摘要:本文将深入探讨大数据HBASE的使用步骤,帮助读者了解和掌握这一强大的分布式数据库系统的基本概念和操作技巧。通过本文的阅读,读者将能够熟悉HBASE的基本设置,了解其核心概念,掌握基本的查询和管理操作,并理解其在大数据环境中的应用场景。
一、介绍
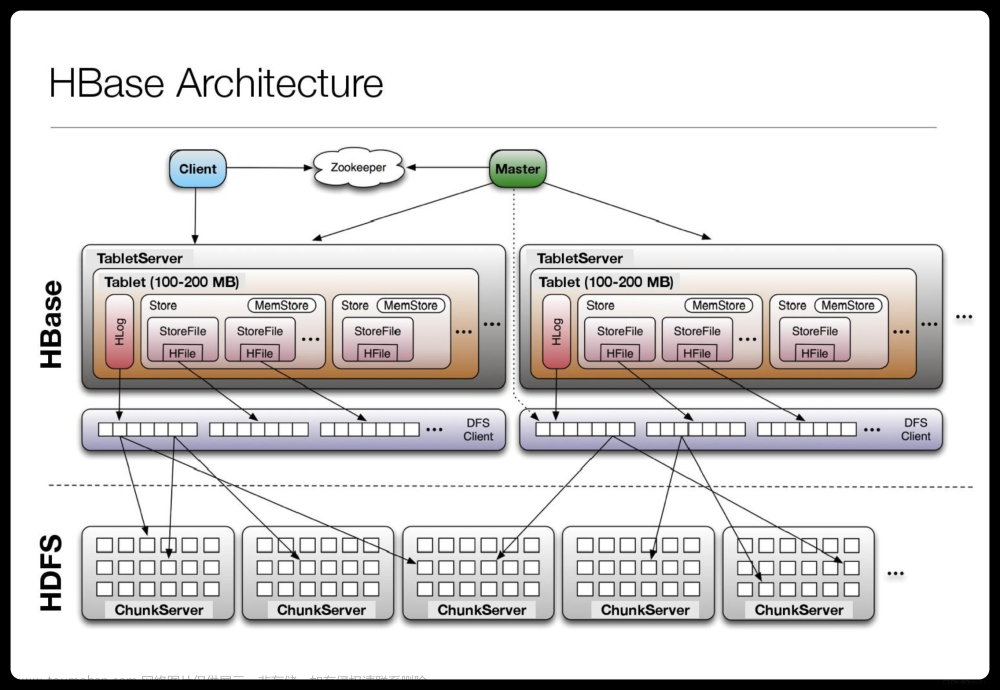
HBASE是一种开源的、分布式的、基于列存储的数据库,设计用于处理大规模的数据。它提供了高可靠性、高性能、实时读写等特性,适用于存储和处理大规模的结构化数据。本文将详细介绍HBASE的使用步骤,包括环境配置、表创建、数据插入、查询和管理等操作。文章来源:https://www.toymoban.com/news/detail-687182.html
二、环境配置
- 下载和安装HBASE。可以从官方网站或其他可信来源下载HBASE软件包,并按照官方文档进行安装和配置。
- 配置HBASE环境。包括设置JAVA环境、修改HBASE配置文件等。
- 启动HBASE。通过命令行输入
start-hbase.sh(Linux)或运行HBase.bat(Windows)来启动HBASE服务。
三、表创建
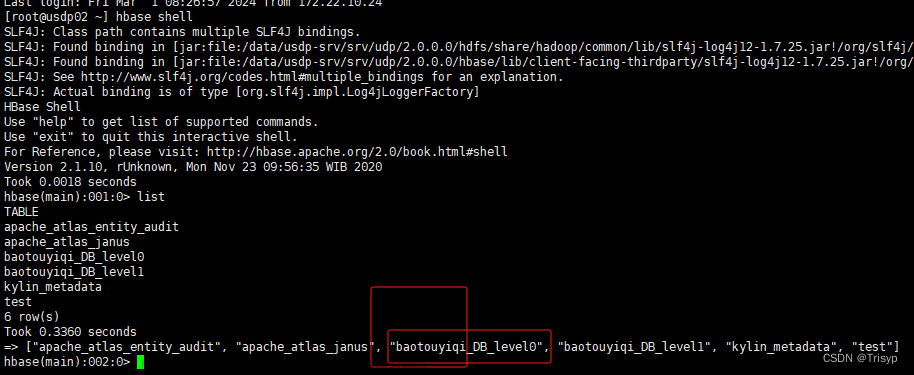
- 打开HBASE Shell。这是HBASE的命令行接口,可以在其中执行各种操作。
- 创建表。使用
create命令创建表,指定表名和列族。例如,create 'mytable', 'cf1', 'cf2'将创建一个名为'mytable'的表,具有两个列族'cf1'和'cf2'。
四、数据插入
- 插入数据。使用
put命令向表中插入数据。例如,put 'mytable', 'row1', 'cf1:col1', 'value1'将在表'mytable'中插入一行数据,行键为'row1',列族为'cf1',列限定符为'col1',值为'value1'。
五、查询数据
- 查询单行数据。使用
get命令查询特定行的数据。例如,get 'mytable', 'row1'将返回表'mytable'中行键为'row1'的数据。 - 查询多行数据。使用
scan命令可以查询表中的所有数据或指定范围内的数据。例如,scan 'mytable'将返回表'mytable'中的所有数据。
六、数据管理
- 删除数据。使用
delete命令删除特定行的数据。例如,delete 'mytable', 'row1', 'cf1:col1', 1234567890将删除表'mytable'中行键为'row1',列族为'cf1',列限定符为'col1',时间戳为1234567890的数据。 - 禁用表。使用
disable命令可以禁用表。例如,disable 'mytable'将禁用表'mytable'。 - 删除表。使用
drop命令可以删除表。例如,drop 'mytable'将删除表'mytable'。
七、总结
通过以上步骤,我们可以初步了解和掌握HBASE的基本操作。HBASE作为一款分布式数据库,具有强大的数据处理能力,适用于处理大规模的结构化数据。在实际应用中,我们需要根据业务需求和数据规模来设计和优化HBASE的使用。希望本文能对大家学习和使用HBASE有所帮助。文章来源地址https://www.toymoban.com/news/detail-687182.html
到了这里,关于大数据HBASE的详细使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!