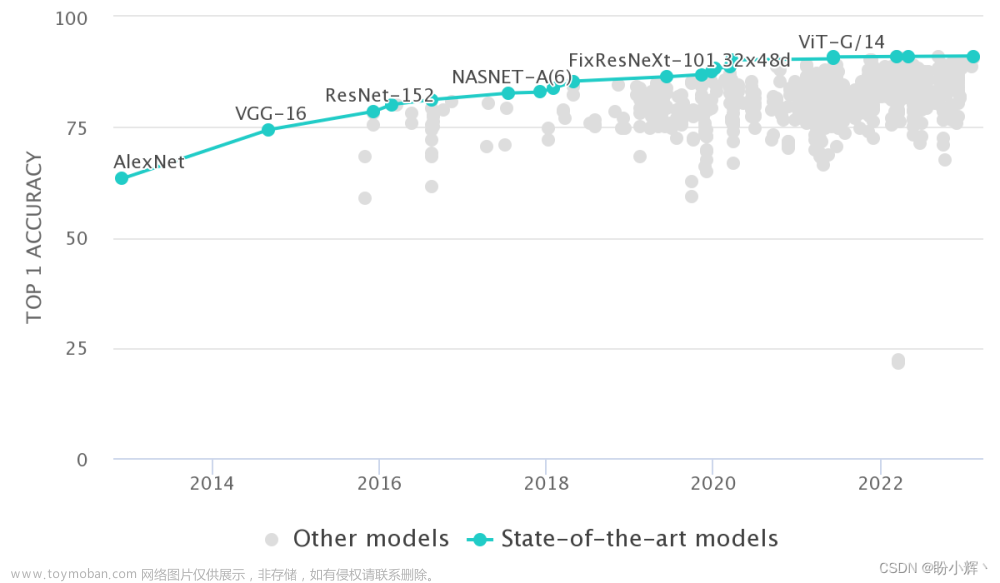
强化学习基础
强化学习是指智能体在不确定环境中最大化其获得的奖励从而达到自主决策的目的。其执行过程为:智能体依据策略决策从而执行动作,然后感知环境获取环境的状态,进而得到奖励(以便下次再到相同状态时能采取更优的动作),然后再继续按此流程“依据策略执行动作-感知状态–得到奖励”循环进行。

【强化学习是一种无监督学习】强化学习没有标签告诉它在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的reward,然后判断当前选择的行为是好是坏。某一状态的价值函数等于即时奖励+折扣因子×后续一系列状态的奖励。
基于值函数的方法
通过求解一个状态或者状态下某个动作的估值为手段,从而寻找最佳的价值函数,找到价值函数后,再提取最佳策略。【总结】通过做出动作后,找最佳的价值函数,提取最佳策略。
基于策略的方法
一般先进行策略评估,即对当前已经搜索到的策略函数进行估值,得到估值后,进行策略改进,不断重复这两步直至策略收敛。【总结】对策略进行估值,优化使策略估值最大化。
马尔科夫
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质。具备马尔科夫性质的随机过程称为马尔科夫过程。
马尔科夫奖励
在马尔科夫过程的基础上加入奖励函数和折扣因子就变为了马尔科夫奖励过程。
【奖励函数】某个状态s的奖励是指转移到该状态s时可以获得的奖励期望。
【回报】其实某一状态获得的奖励是持久的,因为当前状态导致下一状态获得的奖励乘以折扣因子就是持久奖励。回报=当前奖励+持久奖励。
【状态价值】某一状态可以获得回报的期望。

马尔科夫决策过程
在马尔科夫奖励过程中加入来自外界的刺激如智能体的动作,就得到了马尔科夫决策过程。
【状态价值函数】某一状态可以获得奖励的期望乘以该状态的价值。
【动作价值函数】在某一状态下采取某一动作所获得奖励的期望。—Q函数
TD误差(时序差分)

当前奖励+衰减因子*持久奖励-预估奖励=TD误差。
强化学习的分类
基于模型的强化学习
可以简单的使用动态规划求解,任务可定义为预测和控制,预测的目的是评估当前策略的好坏,即求解状态价值函数。
无模型的强化学习
基于价值的强化学习,其会学习并贪婪的选择奖励值最大的动作。
基于策略的强化学习,其对策略进行建模和优化。
重要性采样
假设有一个函数,x需要从分布p中采样数据;但是当不能从分布p中采样数据而只能从另一个分布q中采用数据时,需要做一些变换。

如此便可以从分布q中采样x,再进行计算。
而异策略就是基于重要性采样的原理实现的。因为一旦更新了策略参数,那么采取相应动作的概率就会发生变化,这时就需要用到重要性采样的原理。
策略学习
【策略梯度更新的思想】参数为θ的策略πθ接受状态s,输出动作概率分布,在动作概率分布中采样动作,执行动作(形成运动轨迹),得到奖励r,跳到下一个状态。在这样的步骤下,可以使用策略π收集一批样本,然后使用梯度下降算法学习这些样本,不过当策略π的参数更新后,这些样本不能继续被使用,还要重新使用策略π与环境互动收集数据。
【策略价值函数】所有状态动作移动轨迹发生的概率×对应的奖励。
策略梯度定理:
【优势函数】

用于衡量某一个状态下是否采取某一动作。
TRPO:加进KL散度解决两个分布相差大的问题
在目标函数里面加入了约束。TRPO的问题在于把 KL 散度约束当作一个额外的约束,没有放在目标里面,导致TRPO很难计算
PPO(相对TRPO减少了计算量)
通过KL散度(相对熵)加入惩罚项、截断的方式使得更新的策略不与原策略相差太大。
RLHF:基于人类偏好的强化学习
1.首先,智能体的一对1-2秒的行为片段定期地回馈给人类操作员,人类基于偏好对智能体的行为作出某种偏好性的选择评判。
2.接着,人类这种基于偏好的选择评判被预测器来预测奖励函数。
3.智能体通过预测器预测出的奖励函数作出更优的行为。
ChatGPT的训练过程

第一阶段:利用人类的问答数据对GPT3微调进行有监督训练出SFT模型(作为baseline)。
1.一共进行了16个epochs的训练。
2.采用了余弦学习率衰减策略。
3.残差丢弃率。
第二阶段:通过RLHF的思路训练一个奖励模型RM。
首先使用第一阶段训练的SFT模型初始化第二阶段的RM模型。针对每个问题收集4-9个不同的回答,人工对这些回答的好坏进行标注且排序,排序的结果来训练一个RM模型,使模型从排序数据中理解人类的偏好。
不同回答两两组合,计算奖励差值。
【这里为什么是排序而不是打分】因为不同的标注员,打分的偏好会有很大的差异,排序的一致性要高于打分的一致性。
第三阶段:通过最大化奖励函数的目标下,通过PPO算法继续微调GPT4模型。
首先使用第一阶段训练的SFT模型初始化一个PPO模型,使用不带任何人工标注的数据集训练,使用第二阶段训练的RM奖励模型去给PPO模型的预测结果进行打分和排序。之后通过奖励最大化优化PPO模型的策略参数,PPO算法限制策略更新范围。
总目标函数

第一部分是使奖励最大化,利用重采样的思想展开如下所示:

第二部分是惩罚项,目的是不让新学习到的策略函数偏离baseline策略SFT太多。
第三部分是偏置项,防止训练出的模型过于讨好人类偏好,而不根据问题回答答案。(个人理解可以是防止数据集中的噪声带来干扰)
模型图

第一部分是使奖励最大化,利用重采样的思想展开如下所示:

第二部分是惩罚项,目的是不让新学习到的策略函数偏离baseline策略SFT太多。
第三部分是偏置项,防止训练出的模型过于讨好人类偏好,而不根据问题回答答案。(个人理解可以是防止数据集中的噪声带来干扰)
GPT1
使用了Transformer的decoder模型,将Encoder-Decoder注意力删除,将词嵌入维度从512改为768,将注意力头从8改为12,将block数量从6改为12。
从GPT1到GPT2
改进了decoder结构,将LN层前移到self-attention和前向神经网络之前。从外对参数也进行了改进,将维度从768改为1600,将block数量从12改为48。
虽然GPT1的预训练加微调的范式仅需要少量的微调和些许的架构改动,但能不能有一种模型完全不需要对下游任务进行适配就可以表现优异?GPT2便是在往这个方向努力:不微调但给模型一定的参考样例以帮助模型推断如何根据任务输入生成相应的任务输出。
针对【小样本/零样本】分为三种:零样本学习(是指在没有任何样本/示例情况下,让预训练语言模型完成特定任务)、单样本学习(是指在只有一个样本/示例的情况下,预训练语言模型完成特定任务)、少样本学习(是指在只有少量样本/示例的情况下,预训练语言模型完成特定任务)。【注】零样本、单样本、少样本并没有被模型去学习和微调,模型学习了样本输入输出的分布。
从GPT2到GPT3:开启Prompt学习
在维度上,将词嵌入维度由1600改为12888,设置了96个注意力头,block数目达到了96层。
prompt learning
让模型逐步学会人类的各种自然指令,而不用根据下游任务去微调模型或更改模型的参数,直接根据指令去干活,这个指令就叫做prompt。
指令微调技术(IFT)
IFT的数据通常是由人工手写指令和语言模型引导的指令实例的集合,这些指令数据由三个主要组成部分组成:指令、输入和输出,对于给定的指令,可以有多个输入和输出实例。
关于「prompt learning」最简单粗暴的理解,其实就是让模型逐步学会人类的各种自然指令或人话,而不用根据下游任务去微调模型或更改模型的参数,直接根据人类的指令直接干活,这个指令就是prompt,而设计好的prompt很关键也需要很多技巧,是一个不算特别小的工程,所以叫prompt engineering。
基于思维链(Cot)技术的prompt
为了让大模型进一步具备解决数学推理问题的能力,推出了最新的prompting机制–chain of thought,其给模型推理步骤的prompt,让其学习如何一步一步的推理,从而让模型具备推理能力,最终可以求解一些简单甚至相对复杂的数学问题。
GPT3的发展
一条路线是GPT3+RLHF+指令学习=InstructGPT
一条路线是增强代码/推理能力=GPT3.5
instructGPT
InstructGPT=GPT3+指令学习+RLHF
【训练三阶段】①有监督微调“经过自监督预训练好的GPT3”。②然后基于人类偏好排序的数据训练一个奖励模型。③最终在最大化奖励的目标下通过PPO算法来优化策略。
chatGPT与InstructGPT的区别在于:chatGPT是基于GPT3.5做微调,instructGPT是基于GPT3.0做微调。
基于GPT4的chatGPT的改进版:增加了多模态的技术能力。文章来源:https://www.toymoban.com/news/detail-686846.html
基于GPT4的ChatGPT改进版
新增了多模态技术能力。文章来源地址https://www.toymoban.com/news/detail-686846.html
到了这里,关于chatGPT训练过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[超级详细]如何在深度学习训练模型过程中使用GPU加速](https://imgs.yssmx.com/Uploads/2024/02/492057-1.png)