01 ChatGPT背后的基础设施:AI计算集群
早在2019年向 OpenAI 投资10亿美元的时候起,微软就同意为这家 AI 初创企业构建一台大型超级计算机。近期,微软在官博上连发两文,亲自解密了这台超级昂贵的超级计算机以及Azure的重磅升级。负责云计算和AI业务的微软副总裁 Scott Guthrie 表示,微软在这个项目上花费了数亿美元,将数以万计的 Nvidia A100 GPU 和 Azure 云计算平台串联在一起。
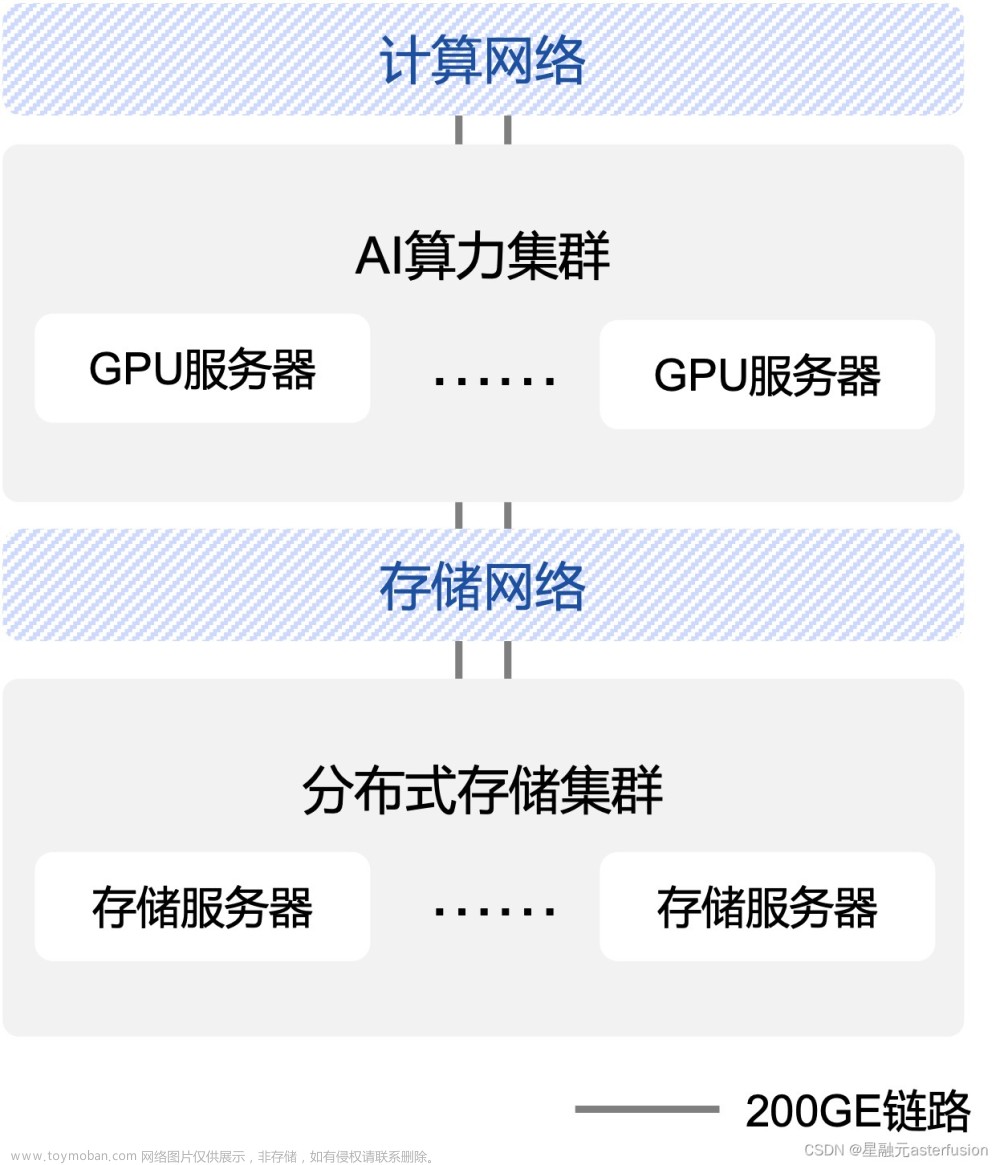
 对于诸如 ChatGPT 这类 AI 深度学习模型,巨量的高性能算力无疑是重中之重。但是人们常常容易忽略网络传输在AI训练提速中的作用。尤其是大规模集群分布式训练的场景下,网络扮演了一个极为关键的角色:为了训练一个大型语言模型,计算工作量被分配到集群中成千上万个 GPU 上,这就需要借助高吞吐、低时延的网络达成大算力芯片间的协同工作,以整合海量芯片的算力。
对于诸如 ChatGPT 这类 AI 深度学习模型,巨量的高性能算力无疑是重中之重。但是人们常常容易忽略网络传输在AI训练提速中的作用。尤其是大规模集群分布式训练的场景下,网络扮演了一个极为关键的角色:为了训练一个大型语言模型,计算工作量被分配到集群中成千上万个 GPU 上,这就需要借助高吞吐、低时延的网络达成大算力芯片间的协同工作,以整合海量芯片的算力。
我们从Azure面向“生成式AI”所做的基础设施升级也可以看到,网络互连能力在其中占据了很大比重。
微软推出了 ND H100 v5 虚拟机,它支持按需大小不等的 8 到数千个 NVIDIA H100 GPU,这些 GPU 通过 NVIDIA Quantum-2 InfiniBand 网络互连。与上一代 ND A100 v4 VM 相比,客户将看到人工智能模型的性能显着提高,这些创新技术包括:
- 8个NVIDIA H100 Tensor Core GPU通过下一代NVSwitch和NVLink 4.0互联
- 每个GPU有400 Gb/s的NVIDIA Quantum-2 CX7 InfiniBand,每个虚拟机有3.2Tb/s的无阻塞胖树型网络
- NVSwitch和NVLink 4.0在每个虚拟机的8个本地GPU之间具有3.6TB/s的双向带宽
- 第四代英特尔至强可扩展处理器
- PCIE Gen5到GPU互连,每个GPU有64GB/s带宽
- 16通道4800MHz DDR5 DIMM
02 微软所选择的InfiniBand,超低时延网络的唯一正解?
InfiniBand(简称IB)网络是通过 InfiniBand 交换机在节点之间直接创建一个专用的受保护通道,并通过 InfiniBand 网卡管理和执行远程直接内存访问(RDMA),与其他网络通信协议相比可以做到更低的延迟。
然而当前IB技术方案被少数海外供应商锁定的状态,给用户带来了诸多不便:首先是IB 交换机的供货周期过长,很容易影响到整体业务的正常上线,推迟的每一天都在白白损失已建成部分的投入成本;转入日常运维阶段后,IB网络的故障排查仍然高度依赖原厂,其售后响应速度也经常为人诟病。
像ChatGPT这类大规模AI计算集群网络,动辄便是上千卡级别的体量。AI大模型训练的固有需求之下,算力侧的成本优化空间相对有限,但如果能在网络侧寻找到与IB性能相近的平替方案,降低前期建设和后期运维等各方面投入,或许是个不错的思路。
自从RoCE(RoCEv2)出现以来,一些以前IB特有的技术比如 RDMA,协议卸载等,现在已经可以在以太网上应用了。不光是AI训练的后端网络,在科研超算、实时云服务、金融高频交易等场景,用优化后的以太网技术去替代 IB也渐渐具有了可行性。
03 低成本以太网代替IB网络的可行性
从网络架构来看,目前较为合适的是基于以太网的三层 CLOS 架构(Spine-leaf),在全盒式组网的情况下,任何两台服务器之间的通信不会超过三台交换机。
从网络层协议来看,下面几类 RDMA 网络中,RoCEv2 的性能较好、部署成本低、兼容性强;但受限于传统以太网“尽力而为”的特性,需要交换机支持构建一张零丢包、低延迟、高性能的无损网络。

星融元 CX-N 系列超低时延云交换机作为一款通用的以太网设备,从底层交换芯片到上层的各种协议栈皆面向低时延场景深度优化,可提供 Port to Port ~400ns 的转发时延,全速率下(10G~400G)转发时延相同,并且支持多种数据中心高级功能(如PFC、ECN等)以避免丢包和网络拥塞。
多个客户曾在现场用我们CX-N系列32 x 100G 的以太网交换机和 32 x 100G IB交换机(Mellanox SB7700)做对比测试,结果显示:CX-N系列以太网交换机的性能可以接近IB交换机,部分数据甚至比IB交换机更好。【详见文末附录】
综上:基于星融元CX-N系列云交换机搭建的超低时延无损以太网能够很好地承载RoCEv2,为用户打造一张高性价比的低时延网络。
【HPC场景】测试结果



【分布式存储场景】测试结果

文章来源地址https://www.toymoban.com/news/detail-687810.html
文章来源:https://www.toymoban.com/news/detail-687810.html
到了这里,关于大规模AI计算集群的网络环境需求,Infiniband还是超低时延以太网?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!