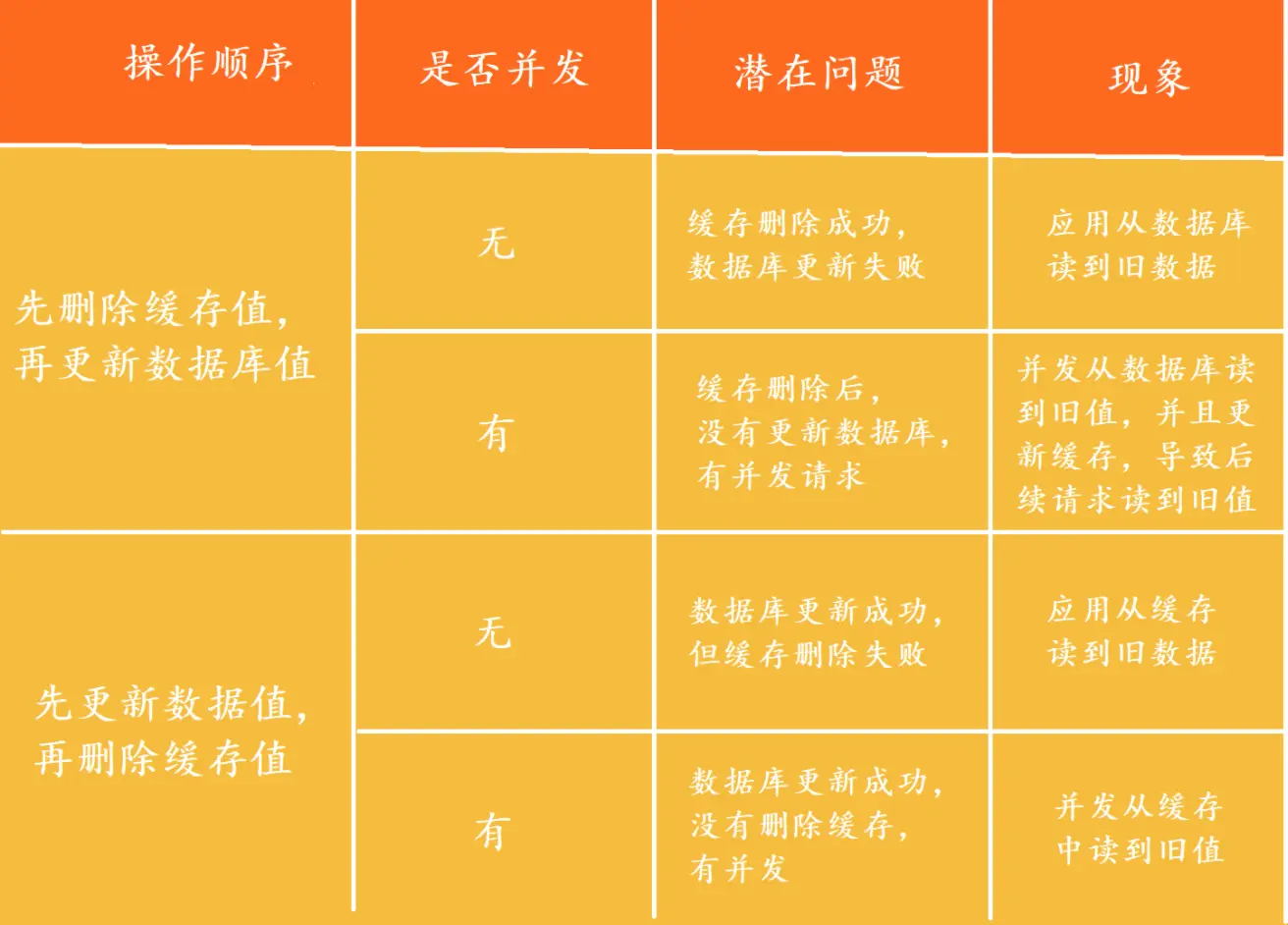
目录
基本介绍
使用例子
管道对比
管道与原生批量命令对比
管道与事务对比
使用pipeline注意事项
基准测试
基本介绍
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务器。
这意味着请求通常按如下步骤处理:
- 客户端发送一个请求到服务器,并以阻塞的方式从socket读取数据,获取服务端响应 。
- 服务端处理请求命令并发送响应回给客户端。
以上两步称为:Round Trip Time(简称
RTT,数据包往返于两端的时间)。

管道主要解决的就是redis频繁命令往返造成的性能瓶颈
Clients 和 Servers 通过网络连接. 可以是本地非常快的网络,或者是通过互联网连接很远的网络。不管网络延迟如何,数据包从客户端发给服务端,再从服务端返回给客户端都要花费一个时间。
这个时间叫做 RTT (Round Trip Time往返时间). 所以如果客户端需要连续发送多个请求的情况下,RTT对性能的影响是很严重的。例如在延迟很大的网络中RRT是250ms,即使服务端每秒能处理10万个请求,我们也只能每秒最多处理四个请求。
解决思路
管道(pipeline)可以一次性发送多条命令给服务端,服务端一次处理完毕后,通过一条响应一次性将结果返回,通过减少客户端与redis的通信次数来实现降低往返延时时间。pipeline实现的原理是队列,先进先出特性是保证数据的顺序性
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
使用例子

将指令写在cmd.txt文件中,然后发生给redis客户端。
Redis 很早就开始支持 pipelining , 所以不管什么版本的Redis都能使用 pipelining 命令。下面是使用netcat命令的例子:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG特别注意: 当客户端使用管道 pipelining发送命令时,服务器端需要消耗内存来存放响应,所以如果你需要发送大量的命令,最好分批发送,例如一次发送1万个,读取回报,再循环发剩余的命令。速度上几乎无差异,但是内存最大消耗1万个命令回复结果的内存。
管道对比
管道与原生批量命令对比
- 原生批量命令是原子性的,例如:mget、mset。pipeline是非原子性的
- 原生批量命令一次只能执行一种命令,但是pipeline支持一次执行多中命令。
- 原生批量命令是服务端实现的,而pipeline需要服务端与客户端共同完成。
管道与事务对比
- 事务里面的命令是在服务端缓存,当发出exec命令的时候,服务端就会判断并执行事务命令。
- 管道里面的命令是在客户端缓存,当客户端结束管道后一次发送到服务端,服务端读取后按照先后顺序先后执行。所以事务的命令是一条一条发的,而管道的是一次性发送到服务端的。执行事务时会阻塞其他命令的执行,而执行管道中的命令时不会。
- 事务中出现语法错误会导致事务不被执行,而管道出现语法错误,依然会执行其他命令。
使用pipeline注意事项
pipeline缓冲的命令只是会依次执行,不保证原子性,如果执行过程中发生异常,将会继续执行后续的命令。
使用pipeline组装的命令个数不能太多,不然数据量过大,客户端阻塞的时间可能过久,同时服务端此时也被迫恢复一个队列答复,占用很多内存。
基准测试
下面使用的是Redis Ruby客户端,来测试 pipelining 对速度的提升:
require 'rubygems'
require 'redis'
def bench(descr)
start = Time.now
yield
puts "#{descr} #{Time.now-start} seconds"
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench("without pipelining") {
without_pipelining
}
bench("with pipelining") {
with_pipelining
}
在mac上执行上面的脚本得到如下输出,因为是本机访问,提升并不明显,本机环境下RTT已经很小:文章来源:https://www.toymoban.com/news/detail-683738.html
不用pipelining 1.185238 seconds
使用 pipelining 0.250783 seconds
使用pipelining,我们能大概提高5倍速度。文章来源地址https://www.toymoban.com/news/detail-683738.html
到了这里,关于Redis之管道解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!