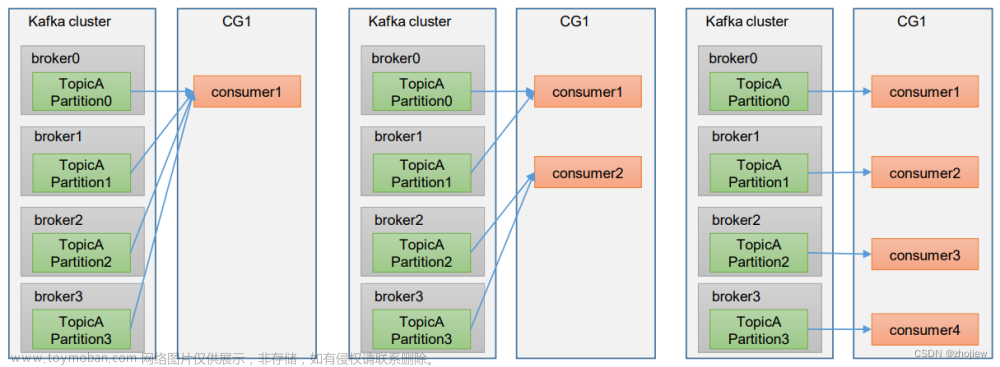
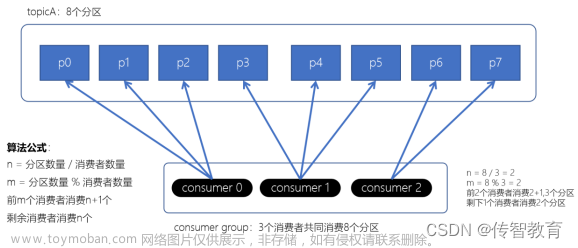
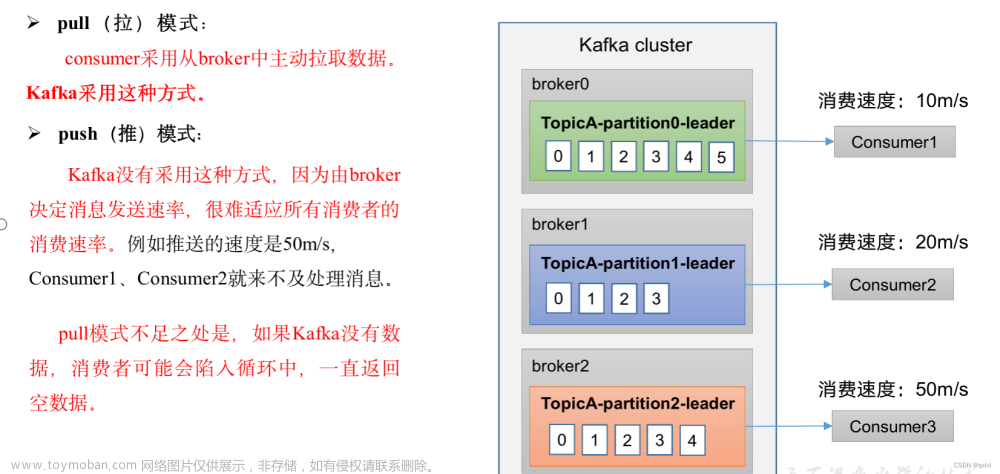
默认情况下,一个分区只能被消费者组中的一个消费者消费。但可以自定义PartitionAssignor来打破这个限制。
一、自定义PartitionAssignor.
package com.cisdi.dsp.modules.metaAnalysis.rest.kafka2023;
import org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class BroadcastAssignor extends AbstractPartitionAssignor {
@Override
public String name() {
return "broadcast";
}
private Map<String, List<String>> consumersPerTopic(Map<String, Subscription> consumerMetadata) {
Map<String, List<String>> res = new HashMap<>();
for (Map.Entry<String, Subscription> subscriptionEntry : consumerMetadata.entrySet()) {
String consumerId = subscriptionEntry.getKey();
for (String topic : subscriptionEntry.getValue().topics())
put(res, topic, consumerId);
}
return res;
}
@Override
public Map<String, List<TopicPartition>> assign(
Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
Map<String, List<String>> consumersPerTopic =
consumersPerTopic(subscriptions);
Map<String, List<TopicPartition>> assignment = new HashMap<>();
subscriptions.keySet().forEach(memberId ->
assignment.put(memberId, new ArrayList<>()));
consumersPerTopic.entrySet().forEach(topicEntry->{
String topic = topicEntry.getKey();
List<String> members = topicEntry.getValue();
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null || members.isEmpty())
return;
List<TopicPartition> partitions = AbstractPartitionAssignor
.partitions(topic, numPartitionsForTopic);
if (!partitions.isEmpty()) {
members.forEach(memberId ->
assignment.get(memberId).addAll(partitions));
}
});
return assignment;
}
}
二、定义两个消费者,给其配置上述PartitionAssignor.
package com.cisdi.dsp.modules.metaAnalysis.rest.kafka2023;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.time.temporal.TemporalUnit;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class KafkaTest19 {
private static Properties getProperties(){
Properties properties=new Properties();
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"xx.xx.xx.xx:9092");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"testGroup2023");
properties.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
BroadcastAssignor.class.getName());
return properties;
}
public static void main(String[] args) {
KafkaConsumer<String,String> myConsumer=new KafkaConsumer<String, String>(getProperties());
String topic="study2023";
myConsumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecords<String,String> consumerRecords=myConsumer.poll(Duration.ofMillis(5000));
for(ConsumerRecord record: consumerRecords){
System.out.println(record.value());
System.out.println("record offset is: "+record.offset());
}
}
}
}
package com.cisdi.dsp.modules.metaAnalysis.rest.kafka2023;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.time.temporal.TemporalUnit;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class KafkaTest20 {
private static Properties getProperties(){
Properties properties=new Properties();
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"xx.xx.xx.xx:9092");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"testGroup2023");
properties.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,
BroadcastAssignor.class.getName());
return properties;
}
public static void main(String[] args) {
KafkaConsumer<String,String> myConsumer=new KafkaConsumer<String, String>(getProperties());
String topic="study2023";
myConsumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecords<String,String> consumerRecords=myConsumer.poll(Duration.ofMillis(5000));
for(ConsumerRecord record: consumerRecords){
System.out.println(record.value());
System.out.println("record offset is: "+record.offset());
}
}
}
}
在kafka创建只有一个分区的topic : study2023
创建一个生产者往study2023这个 topic发送消息:
package com.cisdi.dsp.modules.metaAnalysis.rest.kafka2023;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class KafkaTest01 {
public static void main(String[] args) {
Properties properties= new Properties();
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"xx.xx.xx.xx:9092");
KafkaProducer<String,String> kafkaProducer=new KafkaProducer<String, String>(properties);
ProducerRecord<String,String> producerRecord=new ProducerRecord<>("study2023",0,"fff","hello sister,now is: "+ new Date());
Future<RecordMetadata> future = kafkaProducer.send(producerRecord);
long offset = 0;
try {
offset = future.get().offset();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(offset);
kafkaProducer.close();
}
}
分别运行生产者和消费者,可以看到相同消费者组里两个消费者可以消费study2023这个topic的同一个分区的数据 文章来源:https://www.toymoban.com/news/detail-687910.html
文章来源:https://www.toymoban.com/news/detail-687910.html
 文章来源地址https://www.toymoban.com/news/detail-687910.html
文章来源地址https://www.toymoban.com/news/detail-687910.html
到了这里,关于kafka复习:(22)一个分区只能被消费者组中的一个消费者消费吗?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!