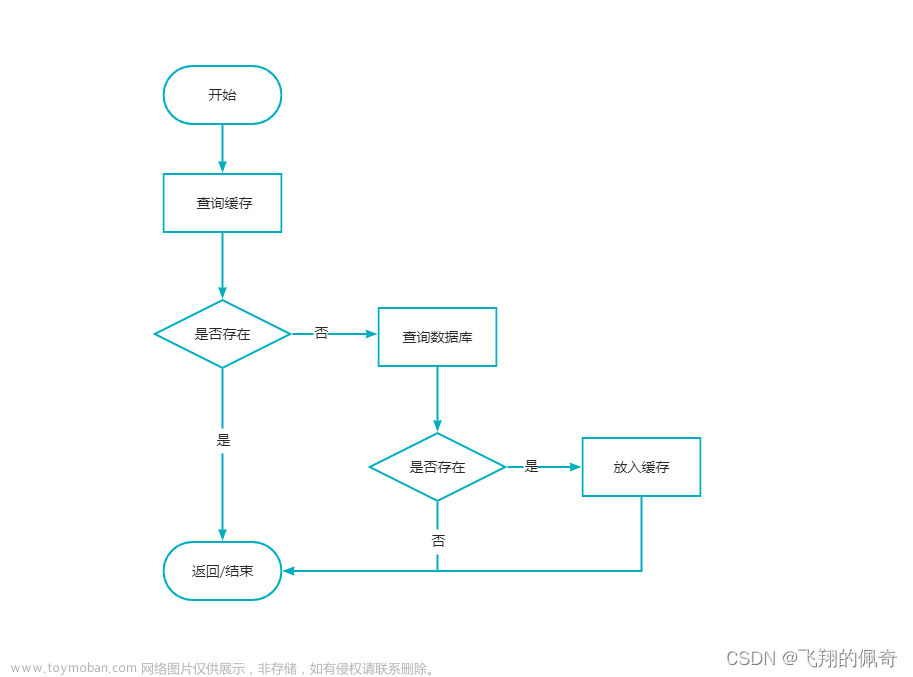
zset 有序集合 -> 升序
zset 中的 member 仍然要求是唯一的。
排序规则:按照输入的 score 来进行排序,如果score相同,再按照元素自身字符串的字典序来排序,score 不同仍然按照 score 来排序。
常用命令
zadd
添加或者更新指定的元素以及关联的 score 到 zset 中,score 应该符合 double 类型,+inf/-inf 作为正负 极限也是合法的。
ZADD 的相关选项
- XX:仅仅⽤于更新已经存在的元素,不会添加新元素。
- NX:仅⽤于添加新元素,不会更新已经存在的元素。
- CH:默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更 新的元素的个数。
- INCR:此时命令类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定⼀个元素和 分数。
- GT -> greaterthan: 如果限制给定的新的分数,比之前更新的分数大,此时才能更新成功,否则更新不成功。不会影响到新元素的添加。
- LT -> lessthan: 如果限制给定的新的分数,比之前更新的分数小,此时才能更新成功,否则更新不成功。不会影响到新元素的添加。
语法:ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]

incr 选项示例:
zcard
作用:获取 zset 中的元素个数。
语法:ZCARD key

zcount
作用:返回分数在 min 和 max 之间的元素个数,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
语法:ZCOUNT key min max
返回值:满⾜条件的元素列表个数

用 ( 号来排除边界值
zrange
作用:返回指定区间⾥的元素,分数按照升序。带上 WITHSCORES 可以把分数也返回。
语法:ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]
zrevrange -> reverse 逆序
作用:返回指定区间⾥的元素,分数按照降序。带上 WITHSCORES 可以把分数也返回。
ps:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
语法:ZREVRANGE key start stop [WITHSCORES]
zrangebyscore
作用:用于按照元素的分数范围来获取元素,默认情况下,min 和 max 都是包含的,可以通过 ( 排除。
ps:这个命令可能在 6.2.0 之后废弃,并且功能合并到 ZRANGE 中。
语法:ZRANGEBYSCORE key min max [WITHSCORES]
zpopmax
作用:删除并返回分数最大的 count 个元素。
语法:ZPOPMAX key [count]
返回值:返回删除的score 和 member 。
zpopmin
作用:删除并返回分数最小的 count 个元素。
语法:ZPOPMIN key [count]
返回值:返回删除的score 和 member 。
bzpopmax / bzpopmin
zpopmin / zpopmax 的阻塞版本
语法: BZPOPMIN/BZPOPMAX key [key ...] timeout
与list的blpop/brpop情况差不多。
zrank
作用:根据number返回指定元素的排名,升序,这里的排名指的就是下标。
语法:ZRANK key member
zrevrank
作用:返回指定元素的排名,降序,这里的排名指的就是下标。
语法:zrevrank key member
zscore
作用:查询指定元素的分数
语法:ZSCORE key member
zrem
作用:删除指定的元素。
语法:ZREM key member [member ...]

zremrangebyrank
作用:按照下标删除指定范围的元素,左闭右闭。
语法:ZREMRANGEBYRANK key start stop
zremrangebyscore
作用:按照分数删除指定范围的元素,左闭右闭。
语法:
ZREMRANGEBYSCORE key start stop

zincrby
作用:为指定的元素的关联分数添加指定的分数值
语法:
zincrby key increment member

集合间操作
在比较 “相同”的时候,只要 member 相同即可。
zinter -> 交集
语法:ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]
- numkeys 代表 numkeys 个 key 来参与并集运算。
- WEIGHTS 代表权重,可以写成小数和整数。
- aggregate 总计,代表当合并时member相同时,新的score是到底是以求和或者取最小值或者求大值的方式来算。默认以 求和 的来得到 score。
这里的zhangsan的score(65),是按照 key中zhangsan的score先乘以自己的权重值 2, 加上 key2 对应的权重值3乘以key2 zhangsan的score,即 2 * 10+ 3 * 15 = 65
zunion -> 并集
语法:
zunion numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>] [WITHSCORES]

zdiff -> 差集
语法:zdiff numkeys key [key ...] [WITHSCORES]
zinterstore
语法:zinterstore destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
zunionstore
语法:ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
zdiffstore
语法:zdiffstore destination numkeys key [key ...]
内部编码
有序集合类型的内部编码有两种:
- ziplist(压缩列表):当有序集合的元素个数⼩于 zset-max-ziplist-entries 配置(默认 128 个),同时每个元素的值都⼩于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会⽤ ziplist 来作 为有序集合的内部实现,ziplist 可以有效减少内存的使⽤。
- skiplist(跳表):当 ziplist 条件不满⾜时,有序集合会使⽤ skiplist 作为内部实现,因为此时ziplist 的操作效率会下降
在后面的版本中,在元素较少且元素的值较小时,ziplist编码被listpack编码替代。
在元素较少且元素的值较小时是listpack编码
当元素过大时,转换为skiplist文章来源:https://www.toymoban.com/news/detail-686935.html
 文章来源地址https://www.toymoban.com/news/detail-686935.html
文章来源地址https://www.toymoban.com/news/detail-686935.html
应用场景
排行榜系统(微博热搜、游戏天梯排行)
到了这里,关于9.Redis-zset的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!