pre, * minp = p;//记录每一次循环最小值结点
while (p != L) {//建议画图体会循环链表与普通链表循环条件的区别
if (p->data < pre->data) {//遍历结点是否小于之前记录的最小结点
minp = p;
minpre = pre;
}
pre = p;//继续遍历
p = p->next;
}
printf("%d", minp->data);
minpre->next = minp->next;
free(minp);
}
free(L);//释放头结点空间
}
20 两个整数序列 A={a1,a2,a3,…,am}和 B={b1,b2,b3,…,bn}已经存入两个单链表中,设计一个算法,判断序列 B 是否是序列 A 的连续子序列。
- 朴素模式匹配
- pre指针记录此次比较开始的地方;
- 当B的q指针指向NULL时,也要跳出循环;
- 如果最后跳出循环是因为q指向NULL,说明找到了
- 每次比较时,A序列从pre开始,B序列从最开始进行比较,每次比较失败,pre指针往后移动,p从pre开始,q从B的第一个结点开始;比较结束后如果q指向NULL说明比较成功
int Pattern(LinkList A, LinkList B) {
LNode* p = A->next, * q = B->next;//定义遍历指针 p 和 q
LNode* pre = A->next;//定义辅助指针 pre,负责记录此次比较开始元素位置
while (p != NULL && q != NULL) {
if (p->data == q->data) {//若两遍历结点数据域相同则需继续遍历
p = p->next;
q = q->next;
}
else {//若两遍历结点数据域不同则证明此次比较失败
pre = pre->next;//指针 p 要借助 pre 去下一次比较的开始位置
p = pre;
q = B->next;//q 指针重新指向 B 表第一个结点开始新一次的比较
}
}
if (q == NULL)//若循环结束 q 指针指向空则证明此次比较成功,返回 1
return 1;
else//若 q 不为空则证明比较失败,返回 0
return 0;
}
21 请设计一个算法判断单链表 L 是否有环。
-
定义一个fast指针和一个slow指针,fast指针一次走两步,slow指针一次走一步,若成环,则某一时刻他们会相遇。
-
结点个数奇偶数的判断条件不同,结点数为奇数,fast可以走两步,第一步有具体结点,第二步为NULL;结点数为偶数,fast最后一次一步都走不了;因此判断条件是
fast != NULL && fast->next != NULL文章来源:https://www.toymoban.com/news/detail-683549.html[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NfBGj8cy-1693057217464)(D:\Typorafile\Typorapicture\判断环.png)]文章来源地址https://www.toymoban.com/news/detail-683549.html
int FindLoop(LinkList L) {
LNode* fast = L, * slow = L;//分别定义快慢两个遍历指针并进行初始化
while (fast != NULL && fast->next != NULL) {//分别考虑结点数奇偶可画图理解
slow = slow->next;//慢指针每次遍历走一步
fast = fast->next->next;//快指针每次遍历走两步
if (slow == fast)//若快慢两个指针指向了同一位置则证明链表 L 有环
return 1;
}
return 0;//若循环正常结束则说明链表 L 没有环
}
22 有两个不带头结点的循环单链表,链表头指针分别为 h1 和 h2,编写一个函数将链表 h2 链接到链表 h1 之后,要求链接后的链表仍能保持循环单链表形式。
- 首先找到第一个链表的尾结点,然后去寻找第二个链表的尾结点,然后链接成循环单链表即可;
- 由于是循环单链表,因此这里的while条件需要改变
LinkList Link(LinkList& h1, LinkList& h2) {
LNode* p, * q;
p = h1;
while (p->next != h1) {//循环使得 p 指针指向 h1 链表最后一个结点
p = p->next;
}
q = h2;
while (q->next != h2) {
q = q->next;
}
p->next = h2;
q->next = h1;
return h1;
}
23 设计一个算法用于判断带头结点的循环双链表 L 是否对称。
- 假设除了头结点外有奇数个结点,此时p=q说明判断可以结束了,有偶数个结点时,若为6,则p和q各移动三次,再移动一次时,p在q的左边,此时,不需要比较了,即q->next=p;
- 更简单些,假设除头结点外还有3个结点,初始时p在第一个结点,q在最后一个结点,下一次循环,p和q指向同一结点;假设除头结点外还有2个结点,初始时,p在第一个结点,q在最后一个也就是第二个结点,下一次循环,p在最后一个结点也就是第二个结点,q在第一个结点,此时q->next=p
- 这里除头结点外还有偶数个结点的情况,需要多加仔细
typedef struct DNode {//循环双链表
int data;
struct DNode* prior, * next;
}DNode, *DLinkList;
int Func(DLinkList L) {
DNode* p = L->next, * q = L->prior;//两遍历指针以头结点为中心分别遍历两侧
while (p != q && q->next != p) {//需考虑结点是奇数还是偶数,强烈建议画图推理
if (p->data == q->data) {//若两遍历结点数据域相同则需继续遍历
p = p->next;
q = q->prior;
}
else//若两遍历结点数据域不同则证明循环双链表不对称,直接返回 0
return 0;
}
return 1;//若正常跳出循环则证明遍历结点数据域均相同,循环双链表对称
}
- 更简单些,假设除头结点外还有3个结点,初始时p在第一个结点,q在最后一个结点,下一次循环,p和q指向同一结点;假设除头结点外还有2个结点,初始时,p在第一个结点,q在最后一个也就是第二个结点,下一次循环,p在最后一个结点也就是第二个结点,q在第一个结点,此时q->next=p
- 这里除头结点外还有偶数个结点的情况,需要多加仔细
typedef struct DNode {//循环双链表
int data;
struct DNode* prior, * next;
}DNode, *DLinkList;
int Func(DLinkList L) {
DNode* p = L->next, * q = L->prior;//两遍历指针以头结点为中心分别遍历两侧
while (p != q && q->next != p) {//需考虑结点是奇数还是偶数,强烈建议画图推理
if (p->data == q->data) {//若两遍历结点数据域相同则需继续遍历
p = p->next;
q = q->prior;
}
else//若两遍历结点数据域不同则证明循环双链表不对称,直接返回 0
return 0;
}
return 1;//若正常跳出循环则证明遍历结点数据域均相同,循环双链表对称
}
到了这里,关于数据结构例题代码及其讲解-链表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!