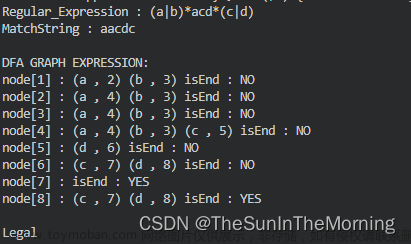
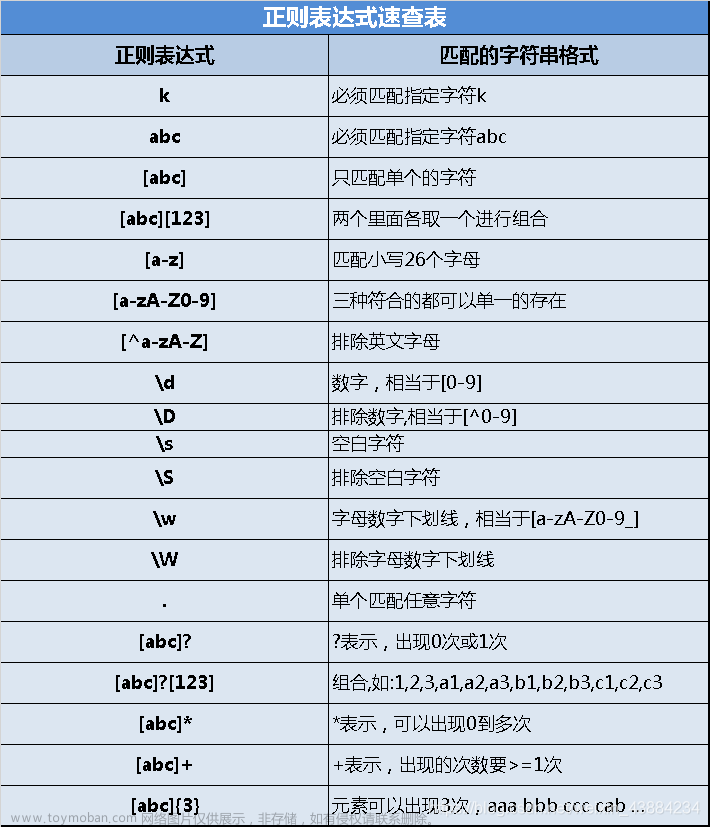
量词
字符类
边界匹配
分组和捕获
特殊字符
-
字符匹配
- 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 "a" 将匹配到文本中的 "a" 字符。
- 元字符:元字符具有特殊的含义,例如
\d匹配任意数字字符,\w匹配任意字母数字字符,.匹配任意字符(除了换行符)等。 -
*:匹配前面的模式零次或多次。 -
+:匹配前面的模式一次或多次。 -
?:匹配前面的模式零次或一次。 -
{n}:匹配前面的模式恰好 n 次。 -
{n,}:匹配前面的模式至少 n 次。 -
{n,m}:匹配前面的模式至少 n 次且不超过 m 次。 -
[ ]:匹配括号内的任意一个字符。例如,[abc]匹配字符 "a"、"b" 或 "c"。 -
[^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc]匹配除了字符 "a"、"b" 或 "c" 以外的任意字符。 -
^:匹配字符串的开头。 -
$:匹配字符串的结尾。 -
\b:匹配单词边界。 -
\B:匹配非单词边界。 -
( ):用于分组和捕获子表达式。 -
(?: ):用于分组但不捕获子表达式。 -
\:转义字符,用于匹配特殊字符本身。 -
.:匹配任意字符(除了换行符)。 -
|:用于指定多个模式的选择。
修饰符
- \i:忽略大小写
- \d:意思是digital数字,等同于[0-9]
- \g:意思是global全部,匹配多个的意思
文章来源地址https://www.toymoban.com/news/detail-687111.html
文章来源:https://www.toymoban.com/news/detail-687111.html
到了这里,关于正则表达式(常用字符简单版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!