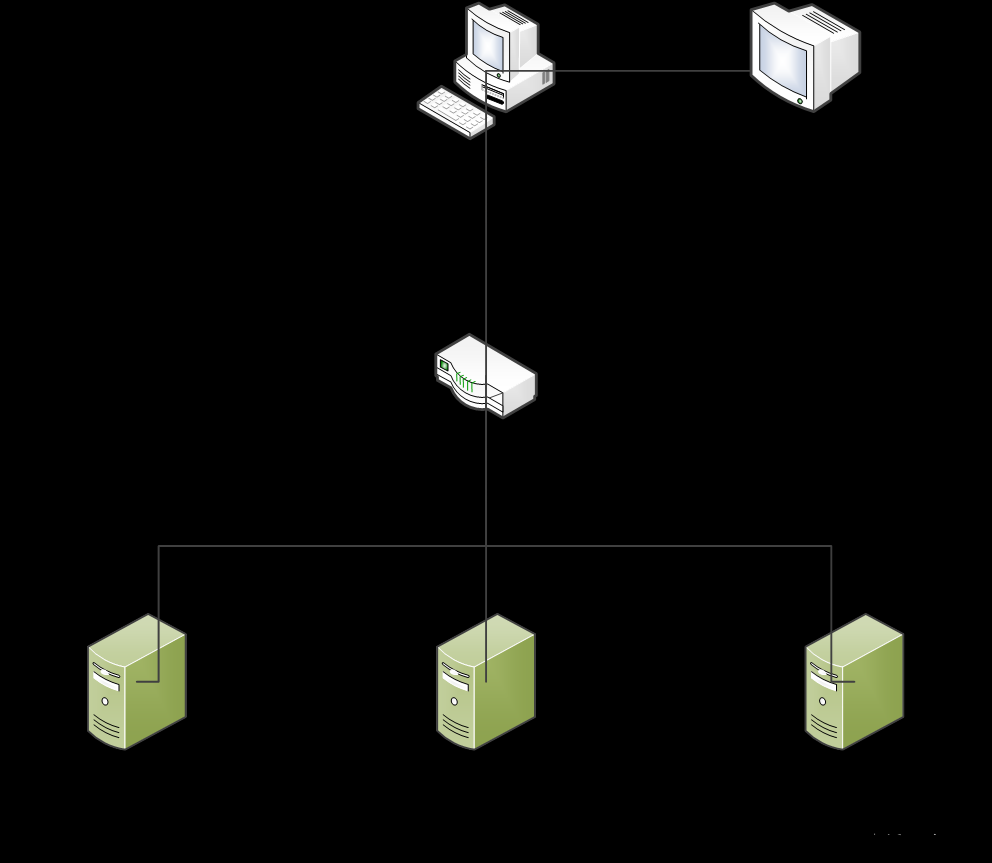
前期准备,每台服务器都需要配置
配置好IPvim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="bcd315b9-9d9a-4ad7-8f75-9546f71e49a4"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.245.200 #IP地址
GATEWAY=192.168.245.1 #默认网关
NETWORK=255.255.255.0 #子网掩码
DNS1=114.114.114.114 #DNS
DNS2=8.8.8.8
修改主机名vi /etc/hostname
做好IP映射vim /etc/hosts
192.168.245.200 master
192.168.245.201 slave1
192.168.245.202 slave2
关闭防火墙systemctl status firewalldsystemctl stop firewalldsystemctl disable firewalld
配置SSH免密登录ssh-keygen -t rsa
for i in {1..2};do scp -r ~/.ssh/authorized_keys root@slave${i}:~/.ssh/;done
安装Scala
下载Scala安装包
tar -zxvf scala-2.11.12.tgz -C /home/local
配置环境变量
vim /etc/profile
添加如下配置
export SCALA_HOME=/home/local/scala
export PATH=$SCALA_HOME/bin:$PATH
使环境生效
source /etc/profile
验证
scala -version
安装spark
Spark官网
解压
上传软件安装包至linux系统 /home/tools目录下
tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz -C /home/local
移动文件目录至spark
mv spark-2.2.3-bin-hadoop2.6 spark
配置环境
export SPARK_HOME=/home/local/spark
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
修改配置
进入${SPARK_HOME}/conf路径下,拷贝spark-env.sh.template为spark-env.sh
cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件
vim spark-env.sh
添加如下配置
export JAVA_HOME=/home/local/java
export SCALA_HOME=/home/local/scala
export SPARK_DIST_CLASSPATH=$(/home/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/local/hadoop/etc/hadoop
#指定spark主节点,通过主机映射
export SPARK_MASTER_HOST=master
#指定从节点worker并行数量
export SPARK_WORKER_CORES=2
#指定内存大小
export SPARK_WORKER_MEMORY=2g
#指定主节点端口
export SPARK_MAETER_PORT=7070
拷贝slave.template为slaves
cp slaves.template slaves
修改slaves文件
[root@master conf]# vim slaves
master
slave1
slave2
分发spark目录至每个服务器节点
for i in {1..2};do scp -r /home/local/spark/ root@slave${i}:/home/local/;done
在${SPARK_HOME}/sbin目录下启动spark
./start-all.sh
在Spark Shell中,你可以使用以下方法来读取HDFS文件:
1.读取文本文件:
val textFile = sc.textFile("hdfs://<HDFS路径>")
统计包含mike的数据记录
textFile.filter(line=>line.contains("mike")).count()
2.读取多个文本文件:
val textFiles = sc.wholeTextFiles("hdfs://<HDFS目录>")
3.读取二进制文件:
val binaryFiles = sc.binaryFiles("hdfs://<HDFS目录>")
4.读取其他格式的文件(如Parquet、Avro等):
val dataframe = sqlContext.read.format("<文件格式>").load("hdfs://<HDFS路径>")
这将返回一个 DataFrame 对象,可以使用Spark SQL进行数据分析。
pyspark读取文件
1.导入PySpark模块:
from pyspark.sql import SparkSession
2.创建SparkSession:
spark = SparkSession.builder \
.appName("PySpark Example") \
.getOrCreate()
3.加载数据
# 加载文本文件
text_data = spark.read.text("path/to/text/file.txt")
# 加载CSV文件
csv_data = spark.read.csv("path/to/csv/file.csv", header=True, inferSchema=True)
# 加载JSON文件
json_data = spark.read.json("path/to/json/file.json")
4.数据处理和转换
# 显示DataFrame的内容
df.show()
# 选择特定的列
df.select("column1", "column2")
# 过滤数据
df.filter(df.column1 > 10)
# 聚合操作
df.groupBy("column1").agg({"column2": "sum"})
# 排序数据
df.orderBy("column1", ascending=False)
# 添加新列
df.withColumn("new_column", df.column1 * 2)
5.执行sql查询
# 创建临时视图
df.createOrReplaceTempView("my_view")
# 执行SQL查询
result = spark.sql("SELECT * FROM my_view WHERE column1 > 10")
6.将数据保存到文件:文章来源:https://www.toymoban.com/news/detail-687492.html
# 保存为文本文件
df.write.text("path/to/save/text/file.txt")
# 保存为CSV文件
df.write.csv("path/to/save/csv/file.csv")
# 保存为Parquet文件
df.write.parquet("path/to/save/parquet/file.parquet")
7.关闭SparkSession文章来源地址https://www.toymoban.com/news/detail-687492.html
spark.stop()
到了这里,关于大数据学习06-Spark分布式集群部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!