摘要
尽管功能性近红外光谱(fNIRS)在神经系统研究中的应用越来越广泛,但fNIRS信号处理仍未标准化,并且受到经验和手动操作的高度影响。在任何信号处理过程的开始阶段,信号质量控制(SQC)对于防止错误和不可靠结果至关重要。在fNIRS分析中,SQC目前依赖于将经验阈值应用于手动操作的信号质量指标(SQIs)。本研究使用了67名受试者的fNIRS信号数据集(N=1340),并手动标记了一部分片段(N=548)的信号质量,以考察当前研究中存在的问题,并探索深度学习方法提供的机会。本研究发现,SQIs在统计上可以区分质量较差的信号,但通过经验阈值进行识别的敏感性较低。与手动阈值相比,基于SQIs的传统机器学习模型被证明更准确,而基于卷积神经网络的端到端方法能够进一步提高性能。本文提出的基于机器学习的方法为fNIRS提供了更客观的SQC,并朝着使用完全自动化和标准化程序的方向发展。
前言
近年来,功能性近红外光谱(fNIRS)在神经影像研究中的应用迅速发展,特别是在婴儿神经影像和认知神经科学等领域。fNIRS是一种非侵入性神经成像技术,通过使用近红外光来检测大脑皮层区域的活动。具体而言,fNIRS根据不同的光吸收来测量氧合和脱氧血红蛋白浓度的相对变化,反映了大脑激活和失活。尽管fNIRS被广泛采用,但对于最佳的fNIRS信号处理方法尚未达成共识,据报道使用不同的处理步骤组合会导致不同的研究结果。
fNIRS数据分析中的一个关键预处理步骤是对原始信号进行信号质量控制(SQC),以从下游分析中去除低质量的信号。由于没有可用的fNIRS信号质量的基准参考,因此基线是由人工对信号进行目视检查得出的。然而,目测评估使得SQC依赖于研究人员的专业知识和期望“良好”质量信号的主观判断。目前的方法倾向于避免将目测评估作为唯一的SQC方法,尽管它经常用于验证fNIRS信号处理流程的结果。最后,目测评估有望在参考数据集的创建中发挥关键作用,其中质量标签是由人工评估得出的。
SQC目前依赖于信号质量指标(SQIs)的计算,这些指标基于一些旨在量化fNIRS信号形态特征的算法。决定从下游分析中删除哪些信号,是基于应用于SQIs的经验固定阈值。目前已提出多种SQIs,例如头皮耦合(SC)和头皮耦合功率(SCP),变异系数(CV)和波长变异系数(CVW),信号质量指数,与心脏信号的关联等等。
除阈值法外,机器学习(ML)算法已被广泛应用于各种生理信号质量的分类。例如,Li等人开发了一种用于脉搏信号和心电图(ECG)信号的自动质量评估方法,而Gabrieli等人则使用不同的ML分类器来识别瞳孔测量信号的质量。关于fNIRS信号,Sappia等人提出了信号质量指数,并开发了基于信号质量指数的ML算法,取得了较好的效果。然而,信号质量指数是在非常有限的样本量上进行开发和测试的(开发N=123,评估N=40),并且数据是在存在潜在利益冲突的环境中收集的。
除了传统的机器学习方法外,基于人工神经网络(ANN)的深度学习方法如今被应用于各种领域,通常会改善传统机器学习方法所取得的结果。在基于医疗数据的应用中,ANN的应用正在迅速增长,而且应用范围广泛。卷积神经网络(CNN)是一类基于一系列连续非线性滤波单元(层)的ANNs。CNN能够创建端到端模型,因为原始数据(例如:图像或信号)直接用作输入,无需计算手动定义的特征:CNN的层次结构允许获取高层特征,从而将输入数据转换为解决分类任务所需的多维表征。这是与传统机器学习方法的一个关键区别,传统ML方法基于关系型数据,其中特征是由用户根据先验信息手动定义的。
关于深度学习方法在fNIRS信号中的应用,只有一项研究涉及信号质量的分类,而其他示例则涉及脑机接口应用的任务和手势识别。Gabrieli等人的研究旨在使用基于CNN的方法对510个短fNIRS数据进行质量分类。值得注意的是,质量标签是通过专家用于对fNIRS信号语料库进行评级的web界面收集的。他们的研究首次证实了使用CNN对fNIRS信号质量进行分类,并使用Matthew相关系数(MCC)来衡量分类的性能。所提出的CNN在训练集上实现了MCC=0.18的性能,在测试集上实现了MCC=0.25的性能。虽然ML方法在解决fNIRS数据的SQC方面显示出了有前景的结果,但它们尚未得到彻底的研究,关于该主题的文献仍然很少。
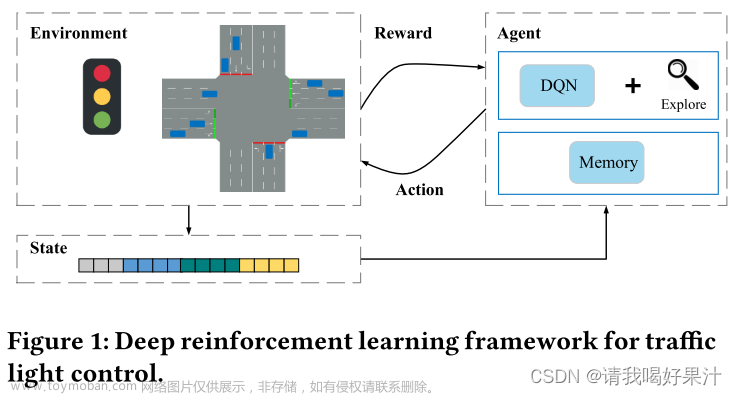
本研究对fNIRS数据的SQC所涉及的几个方面进行了详细的研究。首先,本研究分析了人类主观评估的作用,并测量了四名不同评分者之间的一致性。其次,测试了5种最常用的手动SQI的适用性:首先进行统计测试,然后基于SQI阈值评估SQC的性能。第三,本研究探索了使用传统机器学习和深度学习方法进行SQC的潜力;特别是评估了两个基于手动SQI训练的传统机器学习模型以及基于原始信号训练的CNN的性能。最后,应用模型检验技术来探索从训练好的模型中提取知识的可能性,旨在为SQC的实施和数据采集设置的优化提供实用指南。
材料和方法
A.数据集
在一项旨在评估男性和女性对带有性别歧视言论对话的不同大脑反应实验中收集数据。该实验获得了南洋理工大学心理学项目伦理委员会(PSY-IRB-2020-007)的批准。研究中构建了八个假设情境的实验片段,每个片段持续50s。这些片段呈现了四个情境,其中一个主角收到了来自四个不同伙伴的性别歧视言论,每个情境有两种类型的言论(赞扬和批评)。实验共包含67名参与者(38名女性)。参与者需要阅读所有八个实验片段;阅读完毕后,他们将回答一组问题,以衡量他们对每个片段的情绪反应。
在实验过程中,采集fNIRS信号来测量背外侧前额叶皮层的激活。使用NIRS设备(NIRSport,NIRx Medical Technologies LLC,Glen Head,NY,USA)采集信号,并配备有8个发光二极管(波长760-850nm)和7个光电二极管探测器的电极帽,共计20个多距离通道(采样率:7.81Hz)。采用NIRStar 15.0软件记录数据。这项研究重点关注由光电二极管收集的每个通道的原始数据,每个通道由两个信号组成。通过三次样条插值对信号进行10Hz的重采样。
该数据集包括1340个通道信号(20个通道×67个受试者)。为了进行信号质量的手动标记,本研究将样本限制为与片段呈现(长度为50s)相关的548个片段,这些片段是随机选择的。采用分层随机选择方法,首先随机选择条件,然后随机选择情境,最后随机选择通道。所选的子集包含来自64个不同受试者的数据;每个受试者的片段数在3-15之间(中位数=8,均值=8.6,标准差=2.8);每个通道包含的片段数介于18-41之间(中位数=27,均值=27.4,标准差=5.2)。
与Gabrieli等人(2021)的操作类似,4名训练有素的专家根据fNIRS信号的图像手动评估每个片段的质量。图像大小为1500×1000像素,时间分辨率为23.6 pixels/s(见图1中的图像缩放示例)。要求评分者将每个片段的质量标记为“好”(即,该信号可以使用)或“差”(即,该信号应该舍弃)。通过多数投票将4名评分者的评分汇总,以得到每个片段的最终标签。如果出现平局,则将该片段视为信号质量差。
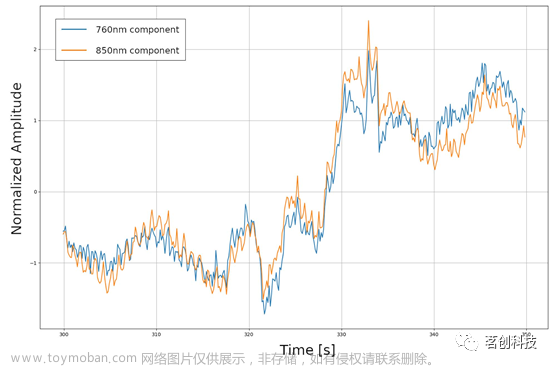
图1.一段持续50s的fNIRS数据示例,其中包含两个波长(760nm和850nm)的信号,这些信号用于手动评估信号的质量。
然后,将具有548个标记分段的数据集随机分为两个不同的部分,以测试每种信号质量分析(SQC)方法的泛化能力:75%(N=411)的分段用于训练,其余25%(N=137)用于测试。在训练集中,良好类别的信号比例为66.2%,在测试集中良好类别的信号比例为62.0%。
B.信号质量指标(SQIs)
在fNIRS信号最常用的SQI中,本研究选取了4种SQIs:头皮耦合(SC)和头皮耦合功率(SCP),变异系数(CV)和波长变异系数(CVW)。对于每个SQI,文献还定义了通常应用于自动化管道的阈值,以对信号质量进行分类。通常情况下,良好质量的信号满足以下条件:SC>0.7,SCP>0.1,CV<7.5,以及CVW<5。
此外,本研究还计算了心脏功率(CP),类似于SC,旨在量化心脏成分的存在。从滤波后的fNIRS信号(带通滤波器:0.83-2.5Hz)开始,估计心脏频率(fc)为0.83-2.5Hz范围内功率最高的频率。然后计算fc-0.2—fc+0.2Hz频段功率与fc-0.5—fc+0.5Hz频段功率的比值CP。预期良好分类的信号满足条件:CP≥0.5。
C.机器学习
本研究采用了两种传统的机器学习方法来对fNIRS信号的质量进行分类:第一种方法中,本研究测试了基于五个SQIs的两个标准模型:线性核支持向量机(SVM)和随机森林(RF);在第二种方法中,本研究使用了直接应用于原始信号的端到端卷积神经网络(CNN)。
为了训练标准模型,首先优化了SVM和RF的模型参数:正则化参数C(C:0.00001,0.0001,0.001,0.01,0.1,1,10,100,1000,10000)和树的数量n(n:1,5,10,50,100,250)。为了防止过拟合,还校准了RF模型的以下参数:树的最大深度设置为3,叶节点的最小样本数量设置为10。
该优化基于传统的10次5折交叉验证方案。将训练集数据随机分成5份:其中1份用于验证,剩下的4份用于训练模型,然后在验证集上对模型进行评估。该过程对5折进行迭代,然后重复10次,在每次重复之前对数据进行重排。
在每次迭代中,通过对留出折上的Matthew相关系数(MCC)得分进行自举法估计得到每个模型参数值的性能。MCC的计算方法如下:
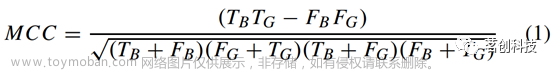
其中,TB和TG分别是正确分配给“差”和“好”信号质量类别的段数,而FB和FG分别是错误分配给“差”和“好”信号质量类别的段数。选择MCC较高的模型参数值作为最优值。使用模型参数的最优值在整个训练数据集上进行最终模型训练。
这里采用的CNN架构灵感来自Bizzego等人(2021)研究中的架构。原始架构是在fNIRS信号数据集(来自训练集)上训练的,训练集和测试集上的MCC分别为0.648和0.622。本研究进行了额外的实验来评估替代网络架构。具体而言,本研究测试了不同的解决方案,这些解决方案在卷积块的数量(从2到4)、输出通道数(从16到256)和卷积核大小(从3到21)方面有所不同。表现最好的架构是由两个连续部分组成的架构:(i)卷积分支和(ii)全连接层(见图2)。

图2.卷积神经网络图。
该网络的输入是fNIRS信号中的20s长度部分。在训练期间,在与插图表示相对应的50s内随机选择20s的部分;在评估期间,这20s的部分对应于情境呈现的中心部分。训练期间随机选择的部分用于执行数据增强:每次用于训练的信号,都选择不同的部分。这个过程为网络的输入增加了一定的随机可变性,从而降低了过拟合的风险。
训练过程使用反向传播算法进行,目标是最小化真实类别与预测类别之间的加权交叉熵。由于“差”和“好”两个类别的样本量不同,因此“好”类别的权重设置为0.66,“差”类别的权重设置为0.34。
该网络在训练集信号上进行了200个epochs的训练,随机批次大小为64、使用Adadelta优化器和初始学习率为0.01。在每个epoch中,训练集信号被随机打乱,并分成64个批次的信号。每个批次经网络处理后输出预测的类别概率,然后将其与真实类别进行比较。利用加权交叉熵计算预测误差,然后对误差进行反向传播,并使用Adadelta算法优化网络的权值。
D.分析计划
分析1:人的主观评价对信号质量的影响
由于缺少关于fNIRS信号质量的真实参照标准,因此对信号质量的评估依赖于人类主观评估。定义有效的SQI及其阈值,或开发自动化方法的所有后续工作都依赖于人类提供可靠评估的能力。本研究根据四名评分者之间的一致性和每个评分者的表现来量化这种能力。基于双向随机效应模型平均类内相关性(ICC)对一致性进行量化。通过计算评分者与其他评分者的之间的MCC分数来量化每个评分者的表现。
分析2:手动SQI的有效性
然后,本研究重点评估了5个SQI的适用性。首先,对每个SQI进行双侧Mann-Whitney检验,以评估“好”信号和“差”信号之间是否存在统计学差异。本研究预期所有的SQI都会显示出显著的结果(α<0.05)。此外,本研究评估了SQIs之间的Spearman相关性。本研究预期SC、SCP和CP指标具有高度相关性(ρ>0.7),因为它们旨在量化原始fNIRS信号中的心脏成分。其次,基于SQIs的值及其阈值进行SQC,这是当前研究实践中用于识别信号质量好坏的最常见方法。在实践中,对于每个fNIRS分段,检测每个SQI的值是否位于与良好质量相关的区间内,如果所有五个SQIs的值都在各自的区间内,则认为该段具有良好的质量。
分析3:机器学习方法
最后,本研究探索了使用机器学习方法来替代当前的SQC实践。SVM模型和CNN都使用训练集数据进行训练。为了客观地比较不同的SQC方法(人工评分,SQI阈值,SVM模型和CNN),分类性能总是在训练集和测试集上进行计算。具体而言,本研究使用自举法(bootstrapping)生成总体MCC及其90%置信区间(90%CI)。在自举过程中,使用重复抽样的方式随机选择25%的样本,并在所选的子集上计算MCC得分;然后重复这个过程1000次。以MCC得分生成分布的第50、5和95百分位数分别计算总体MCC及其90%CI。
分析4:模型检查
本研究采用两种模型检测技术从训练好的ML模型中提取知识,旨在为SQC的实施和数据采集设置的优化提供实际指导。对于两个传统的机器学习模型(SVM和RF),本研究计算了SQIs的排序,以获得哪些SQIs对预测信号质量最重要的信息。对于深度学习(DL)模型,本研究对卷积分支的输出节点进行了无监督探索。为了获得SQIs的排序,首先基于训练模型和测试集数据计算SQIs的排列重要性。SQI的排列重要性是指在对该SQI的值进行随机打乱后,MCC分数的下降情况。在本研究中,排列重要性被计算30次,然后取平均值,以确定SQIs的排名。
使用均匀流形近似和投影(UMAP)多维投影方法对卷积分支的1280个输出节点进行无监督探索。具体而言,采用二维UMAP以便于投影结果的可视化。然后,本研究旨在考察低质量信号之间的主要差异,以确定关键的诊断模式,从而提出改进实验设置中信号质量的策略。本研究在UMAP投影上应用K-means聚类,使用肘部法则基于每个数据点与其最近质心之间距离的平方和选择最佳的聚类数。然后,根据信号模式定性分析了每个聚类的主要特征。
E.数据和代码的可用性
本研究执行的分析是在Python(v.3.8.10)中实现的。使用Numpy(v.1.19.4)、Pandas(v.1.1.4)、scikit-learn(v.0.23.2)和pyTorch(v.1.9.0+cu102)库构建了机器学习管道。UMAP和聚类管道使用了umap-learn(v.0.5.3)、scikit-learn(v.0.23.2)和yellowbrick(v.1.4)库构建。本研究使用的数据和复制分析的代码可在以下网址获得:https://gitlab.com/abp-san-public/fnirs-qsi-ml
结果
A.评分者一致性和表现
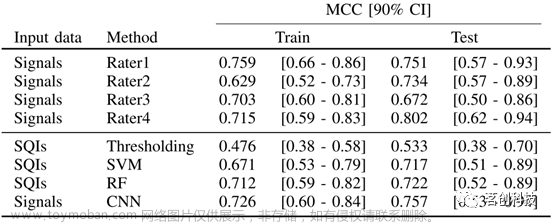
评分者间的一致性为ICC=0.774(p<.001),尽管理想值通常在0.9以上,但该值被认为是可接受的。四个评分者在训练集和测试集上的总体MCC值范围分别为[0.629-0.759]和[0.672-0.802]。(见表I)
表I.不同评分者和信号质量控制方法在训练集和测试集上的Matthew相关系数(MCC分数),以及由自举法估计的90%置信区间(90% CI)。SVM:支持向量机,RF:随机森林,CNN:卷积神经网络。
值得注意的是,评分者似乎最大限度地提高了灵敏度或精度(图3)。评分者1最大限度地提高了灵敏度而不是精度,训练集上的精度为0.865,测试集上的精度为0.840(90%CI分别为[0.80-0.92]和[0.71-0.96]),同时在训练集和测试集上的灵敏度均为1.000。同样,评分者3在训练集上的精度为0.840,测试集上的精度为0.800(90%CI分别为[0.77-0.90]和[0.67-0.92]),同时在训练集和测试集上的灵敏度均为1.000。相反,评分者2将精度最大化而牺牲了一定的灵敏度,在训练集上的精度为0.979,在测试集上的精度为1.000(训练集的90%CI为[0.93-1.00]),同时在训练集和测试集上的灵敏度分别为0.706和0.750(90%CI分别为[0.61-0.79]和[0.57-0.89])。
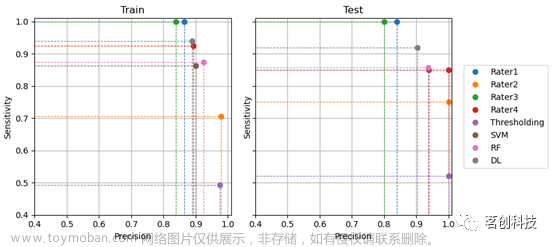
图3.不同评分者和信号质量控制方法在训练集和测试集上的灵敏度和精度得分。
B.手动SQI验证
Mann-Whitney检验结果(表II)表明,对于信号质量好或差的信号,SQIs的分布存在显著差异。
表II.五个信号质量指标的好或差质量信号的中位数,以及Mann-Whitney检验结果。

此外,所有SQIs均显著相关(表III),SC和SCP之间的相关性最高(ρ=0.80,p<.001),其次是SCP与CP之间的相关性(ρ=0.72,p<.001)。
表III.五个信号质量指标之间的Spearman相关值。***:p<.001

基于SQI阈值的信号质量控制(SQC)(表I和图3)在训练集和测试集上的MCC分别为0.476和0.533(90%CI分别为[0.38-0.58]和[0.38-0.70]),具有较高的精度(训练集:0.976,90%CI:[0.93-1.00];测试集为1.00),但灵敏度较低(训练集:0.493,90%CI:[0.40-0.60];测试集为0.520,90%CI:[0.33-0.69])。这种方法会导致许多信号质量较好的信号无法使用(表IV)。
表IV.基于SQI阈值的SQC混淆矩阵。粗体值表示将被拒绝的高质量段数。

C.机器学习(ML)
传统ML模型的性能与之相当。基于SQI的SVM模型(最佳C=100)在训练集和测试集上的MCC分别为0.671和0.717(90%CI分别为[0.53-0.79]和[0.51-0.89]),与人工评分者的性能相当(表I)。基于SQI的RF模型(最优树数=100)在训练集和测试集上的MCC分别为0.712和0.722(90%CI分别为[0.59-0.82]和[0.52-0.89])。无论是在训练集还是测试集上,两种模型的结果都与SVM模型相当(表I)。
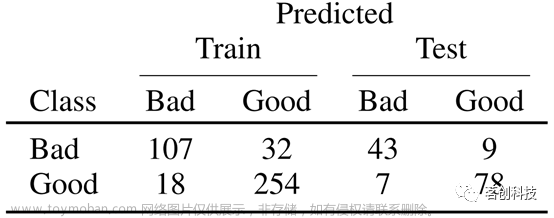
深度学习(DL)模型的应用进一步提高了性能。应用于原始信号的卷积神经网络(CNN)在训练集和测试集上的MCC分别为0.726和0.757(90%CI分别为[0.60-0.84]和[0.53-0.94])。CNN在所有机器学习方法中取得了最好的性能,在训练集上的精度为0.890(90%CI:[0.53-0.79]),在测试集上的精度为0.900(90%CI:[0.77-1.00]),在训练集和测试集上的灵敏度分别为0.938和0.917(90%CI分别为[0.88-0.97]和[0.81-1.00])(表V和图3)。
表V.基于卷积神经网络的SQC混淆矩阵。
使用CNN实现的性能明显优于传统的机器学习模型:SVM(p<0.001)和RF(p<0.001)。SVM和RF方法之间没有显著差异(p=0.092)。而SVM模型的性能显著优于基于SQIs的阈值分割(p<0.001)。
D.模型检查
两个模型基于排列重要性的SQIs排名略有不同。对于SVM模型,排序依次为:SC、CV、CP、SCP和CVW。对于RF模型,排序依次为:CV、SC、CVW、SCP和CP。值得注意的是,这两个模型的前两个特征相同:SC和CV。这表明,评估信号质量需要同时考虑心脏成分指标和信号变异性的全局指标。因此,未来开发用于自动或半自动识别信号质量的工具和算法应考虑这两个关键的SQIs。
使用UMAP计算的1280个节点的二维嵌入(图4A)显示出两个类别之间的明显分离,低质量信号聚集更紧密。然后应用K-means聚类算法,将目标聚类数设置为3,这是根据肘部法则得到的最优聚类数。
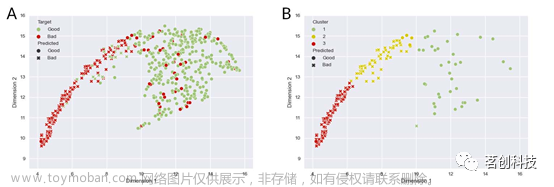
图4.均匀流形近似和投影算法的结果。
第一个聚类(图4B)主要包括与高质量信号组重叠的低质量信号。通过观察属于该聚类的一些随机选择的信号示例(图5),可以发现这些信号总体上质量良好,除了可能由于运动引起的尖峰或下降,这在仪器设置过程中很难预见到。
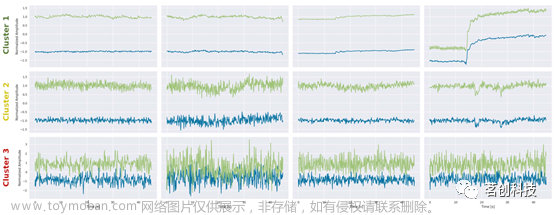
图5.从每个聚类中随机选择的信号示例。蓝色:760nm波长;绿色:850nm波长。
第二个和第三个聚类似乎将低质量信号组分割开来,其中第二个聚类在“拓扑上”更接近高质量聚类。这两个聚类在噪声幅度和两种波长均值之间的距离上似乎有所不同。在某些情况下,心脏成分和其他一些信号成分可能在第二个聚类的信号中被识别:这表明低质量的原因主要是光电极和头皮之间的耦合不良,或者来自外部光源的干扰。相反,在第三个聚类中,除了白噪声外,很难在信号中识别出任何成分,这表明光电极的设置需要彻底修改。总的来说,这两个聚类表明,UMAP中的轨迹与信号质量的下降有关。
结论
本研究考察了fNIRS数据SQC所涉及的几个方面,旨在确定开发全自动和可靠SQC程序的开放问题和机会。本研究强调了主观性在基于目视检查信号质量评估中的作用,测量了四个不同评分者的一致性和表现。然后,评估了使用手动SQI进行信号质量分类的方法,展示了机器学习模型(SVM)相比基于阈值的方法的优越性。最后,本研究探索了使用深度学习方法的潜力,使用CNN直接在原始信号上进行分析。总的来说,本研究强调了自动化SQC的主要限制可能是人工评分者之间缺乏一致性。事实上,CNN的性能与人工评分者相当;此外,一些评分者的90%CI范围甚至低于CNN本身。这项研究表明,现有的计算方法足以定义可靠的SQC程序,而实现这一发展的主要障碍似乎是缺乏高一致性标签的参考数据集。因此,科学界的努力应着眼于在开放科学原则下建立一个资源共享库。文章来源:https://www.toymoban.com/news/detail-686081.html
参考文献:A. Bizzego, M. Neoh, G. Gabrieli and G. Esposito, A Machine Learning Perspective on fNIRS Signal Quality Control Approaches, in IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 30, pp. 2292-2300, 2022, doi: 10.1109/TNSRE.2022.3198110.文章来源地址https://www.toymoban.com/news/detail-686081.html
到了这里,关于基于机器学习的fNIRS信号质量控制方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!