深度学习论文: Segment Any Anomaly without Training via Hybrid Prompt Regularization
Segment Any Anomaly without Training via Hybrid Prompt Regularization
PDF: https://arxiv.org/pdf/2305.10724.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
动机: 提出了一种新的框架,即Segment Any Anomaly + (SAA+),用于零样本异常分割,并通过混合提示正则化方法改善现代基础模型的适应性。现有的异常分割模型通常依赖于特定领域的微调,限制了它们在无数异常模式之间的泛化能力。
方法: 将不同的基础模型进行协同组装,以利用多模态先验知识来进行异常定位。为了适应非参数基础模型在异常分割中的应用,进一步引入了从领域专家知识和目标图像上下文中派生的混合提示作为正则化手段。
优势: 所提出的SAA+模型在多个异常分割基准测试数据集(包括VisA、MVTec-AD、MTD和KSDD2)中在零样本设置下实现了最先进的性能,克服了现有模型在异常模式泛化方面的局限性,并且能够检测与纹理相关的异常而无需任何标注。

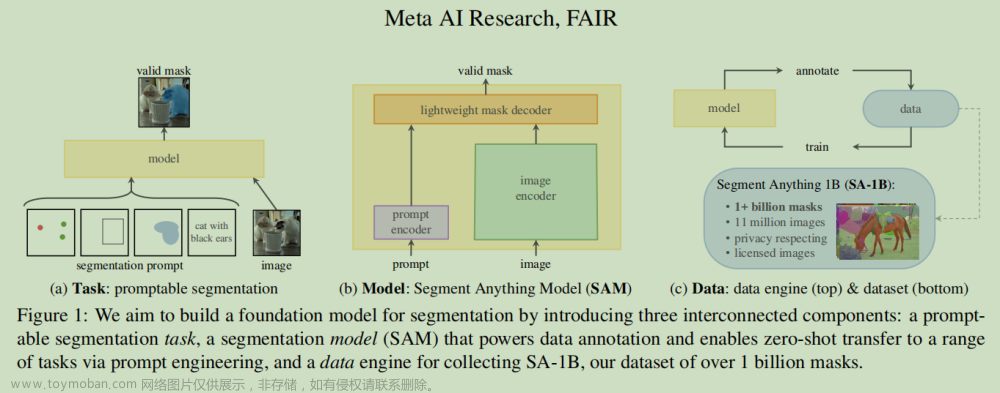
2 SAA: Vanilla Foundation Model Assembly for ZSAS
针对用于异常分割的某个查询图像,我们首先使用语言提示作为初始输入,在基于语言驱动的视觉定位基础模型(如GroundingDINO)的支持下,通过异常区域生成器大致检索出粗糙的异常区域提议。然后,通过使用基于提示驱动的分割基础模型(如SAM)的异常区域细化器,将这些提议进一步细化为像素级别的高质量分割掩码。这种方法结合了语言和视觉信息,能够在异常分割任务中提供更准确的结果。
2-1 Anomaly Region Generator
最近,随着语言-视觉模型的快速发展,一些基础模型逐渐具备了通过语言提示在图像中检测对象的能力。例如,给定一个描述所需检测区域的语言提示,基础模型可以为查询图像生成相应的区域。为了实现这一目标,我们采用了一种基于文本引导的开放集目标检测架构,即GroundingDINO,该架构已经在大规模的语言-视觉数据集上进行了预训练。具体而言,该网络通过文本编码器和视觉编码器提取语言提示和查询图像的特征,并利用跨模态解码器以边界框的形式生成粗略的对象区域。通过使用边界框级别的区域集合和对应的置信度得分集合,我们可以定义异常区域生成器(Generator)模块:
2-2 Anomaly Region Refiner
为了生成像素级别的异常分割结果,我们提出了异常区域细化器,将边界框级别的异常区域候选者细化为异常分割掩码集合。为了实现这一目标,我们使用了一种用于开放世界视觉分割的复杂基础模型,即SAM。该模型主要由基于ViT的主干网络和一个受提示条件控制的分割解码器组成。具体而言,该模型在一个包含十亿个细粒度掩码的大规模图像分割数据集上进行了训练,从而在开放集分割设置下具备了高质量的掩码生成能力。受提示条件控制的分割解码器接受各种类型的提示作为输入。我们将边界框候选集视为提示,并生成像素级别的分割掩码。异常区域细化器模块可以被定义为
到目前为止,我们得到了一组以高质量分割掩码的形式表示的区域R,以及对应的置信度得分S。综上所述,我们将框架(SAA)总结如下
其中
T
n
T_{n}
Tn 是一个类别无关的语言提示,例如 SAA中使用的“anomaly”。
3 SAA+: Foundation Model Adaption via Hybrid Prompt Regularization
为了解决SAA中的语言歧义问题并提高其在零样本异常检测上的能力,我们提出了升级版的SAA+。SAA+不仅利用了预训练模型所获得的知识,还结合了领域专家的知识和目标图像的上下文信息,以生成更准确的异常区域掩码。通过引入混合提示的方法,SAA+能够更好地处理语言的多义性,从而提高了模型的性能。
3-1 Prompt Generated from Domain Expert Knowledge
SAA+利用了专家知识生成更准确的异常区域掩码,包括异常语言提示(Anomaly Language Expression)和异常属性提示(Anomaly Object Property)。对于异常语言提示(Anomaly Language Expression),SAA+通过使用类别无关(Class-agnostic prompts )和类别特定的提示(Class-specific prompts)来进一步细化"异常"这一提示。而对于异常属性提示(Anomaly Object Property),SAA+考虑了异常的位置(Anomaly Location)和面积信息(Anomaly Area)。通过结合这两种多模态提示,SAA+在异常分割任务中能够获得更精确的结果。这种综合利用领域专家知识和多模态提示解决语言歧义问题的方法,使得SAA+在异常区域掩码生成方面具有更高的准确性和鲁棒性。
3-2 Prompts Derived from Target Image Context
利用从目标图像上下文中衍生的多模态提示来提高异常区域检测准确性的方法。其中,异常显著性提示(Anomaly Saliency Prompt)通过使用显著性图来校准基础模型的置信度分数,从而提高异常区域的检测效果。而异常置信度提示(Anomaly Confidence Prompt)则通过选择具有最高置信度的候选区域来确定最终的异常区域检测结果。通过综合利用这两种多模态提示,可以提高异常区域检测的准确性和可靠性。这种方法能够更好地利用目标图像的上下文信息,从而提高异常区域检测的性能。文章来源:https://www.toymoban.com/news/detail-683917.html
4 Experiments
 文章来源地址https://www.toymoban.com/news/detail-683917.html
文章来源地址https://www.toymoban.com/news/detail-683917.html
到了这里,关于深度学习论文: Segment Any Anomaly without Training via Hybrid Prompt Regularization的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!