注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/best_practices-logfiles.html文章来源地址https://www.toymoban.com/news/detail-687607.html
数据模型
- Greenplum数据库是一个分析型MPP无共享数据库。该模型与高度规范化/事务性的SMP数据库明显不同。
- Greenplum数据库使用适合MPP分析处理的非规范化模式设计(例如Star或Snowflake模式)表现最佳,使用大型事实表和较小的维度表。
- 对表间连接中使用的列使用相同的数据类型。
堆表还是AO存储
- 对于将接收迭代批处理和单条UPDATE、DELETE和INSERT操作的表和分区,使用堆存储。
- 对将接收并发UPDATE、DELETE和INSERT操作的表和分区使用堆存储。
- 对于在初始加载之后不经常更新的表和分区,以及只在大型批处理操作中执行后续插入的表和分区,使用追加优化的存储。
- 避免对追加优化的表执行单条INSERT、UPDATE或DELETE操作。
- 避免对追加优化的表执行并发批处理UPDATE或DELETE操作。并发批处理INSERT操作是可以接受的。
行存还是列存
- 对于需要更新和频繁插入的迭代事务的工作负载,使用面向行的存储。
- 当对表的选择很宽时,使用面向行的存储。
- 将面向行的存储用于一般用途或混合工作负载。
- 使用面向列的存储,其中选择范围很窄,并且在少量列上计算数据聚合。
- 对于具有定期更新的单列而不修改行中其他列的表,使用面向列的存储。
压缩
- 对大型追加优化表和分区表使用压缩,以改善整个系统的I/O。
- 在数据所在的级别设置列压缩设置。
- 在更高级别的压缩与压缩和解压缩数据所需的时间和CPU周期之间取得平衡。
分布
- 为所有表显式定义分布列或随机分布。不要使用默认值。
- 使用单个列将数据均匀地分布在所有段上。
- 不要在将在查询的WHERE子句中使用的列上进行分发。
- 不要分布在日期或时间戳。
- 永远不要在同一列上分布和分区表。
- 对于通常连接在一起的大型表,通过分布在同一列上实现本地连接,可以显著提高性能。
- 要确保没有数据倾斜,请验证数据在初始负载和增量负载之后均匀分布。
资源队列内存管理
- 将vm.overcommit_memory设置为2。
- 不要将操作系统配置为使用大页面。
- 使用gp_vmem_protect_limit设置实例可以为每个segment中正在完成的所有工作分配的最大内存。
- gp_vmem_protect_limit的使用方法如下:
gp_vmem—Greenplum数据库可用的总内存
如果系统总内存小于256GB,使用如下公式:
gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.7
当系统总内存大于等于256GB时,使用如下公式:
gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.17
其中SWAP为主机的交换空间,单位为GB; RAM为主机的RAM,单位为GB。
max_acting_primary_segments—由于主机或段故障而激活镜像段时,主机上可能运行的主段的最大数量。
gp_vmem_protect_limit
gp_vmem_protect_limit = gp_vmem / acting_primary_segments - 不要将gp_vmem_protect_limit设置得过高或大于系统上的物理RAM。
- 根据计算出的gp_vmem值,计算出虚拟机的设置值。Overcommit_ratio操作系统参数:
vm.overcommit_ratio = (RAM - 0.026 * gp_vmem) / RAM - 使用statement_mem为每个段db分配用于查询的内存。
- 使用资源队列设置活动查询的数量(ACTIVE_STATEMENTS)和队列中查询可以使用的内存量(MEMORY_LIMIT)。
- 将所有用户与资源队列关联。不要使用默认队列。
- 设置PRIORITY,以匹配工作负载和时间对队列的实际需求。避免使用MAX优先级。
- 确保资源队列内存分配不超过gp_vmem_protect_limit的设置。
- 动态更新资源队列设置以匹配日常操作流。
分区
- 仅对大型表进行分区。不要对小表进行分区。
- 只有在可以根据查询条件实现分区消除(分区剪枝)时才使用分区。
- 选择范围分区而不是列表分区。
- 根据常用的列(如日期列)对表进行分区。
- 不要在同一列上对表进行分区和分布。
- 不要使用默认分区。
- 不要使用多级分区;创建更少的分区,每个分区中有更多的数据。
- 通过检查查询EXPLAIN计划,验证查询是否有选择地扫描分区表(正在消除分区)。
- 不要用面向列的存储创建太多分区,因为每个segment上的物理文件总数:物理文件=segment个数x列x分区
索引
- 一般来说,在Greenplum数据库中不需要索引。
- 在列表的单列上创建索引,用于钻取需要高选择性查询的高基数表。
- 不要对经常更新的列建立索引。
- 考虑在将数据加载到表中之前删除索引。加载完成后,为表重新创建索引。
- 创建选择性b树索引。
- 不要在已更新的列上创建位图索引。
- 避免对唯一列、基数非常高或基数非常低的数据使用位图索引。当列的基数较低(100到100,000个不同的值)时,位图索引的性能最好。
- 不要对事务性工作负载使用位图索引。
- 一般情况下,不要对分区表建立索引。如果需要索引,索引列必须不同于分区列。
资源队列
- 使用资源队列管理集群上的工作负载。
- 将所有角色与用户定义的资源队列关联。
- 使用ACTIVE_STATEMENTS参数限制特定队列成员可以并发运行的活动查询的数量。
- 使用MEMORY_LIMIT参数来控制通过队列运行的查询可以利用的内存总量。
- 动态更改资源队列以匹配工作负载和时间。
监控与维护
- 执行Greenplum数据库管理员指南中的“推荐的监控和维护任务”。
- 在安装时运行gpcheckperf,并在安装后定期运行,保存输出以比较一段时间内的系统性能。
- 使用您可以使用的所有工具来了解系统在不同负载下的行为。
- 检查任何异常事件以确定原因。
- 通过定期运行explain计划来监视系统上的查询活动,以确保查询以最佳方式运行。
- 检查计划,以确定是否正在使用索引,分区消除是否按预期进行。
- 了解系统日志文件的位置和内容,并定期监视它们,而不仅仅是在出现问题时进行监视。
analyze
- 确定是否确实需要分析数据库。如果gp_autostats_mode设置为on_no_stats(默认值),并且表没有分区,则不需要进行分析。
- 在处理大型表集时,优先使用analyzedb而不是ANALYZE,因为它不需要分析整个数据库。- analyzedb实用程序以增量和并发方式更新指定表的统计数据。对于追加优化的表,只有在统计信息不是当前的情况下,analyzedb才会增量更新统计信息。对于堆表,统计信息总是更新的。- ANALYZE不更新analyzedb实用程序用来确定表统计信息是否为最新的表元数据。
需要时,在表级别选择性地运行ANALYZE。 - 总是在INSERT、UPDATE之后运行ANALYZE。以及对底层数据进行重大修改的DELETE操作。
- 总是在CREATE INDEX操作之后运行ANALYZE。
- 如果在非常大的表上执行ANALYZE需要很长时间,那么只在连接条件、WHERE子句、SORT、GROUP BY或HAVING子句中使用的列上运行ANALYZE。
- 当处理大型表集时,使用analyzedb而不是ANALYZE。
- 在向分区表添加新分区时,在根分区上运行analyzedb。该操作同时分析子叶子分区,并将任何更新的统计信息合并到根分区中。
vacuum
- 在大的UPDATE和DELETE操作后运行VACUUM。
- 不要运行vacuum full。相反,运行CREATE TABLE…AS操作,然后重命名并删除原始表。
- 经常在系统catalog上运行VACUUM,以避免catalog膨胀,并且需要在catalog表上运行VACUUM FULL。
- 永远不要对catalog表上的VACUUM发出kill命令。
加载
- 随着segment数量的增加,并行度最大化。
- 将数据均匀地分布在尽可能多的ETL节点上。
- 将非常大的数据文件分成相等的部分,并将数据分散到尽可能多的文件系统中。
- 为每个文件系统运行两个gpfdist实例。
- 在尽可能多的接口上运行gpfdist。
- 使用gp_external_max_segs来控制将从gpfdist进程请求数据的segment的数量。
- 始终将gp_external_max_segs和gpfdist进程的数量保持为一个均匀因子。
- 总是在加载到现有表之前删除索引,并在加载后重新创建索引。
- 加载错误后执行VACUUM命令恢复空间。
安全
- 保护gpadmin用户id,只允许必要的系统管理员访问它。
- 管理员仅在执行某些系统维护任务(如升级、扩容)时使用gpadmin帐号登录Greenplum。
- 限制具有SUPERUSER角色属性的用户。超级用户角色绕过Greenplum数据库中的所有访问权限检查,以及资源排队。只有系统管理员才应该拥有超级用户权限。请参见《Greenplum数据库管理员指南》中的“修改角色属性”。
- 数据库用户不应该以gpadmin身份登录,ETL或生产工作负载也不应该以gpadmin身份运行。
- 为每个登录的用户、应用程序或服务分配一个不同的Greenplum Database角色。
- 对于应用程序或web服务,请考虑为每个应用程序或服务创建不同的角色。
- 使用组来管理访问权限。
- 保护root密码。
- 对操作系统密码实施强密码策略。
- 确保重要的操作系统文件受到保护。
加密
- 加密和解密数据有性能成本;只加密需要加密的数据。
- 在生产系统中实现任何加密解决方案之前进行性能测试。
- 生产环境Greenplum Database系统中的服务器证书应该由证书颁发机构(CA)签名,以便客户端- 可以对服务器进行身份验证。如果所有客户端对于组织来说都是本地的,那么CA可能是本地的。
- 只要连接通过不安全的链接,到Greenplum Database的客户端连接就应该使用SSL加密。
- 对称加密方案(使用相同的密钥进行加密和解密)比非对称加密方案具有更好的性能,应该在密钥可以安全共享的情况下使用。
- 使用加密函数对磁盘中的数据进行加密。数据在数据库进程中进行加密和解密,因此使用SSL保护客户端连接以避免传输未加密的数据非常重要。
- 在将ETL数据加载到数据库或从数据库卸载时,使用gpfdists协议来保护ETL数据。
高可用
- 建议使用8盘~ 24盘的硬件RAID存储方案。
- 请使用RAID 1、RAID 5或RAID 6来允许硬盘故障。
- 在磁盘阵列中配置热备,以便在检测到磁盘故障时自动开始重建。
- 通过镜像RAID卷,防止整个磁盘阵列的故障和重构过程中的降级。
- 定期监控磁盘利用率,并在需要时添加额外的空间。
- 监控segment倾斜以确保数据均匀分布,并且在所有段上均匀使用存储。
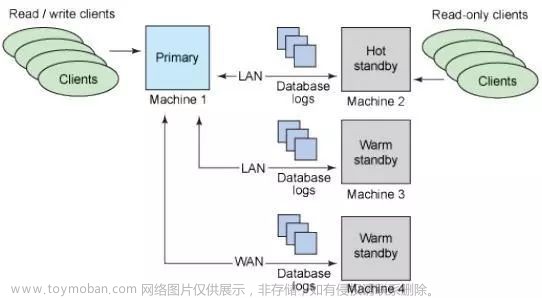
- 设置备用协调器实例,以便在主协调器发生故障时接管。
- 计划如何在发生故障时将客户端切换到新的协调器实例,例如,通过更新DNS中的协调器地址。
- 设置监视,以便在系统监视应用程序中发送通知,或者在主服务器发生故障时通过电子邮件发送通知。
- 为所有segment设置镜像。
- 在不同的主机上定位主segment及其镜像,防止主机故障。
- 使用gprecoverseg实用程序迅速恢复故障段,以恢复冗余并使系统恢复到最佳平衡。
- 考虑双集群配置,以提供额外级别的冗余和额外的查询处理吞吐量。
- 定期备份Greenplum数据库,除非数据很容易从数据源恢复。
- 如果备份保存到本地集群存储,则在备份完成后将文件移动到安全的集群外位置。
- 如果备份保存到NFS挂载,请使用横向扩展NFS解决方案(如Dell EMC Isilon)来防止IO瓶颈。
- 考虑使用Greenplum集成将备份流传输到Dell EMC Data Domain企业备份平台。
文章来源:https://www.toymoban.com/news/detail-687607.html
到了这里,关于Greenplum-最佳实践小结的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!