今天在查资料的时候无意间看到了一个很有意思的工具,就是CodeFormer ,作者给出来的说明是用于人脸修复任务的,觉得很有意思就拿来实践了一下,这里记录分享一下。
首先对人脸修复任务进行简单的回顾总结:
人脸修复是指对损坏、有缺陷或者遮挡的人脸图像进行恢复、修复或重建的过程。这涉及到图像处理、计算机视觉和机器学习等领域的技术。
人脸修复可以应用于多个场景,例如:
-
人脸去除遮挡:当人脸图像被遮挡或者被其他对象遮挡时,人脸修复可以通过推断遮挡区域的内容进行修复。这可以包括使用图像修复算法(如基于纹理填充、基于复制粘贴的方法)或者利用人脸识别和人脸重建技术进行修复。
-
人脸恢复和重建:当人脸图像受到严重损坏或者缺陷时,通过人脸修复技术可以进行图像的恢复和重建。这可以包括利用图像补全算法、人脸超分辨率重建、人脸合成等技术来重建完整的人脸图像。
-
人脸修复和美化:人脸修复还可以包括对人脸图像的美化和修饰。这可以包括去除皱纹、瑕疵、眼袋等改善面部外貌的操作,以及改变皮肤色调、增强对比度等优化图像质量的操作。
在人脸修复领域,常用的算法模型包括以下几种:
-
自编码器(Autoencoder):自编码器是一种无监督学习方法,将输入数据压缩为低维编码,然后再将编码恢复为原始数据。在人脸修复中,自编码器可以用于重建缺失或损坏的人脸部分。
-
卷积神经网络(Convolutional Neural Network, CNN):CNN是一种深度学习模型,广泛用于图像处理任务。在人脸修复中,CNN可以用于将损坏的人脸图像与完整的人脸图像进行对齐,从而进行修复。
-
生成对抗网络(Generative Adversarial Network, GAN):GAN由生成器和判别器组成,通过对抗学习的方式,生成逼真的以假乱真的图像。在人脸修复中,GAN可以用于生成缺失或损坏的人脸部分。
-
基于纹理填充的方法:基于纹理填充的方法使用纹理合成和纹理迁移技术,将周围的纹理信息应用于损坏区域,来修复人脸图像。
-
结构生成模型:结构生成模型基于人脸的结构信息,如关键点或网格,通过形状优化和插值方法,实现对人脸的修复和重建。
除了上述算法模型,还有一些其他的变种和组合方法,如图像修补算法、超分辨率重建算法、形状恢复算法等。这些算法模型都在不同场景下有其适用性和局限性,具体选择哪种模型需要根据具体任务和需求来进行权衡和选择。
接下来回归正题,来看本文要介绍学习的CodeFormer。
作者项目在这里,如下所示:
盲脸恢复是一个高度不适定的问题,通常需要辅助指导来
1)改进从退化输入到期望输出的映射,或
2)补充输入中丢失的高质量细节。
在本文中,我们证明了在小代理空间中学习的离散码本先验通过将人脸恢复作为代码预测任务,大大降低了恢复映射的不确定性和模糊性,同时为生成高质量人脸提供了丰富的视觉原子。在这种范式下,我们提出了一种基于Transformer的预测网络,名为CodeFormer,用于对低质量人脸的全局组成和上下文进行建模,以进行代码预测,即使在输入严重退化的情况下,也能够发现与目标人脸非常接近的自然人脸。为了增强对不同退化的适应性,我们还提出了一个可控的特征转换模块,该模块允许在保真度和质量之间进行灵活的权衡。得益于富有表现力的码本先验和全局建模,CodeFormer在质量和保真度方面都优于现有技术,对退化表现出卓越的鲁棒性。在合成和真实世界数据集上的大量实验结果验证了我们方法的有效性。
文章的核心方法:
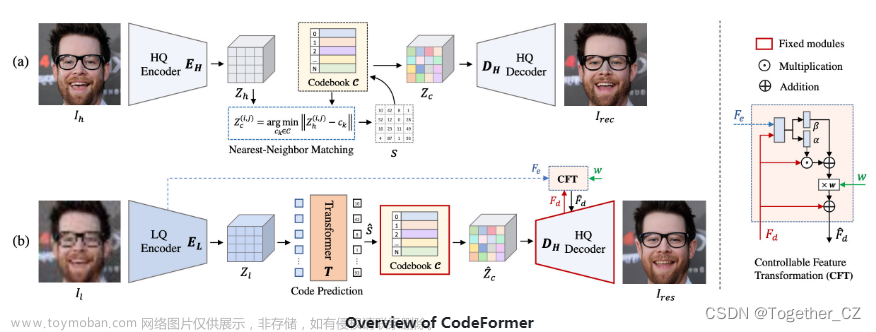
(a) 我们首先通过自重构学习学习离散码本和解码器来存储人脸图像的高质量视觉部分。
(b) 在固定码本和解码器的情况下,我们引入了一个用于代码序列预测的Transformer模块,对低质量输入的全局人脸组成进行建模。此外,使用可控特征变换模块来控制从LQ编码器到解码器的信息流。请注意,此连接是可选的,当输入严重降级时,可以禁用此连接以避免不利影响,并且可以调整标量权重w以在质量和保真度之间进行权衡。
实例结果:
官方项目地址在这里,如下所示:
目前已经有将近1w的star量了,看来还是蛮受欢迎的。
官方的论文地址在这里,如下所示:



感兴趣的话可以自行下载研读一下,这里我主要是想实际试用一下。
下载官方项目,本地解压缩如下所示:
这里提供了可以直接使用的人脸修复推理模块,如下所示:
import os
import cv2
import argparse
import glob
import torch
from torchvision.transforms.functional import normalize
from basicsr.utils import imwrite, img2tensor, tensor2img
from basicsr.utils.download_util import load_file_from_url
from basicsr.utils.misc import gpu_is_available, get_device
from facelib.utils.face_restoration_helper import FaceRestoreHelper
from facelib.utils.misc import is_gray
from basicsr.utils.registry import ARCH_REGISTRY
pretrain_model_url = {
'restoration': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
}
def set_realesrgan():
from basicsr.archs.rrdbnet_arch import RRDBNet
from basicsr.utils.realesrgan_utils import RealESRGANer
use_half = False
if torch.cuda.is_available(): # set False in CPU/MPS mode
no_half_gpu_list = ['1650', '1660'] # set False for GPUs that don't support f16
if not True in [gpu in torch.cuda.get_device_name(0) for gpu in no_half_gpu_list]:
use_half = True
model = RRDBNet(
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_block=23,
num_grow_ch=32,
scale=2,
)
upsampler = RealESRGANer(
scale=2,
model_path="https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/RealESRGAN_x2plus.pth",
model=model,
tile=args.bg_tile,
tile_pad=40,
pre_pad=0,
half=use_half
)
if not gpu_is_available(): # CPU
import warnings
warnings.warn('Running on CPU now! Make sure your PyTorch version matches your CUDA.'
'The unoptimized RealESRGAN is slow on CPU. '
'If you want to disable it, please remove `--bg_upsampler` and `--face_upsample` in command.',
category=RuntimeWarning)
return upsampler
if __name__ == '__main__':
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = get_device()
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--input_path', type=str, default='./inputs/whole_imgs',
help='Input image, video or folder. Default: inputs/whole_imgs')
parser.add_argument('-o', '--output_path', type=str, default=None,
help='Output folder. Default: results/<input_name>_<w>')
parser.add_argument('-w', '--fidelity_weight', type=float, default=0.5,
help='Balance the quality and fidelity. Default: 0.5')
parser.add_argument('-s', '--upscale', type=int, default=2,
help='The final upsampling scale of the image. Default: 2')
parser.add_argument('--has_aligned', action='store_true', help='Input are cropped and aligned faces. Default: False')
parser.add_argument('--only_center_face', action='store_true', help='Only restore the center face. Default: False')
parser.add_argument('--draw_box', action='store_true', help='Draw the bounding box for the detected faces. Default: False')
# large det_model: 'YOLOv5l', 'retinaface_resnet50'
# small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
parser.add_argument('--detection_model', type=str, default='retinaface_resnet50',
help='Face detector. Optional: retinaface_resnet50, retinaface_mobile0.25, YOLOv5l, YOLOv5n, dlib. \
Default: retinaface_resnet50')
parser.add_argument('--bg_upsampler', type=str, default='None', help='Background upsampler. Optional: realesrgan')
parser.add_argument('--face_upsample', action='store_true', help='Face upsampler after enhancement. Default: False')
parser.add_argument('--bg_tile', type=int, default=400, help='Tile size for background sampler. Default: 400')
parser.add_argument('--suffix', type=str, default=None, help='Suffix of the restored faces. Default: None')
parser.add_argument('--save_video_fps', type=float, default=None, help='Frame rate for saving video. Default: None')
args = parser.parse_args()
# ------------------------ input & output ------------------------
w = args.fidelity_weight
input_video = False
if args.input_path.endswith(('jpg', 'jpeg', 'png', 'JPG', 'JPEG', 'PNG')): # input single img path
input_img_list = [args.input_path]
result_root = f'results/test_img_{w}'
elif args.input_path.endswith(('mp4', 'mov', 'avi', 'MP4', 'MOV', 'AVI')): # input video path
from basicsr.utils.video_util import VideoReader, VideoWriter
input_img_list = []
vidreader = VideoReader(args.input_path)
image = vidreader.get_frame()
while image is not None:
input_img_list.append(image)
image = vidreader.get_frame()
audio = vidreader.get_audio()
fps = vidreader.get_fps() if args.save_video_fps is None else args.save_video_fps
video_name = os.path.basename(args.input_path)[:-4]
result_root = f'results/{video_name}_{w}'
input_video = True
vidreader.close()
else: # input img folder
if args.input_path.endswith('/'): # solve when path ends with /
args.input_path = args.input_path[:-1]
# scan all the jpg and png images
input_img_list = sorted(glob.glob(os.path.join(args.input_path, '*.[jpJP][pnPN]*[gG]')))
result_root = f'results/{os.path.basename(args.input_path)}_{w}'
if not args.output_path is None: # set output path
result_root = args.output_path
test_img_num = len(input_img_list)
if test_img_num == 0:
raise FileNotFoundError('No input image/video is found...\n'
'\tNote that --input_path for video should end with .mp4|.mov|.avi')
# ------------------ set up background upsampler ------------------
if args.bg_upsampler == 'realesrgan':
bg_upsampler = set_realesrgan()
else:
bg_upsampler = None
# ------------------ set up face upsampler ------------------
if args.face_upsample:
if bg_upsampler is not None:
face_upsampler = bg_upsampler
else:
face_upsampler = set_realesrgan()
else:
face_upsampler = None
# ------------------ set up CodeFormer restorer -------------------
net = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9,
connect_list=['32', '64', '128', '256']).to(device)
# ckpt_path = 'weights/CodeFormer/codeformer.pth'
ckpt_path = load_file_from_url(url=pretrain_model_url['restoration'],
model_dir='weights/CodeFormer', progress=True, file_name=None)
checkpoint = torch.load(ckpt_path)['params_ema']
net.load_state_dict(checkpoint)
net.eval()
# ------------------ set up FaceRestoreHelper -------------------
# large det_model: 'YOLOv5l', 'retinaface_resnet50'
# small det_model: 'YOLOv5n', 'retinaface_mobile0.25'
if not args.has_aligned:
print(f'Face detection model: {args.detection_model}')
if bg_upsampler is not None:
print(f'Background upsampling: True, Face upsampling: {args.face_upsample}')
else:
print(f'Background upsampling: False, Face upsampling: {args.face_upsample}')
face_helper = FaceRestoreHelper(
args.upscale,
face_size=512,
crop_ratio=(1, 1),
det_model = args.detection_model,
save_ext='png',
use_parse=True,
device=device)
# -------------------- start to processing ---------------------
for i, img_path in enumerate(input_img_list):
# clean all the intermediate results to process the next image
face_helper.clean_all()
if isinstance(img_path, str):
img_name = os.path.basename(img_path)
basename, ext = os.path.splitext(img_name)
print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
else: # for video processing
basename = str(i).zfill(6)
img_name = f'{video_name}_{basename}' if input_video else basename
print(f'[{i+1}/{test_img_num}] Processing: {img_name}')
img = img_path
if args.has_aligned:
# the input faces are already cropped and aligned
img = cv2.resize(img, (512, 512), interpolation=cv2.INTER_LINEAR)
face_helper.is_gray = is_gray(img, threshold=10)
if face_helper.is_gray:
print('Grayscale input: True')
face_helper.cropped_faces = [img]
else:
face_helper.read_image(img)
# get face landmarks for each face
num_det_faces = face_helper.get_face_landmarks_5(
only_center_face=args.only_center_face, resize=640, eye_dist_threshold=5)
print(f'\tdetect {num_det_faces} faces')
# align and warp each face
face_helper.align_warp_face()
# face restoration for each cropped face
for idx, cropped_face in enumerate(face_helper.cropped_faces):
# prepare data
cropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)
normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
try:
with torch.no_grad():
output = net(cropped_face_t, w=w, adain=True)[0]
restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
del output
torch.cuda.empty_cache()
except Exception as error:
print(f'\tFailed inference for CodeFormer: {error}')
restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
restored_face = restored_face.astype('uint8')
face_helper.add_restored_face(restored_face, cropped_face)
# paste_back
if not args.has_aligned:
# upsample the background
if bg_upsampler is not None:
# Now only support RealESRGAN for upsampling background
bg_img = bg_upsampler.enhance(img, outscale=args.upscale)[0]
else:
bg_img = None
face_helper.get_inverse_affine(None)
# paste each restored face to the input image
if args.face_upsample and face_upsampler is not None:
restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box, face_upsampler=face_upsampler)
else:
restored_img = face_helper.paste_faces_to_input_image(upsample_img=bg_img, draw_box=args.draw_box)
# save faces
for idx, (cropped_face, restored_face) in enumerate(zip(face_helper.cropped_faces, face_helper.restored_faces)):
# save cropped face
if not args.has_aligned:
save_crop_path = os.path.join(result_root, 'cropped_faces', f'{basename}_{idx:02d}.png')
imwrite(cropped_face, save_crop_path)
# save restored face
if args.has_aligned:
save_face_name = f'{basename}.png'
else:
save_face_name = f'{basename}_{idx:02d}.png'
if args.suffix is not None:
save_face_name = f'{save_face_name[:-4]}_{args.suffix}.png'
save_restore_path = os.path.join(result_root, 'restored_faces', save_face_name)
imwrite(restored_face, save_restore_path)
# save restored img
if not args.has_aligned and restored_img is not None:
if args.suffix is not None:
basename = f'{basename}_{args.suffix}'
save_restore_path = os.path.join(result_root, 'final_results', f'{basename}.png')
imwrite(restored_img, save_restore_path)
# save enhanced video
if input_video:
print('Video Saving...')
# load images
video_frames = []
img_list = sorted(glob.glob(os.path.join(result_root, 'final_results', '*.[jp][pn]g')))
for img_path in img_list:
img = cv2.imread(img_path)
video_frames.append(img)
# write images to video
height, width = video_frames[0].shape[:2]
if args.suffix is not None:
video_name = f'{video_name}_{args.suffix}.png'
save_restore_path = os.path.join(result_root, f'{video_name}.mp4')
vidwriter = VideoWriter(save_restore_path, height, width, fps, audio)
for f in video_frames:
vidwriter.write_frame(f)
vidwriter.close()
print(f'\nAll results are saved in {result_root}')
test.jpg是我自己网上下载的测试图片,终端执行下面的命令:
python inference_codeformer.py -w 0.5 --has_aligned --input_path test.jpg原图如下:

结果图片如下所示:

感觉有点变形了,不知道是不是图像的问题。
接下来看下灰度图的效果,原图如下所示:

结果图片如下所示:

感觉变高清了很多很多,我以为会变成彩色的,结果并没有。
接下来看下画笔涂抹严重的脸能修复成什么样,终端执行:
python inference_inpainting.py --input_path test.jpg原图如下所示:

结果图片如下所示:

图像输入:

修复输出:

看起来效果还不错。
当然了,CodeFormer也可以实现对面部上色,终端执行:
python inference_colorization.py --input_path test.jpg结果对比显示如下所示:


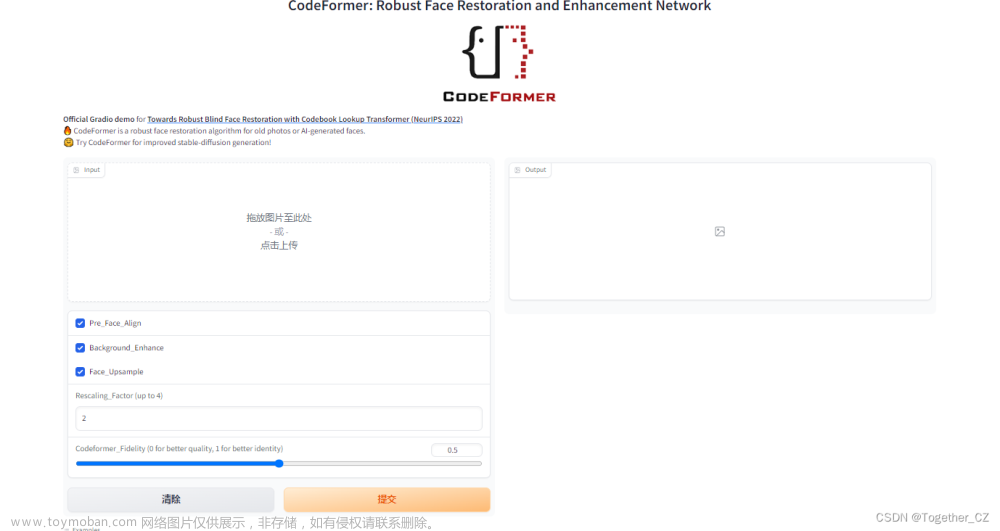
当然了,如果不喜欢终端命令行的形式,官方同样提供了基于Gradio模块开发的APP,如下所示:
"""
This file is used for deploying hugging face demo:
https://huggingface.co/spaces/sczhou/CodeFormer
"""
import sys
sys.path.append('CodeFormer')
import os
import cv2
import torch
import torch.nn.functional as F
import gradio as gr
from torchvision.transforms.functional import normalize
from basicsr.archs.rrdbnet_arch import RRDBNet
from basicsr.utils import imwrite, img2tensor, tensor2img
from basicsr.utils.download_util import load_file_from_url
from basicsr.utils.misc import gpu_is_available, get_device
from basicsr.utils.realesrgan_utils import RealESRGANer
from basicsr.utils.registry import ARCH_REGISTRY
from facelib.utils.face_restoration_helper import FaceRestoreHelper
from facelib.utils.misc import is_gray
os.system("pip freeze")
pretrain_model_url = {
'codeformer': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
'detection': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/detection_Resnet50_Final.pth',
'parsing': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/parsing_parsenet.pth',
'realesrgan': 'https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/RealESRGAN_x2plus.pth'
}
# download weights
if not os.path.exists('CodeFormer/weights/CodeFormer/codeformer.pth'):
load_file_from_url(url=pretrain_model_url['codeformer'], model_dir='CodeFormer/weights/CodeFormer', progress=True, file_name=None)
if not os.path.exists('CodeFormer/weights/facelib/detection_Resnet50_Final.pth'):
load_file_from_url(url=pretrain_model_url['detection'], model_dir='CodeFormer/weights/facelib', progress=True, file_name=None)
if not os.path.exists('CodeFormer/weights/facelib/parsing_parsenet.pth'):
load_file_from_url(url=pretrain_model_url['parsing'], model_dir='CodeFormer/weights/facelib', progress=True, file_name=None)
if not os.path.exists('CodeFormer/weights/realesrgan/RealESRGAN_x2plus.pth'):
load_file_from_url(url=pretrain_model_url['realesrgan'], model_dir='CodeFormer/weights/realesrgan', progress=True, file_name=None)
# download images
torch.hub.download_url_to_file(
'https://replicate.com/api/models/sczhou/codeformer/files/fa3fe3d1-76b0-4ca8-ac0d-0a925cb0ff54/06.png',
'01.png')
torch.hub.download_url_to_file(
'https://replicate.com/api/models/sczhou/codeformer/files/a1daba8e-af14-4b00-86a4-69cec9619b53/04.jpg',
'02.jpg')
torch.hub.download_url_to_file(
'https://replicate.com/api/models/sczhou/codeformer/files/542d64f9-1712-4de7-85f7-3863009a7c3d/03.jpg',
'03.jpg')
torch.hub.download_url_to_file(
'https://replicate.com/api/models/sczhou/codeformer/files/a11098b0-a18a-4c02-a19a-9a7045d68426/010.jpg',
'04.jpg')
torch.hub.download_url_to_file(
'https://replicate.com/api/models/sczhou/codeformer/files/7cf19c2c-e0cf-4712-9af8-cf5bdbb8d0ee/012.jpg',
'05.jpg')
def imread(img_path):
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
# set enhancer with RealESRGAN
def set_realesrgan():
# half = True if torch.cuda.is_available() else False
half = True if gpu_is_available() else False
model = RRDBNet(
num_in_ch=3,
num_out_ch=3,
num_feat=64,
num_block=23,
num_grow_ch=32,
scale=2,
)
upsampler = RealESRGANer(
scale=2,
model_path="CodeFormer/weights/realesrgan/RealESRGAN_x2plus.pth",
model=model,
tile=400,
tile_pad=40,
pre_pad=0,
half=half,
)
return upsampler
upsampler = set_realesrgan()
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = get_device()
codeformer_net = ARCH_REGISTRY.get("CodeFormer")(
dim_embd=512,
codebook_size=1024,
n_head=8,
n_layers=9,
connect_list=["32", "64", "128", "256"],
).to(device)
ckpt_path = "CodeFormer/weights/CodeFormer/codeformer.pth"
checkpoint = torch.load(ckpt_path)["params_ema"]
codeformer_net.load_state_dict(checkpoint)
codeformer_net.eval()
os.makedirs('output', exist_ok=True)
def inference(image, background_enhance, face_upsample, upscale, codeformer_fidelity):
"""Run a single prediction on the model"""
try: # global try
# take the default setting for the demo
has_aligned = False
only_center_face = False
draw_box = False
detection_model = "retinaface_resnet50"
print('Inp:', image, background_enhance, face_upsample, upscale, codeformer_fidelity)
img = cv2.imread(str(image), cv2.IMREAD_COLOR)
print('\timage size:', img.shape)
upscale = int(upscale) # convert type to int
if upscale > 4: # avoid memory exceeded due to too large upscale
upscale = 4
if upscale > 2 and max(img.shape[:2])>1000: # avoid memory exceeded due to too large img resolution
upscale = 2
if max(img.shape[:2]) > 1500: # avoid memory exceeded due to too large img resolution
upscale = 1
background_enhance = False
face_upsample = False
face_helper = FaceRestoreHelper(
upscale,
face_size=512,
crop_ratio=(1, 1),
det_model=detection_model,
save_ext="png",
use_parse=True,
device=device,
)
bg_upsampler = upsampler if background_enhance else None
face_upsampler = upsampler if face_upsample else None
if has_aligned:
# the input faces are already cropped and aligned
img = cv2.resize(img, (512, 512), interpolation=cv2.INTER_LINEAR)
face_helper.is_gray = is_gray(img, threshold=5)
if face_helper.is_gray:
print('\tgrayscale input: True')
face_helper.cropped_faces = [img]
else:
face_helper.read_image(img)
# get face landmarks for each face
num_det_faces = face_helper.get_face_landmarks_5(
only_center_face=only_center_face, resize=640, eye_dist_threshold=5
)
print(f'\tdetect {num_det_faces} faces')
# align and warp each face
face_helper.align_warp_face()
# face restoration for each cropped face
for idx, cropped_face in enumerate(face_helper.cropped_faces):
# prepare data
cropped_face_t = img2tensor(
cropped_face / 255.0, bgr2rgb=True, float32=True
)
normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
try:
with torch.no_grad():
output = codeformer_net(
cropped_face_t, w=codeformer_fidelity, adain=True
)[0]
restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
del output
torch.cuda.empty_cache()
except RuntimeError as error:
print(f"Failed inference for CodeFormer: {error}")
restored_face = tensor2img(
cropped_face_t, rgb2bgr=True, min_max=(-1, 1)
)
restored_face = restored_face.astype("uint8")
face_helper.add_restored_face(restored_face)
# paste_back
if not has_aligned:
# upsample the background
if bg_upsampler is not None:
# Now only support RealESRGAN for upsampling background
bg_img = bg_upsampler.enhance(img, outscale=upscale)[0]
else:
bg_img = None
face_helper.get_inverse_affine(None)
# paste each restored face to the input image
if face_upsample and face_upsampler is not None:
restored_img = face_helper.paste_faces_to_input_image(
upsample_img=bg_img,
draw_box=draw_box,
face_upsampler=face_upsampler,
)
else:
restored_img = face_helper.paste_faces_to_input_image(
upsample_img=bg_img, draw_box=draw_box
)
# save restored img
save_path = f'output/out.png'
imwrite(restored_img, str(save_path))
restored_img = cv2.cvtColor(restored_img, cv2.COLOR_BGR2RGB)
return restored_img, save_path
except Exception as error:
print('Global exception', error)
return None, None
title = "CodeFormer: Robust Face Restoration and Enhancement Network"
description = r"""<center><img src='https://user-images.githubusercontent.com/14334509/189166076-94bb2cac-4f4e-40fb-a69f-66709e3d98f5.png' alt='CodeFormer logo'></center>
<b>Official Gradio demo</b> for <a href='https://github.com/sczhou/CodeFormer' target='_blank'><b>Towards Robust Blind Face Restoration with Codebook Lookup Transformer (NeurIPS 2022)</b></a>.<br>
🔥 CodeFormer is a robust face restoration algorithm for old photos or AI-generated faces.<br>
🤗 Try CodeFormer for improved stable-diffusion generation!<br>
"""
article = r"""
If CodeFormer is helpful, please help to ⭐ the <a href='https://github.com/sczhou/CodeFormer' target='_blank'>Github Repo</a>. Thanks!
[](https://github.com/sczhou/CodeFormer)
---
📝 **Citation**
If our work is useful for your research, please consider citing:
```bibtex
@inproceedings{zhou2022codeformer,
author = {Zhou, Shangchen and Chan, Kelvin C.K. and Li, Chongyi and Loy, Chen Change},
title = {Towards Robust Blind Face Restoration with Codebook Lookup TransFormer},
booktitle = {NeurIPS},
year = {2022}
}
```
📋 **License**
This project is licensed under <a rel="license" href="https://github.com/sczhou/CodeFormer/blob/master/LICENSE">S-Lab License 1.0</a>.
Redistribution and use for non-commercial purposes should follow this license.
📧 **Contact**
If you have any questions, please feel free to reach me out at <b>shangchenzhou@gmail.com</b>.
<div>
🤗 Find Me:
<a href="https://twitter.com/ShangchenZhou"><img style="margin-top:0.5em; margin-bottom:0.5em" src="https://img.shields.io/twitter/follow/ShangchenZhou?label=%40ShangchenZhou&style=social" alt="Twitter Follow"></a>
<a href="https://github.com/sczhou"><img style="margin-top:0.5em; margin-bottom:2em" src="https://img.shields.io/github/followers/sczhou?style=social" alt="Github Follow"></a>
</div>
<center><img src='https://visitor-badge-sczhou.glitch.me/badge?page_id=sczhou/CodeFormer' alt='visitors'></center>
"""
demo = gr.Interface(
inference, [
gr.inputs.Image(type="filepath", label="Input"),
gr.inputs.Checkbox(default=True, label="Background_Enhance"),
gr.inputs.Checkbox(default=True, label="Face_Upsample"),
gr.inputs.Number(default=2, label="Rescaling_Factor (up to 4)"),
gr.Slider(0, 1, value=0.5, step=0.01, label='Codeformer_Fidelity (0 for better quality, 1 for better identity)')
], [
gr.outputs.Image(type="numpy", label="Output"),
gr.outputs.File(label="Download the output")
],
title=title,
description=description,
article=article,
examples=[
['01.png', True, True, 2, 0.7],
['02.jpg', True, True, 2, 0.7],
['03.jpg', True, True, 2, 0.7],
['04.jpg', True, True, 2, 0.1],
['05.jpg', True, True, 2, 0.1]
]
)
demo.queue(concurrency_count=2)
demo.launch()建议可以自行提前下载好对应的模型权重文件,直接执行app.py即可启动。如下所示:
 文章来源:https://www.toymoban.com/news/detail-686027.html
文章来源:https://www.toymoban.com/news/detail-686027.html
感兴趣的话都可以自行搭建一下尝试把玩一番。文章来源地址https://www.toymoban.com/news/detail-686027.html
到了这里,关于一键快速还原修复人脸,CodeFormer 助力人脸图像修复的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!