Linux(实操篇三)
1. 常用基本命令
1.7 搜索查找类
1.7.1 find查找文件或目录
find 指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件显示在终端。
-
基本语法
find [搜索范围] [选项]
-
选项说明
- -name<查询方式> 按照指定的文件名查找模式查找文件
- -user<用户名> 查找属于指定用户名所有文件
- -size<文件大小> 按照指定的文件大小查找文件
- b —— 块(512 字节)
- c —— 字节
- w —— 字(2 字节)
- k —— 千字节
- M —— 兆字节
- G —— 吉字节
-
案例实操
按文件名:根据名称查找桌面目录下的txt文件
[guozihan@hadoop100 桌面]$ find -name “*.txt”
./a.txt按拥有者:查找/opt目录下,用户名称为guozihan的文件
[guozihan@hadoop100 桌面]$ find /opt -user guozihan
按文件大小:在/home目录下查找大于200m的文件(+n 大于 -n 小于 n 等于)
[guozihan@hadoop100 ~]$ find /home -size +204800
1.7.2 locate快速定位文件路径
locate 指令利用事先建立的系统中所有文件名称及路径的 locate 数据库实现快速定位给定的文件。Locate 指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新 locate 时刻
-
基本语法
locate 搜索文件
-
经验技巧
由于 locate 指令基于数据库进行查询,所以第一次运行前,必须使用 updatedb 指令创 建 locate 数据库。
-
案例实操
查询文件夹tmp
[root@hadoop100 guozihan]# updatedb
[root@hadoop100 guozihan]# locate tmp
1.7.3 grep过滤查找及"|"管道符
管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理
-
基本语法
grep 选项 查找内容 源文件
-
选项说明
-n 显示匹配行及行号
-
案例实操
查找某文件在第几行
[root@hadoop100 桌面]# ls
a.txt
[root@hadoop100 桌面]# ls | grep -n a.txt
1:a.txt
1.8 压缩和解压类
1.8.1 gzip/gunzip压缩
-
基本语法
gzip 文件 功能描述:压缩文件,只能将文件压缩为*.gz 文件
gunzip 文件.gz 功能描述:解压缩文件命令
-
经验技巧
(1)只能压缩文件不能压缩目录
(2)不保留原来的文件
(3)同时多个文件会产生多个压缩包
-
案例实操
gzip压缩
[guozihan@hadoop100 桌面]$ ls
a.txt test.txt[guozihan@hadoop100 桌面]$ gzip test.txt
[guozihan@hadoop100 桌面]$ ls
a.txt test.txt.gzgunzip解压缩文件
[guozihan@hadoop100 桌面]$ gunzip test.txt.gz
[guozihan@hadoop100 桌面]$ ls
a.txt test.txt
1.8.2 zip/unzip压缩
-
基本语法
zip [选项] XXX.zip 将要压缩的内容 功能描述:压缩文件和目录的命令
unzip [选项] XXX.zip 功能描述:解压缩文件
-
选项说明
zip选项
-r 压缩目录
unzip选项
-d<目录> 指定解压后文件的存放目录
-
经验技巧
zip 压缩命令在windows/linux都通用,可以压缩目录且保留源文件
-
案例实操
压缩 a.txt 和test.txt,压缩后的名称为mypackage.zip
[guozihan@hadoop100 桌面]$ zip mypackage.zip a.txt test.txt
adding: a.txt (deflated 47%)
adding: test.txt (stored 0%)[guozihan@hadoop100 桌面]$ ls
a.txt mypackage.zip test.txt解压 mypackage.zip
[guozihan@hadoop100 桌面]$ unzip mypackage.zip
Archive: mypackage.zip
replace a.txt? [y]es, [n]o, [A]ll, [N]one, [r]ename: y
inflating: a.txt
replace test.txt? [y]es, [n]o, [A]ll, [N]one, [r]ename: y
extracting: test.txt[guozihan@hadoop100 桌面]$ ls
a.txt mypackage.zip test.txt解压mypackage.zip到指定目录-d
[root@hadoop100 桌面]# unzip mypackage.zip -d /opt
Archive: mypackage.zip
inflating: /opt/a.txt
extracting: /opt/test.txt[root@hadoop100 桌面]# ls /opt/
a.txt rh test.txt
1.8.3 tar打包
-
基本语法
tar [选项] XXX.tar.gz 将要打包进去的内容 功能描述:打包目录,压缩后的 文件格式.tar.gz
-
选项说明
- -c 产生.tar打包文件
- -v 显示详细信息
- -f 指定压缩后的文件名
- -z 打包同时压缩
- -x 解包.tar 文件
- -C 解压到指定目录
-
案例实操
压缩多个文件
[guozihan@hadoop100 桌面]$ tar -zcvf package.tar.gz a.txt test.txt
a.txt
test.txt[guozihan@hadoop100 桌面]$ ls
a.txt mypackage.zip package.tar.gz test.txt压缩目录
[root@hadoop101 ~]# tar -zcvf xiyou.tar.gz xiyou/
xiyou/
xiyou/mingjie/
xiyou/dssz/
xiyou/dssz/houge.txt
解压到当前目录
[root@hadoop101 ~]# tar -zxvf houma.tar.gz
解压到指定目录
[root@hadoop101 ~]# tar -zxvf xiyou.tar.gz -C /opt
[root@hadoop101 ~]# ll /opt/
1.9 磁盘查看和分区类
1.9.1 du查看文件和目录占用的磁盘空间
du: disk usage 磁盘占用情况
-
基本语法
du 目录/文件 功能描述:显示目录下每个子目录的磁盘使用情况
-
选项说明
- -h 以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示
- -a 不仅查看子目录大小,还要包括文件
- -c 显示所有的文件和子目录大小后,显示总和
- -s 只显示总和
- –max-depth=n 指定统计子目录的深度为第 n 层
-
案例实操
查看当前用户主目录占用的磁盘空间大小
[guozihan@hadoop100 ~]$ du -sh
147M .
1.9.2 df查看磁盘空间使用情况
df: disk free 空余磁盘
-
基本语法
df 选项 功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况
-
选项说明
-h 以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示
-
案例实操
查看磁盘使用情况
[guozihan@hadoop100 ~]$ df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 13M 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda3 15G 4.7G 11G 31% /
/dev/sda1 1014M 208M 807M 21% /boot
tmpfs 394M 4.0K 394M 1% /run/user/42
tmpfs 394M 40K 394M 1% /run/user/1000
1.9.3 lsblk查看设备挂载
-
基本语法
lsblk 功能描述:查看设备挂载情况
-
选项说明
-f 查看详细的设备挂载情况,显示文件系统信息
1.9.4 mount/umount挂载/卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中包含了一整套的文件和目录,并将一个分区和一个目录联系起来, 要载入的那个分区将使它的存储空间在这个目录下获得。
-
前提条件
右键点击当前虚拟机设备->设置->点击CD/DVD(IDE)->将设备状态勾选已连接
-
基本语法
mount [-t vfstype] [-o options] device dir 功能描述:挂载设备
umount 设备文件名或挂载点 功能描述:卸载设备
-
参数说明
-
-t vfstype
指定文件系统的类型,通常不必指定。mount 会自动选择正确的类 型。常用类型有:
光盘或光盘镜像:iso9660
DOS fat16 文件系统:msdos
Windows 9x fat32 文件系统:vfat
Windows NT ntfs 文件系统:ntfs
Mount Windows 文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs
-
-o options
主要用来描述设备或档案的挂接方式。常用的参数有:
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
-
device:要挂接(mount)的设备
-
dir:设备在系统上的挂接点(mount point)
-
1.9.5 fdisk分区
-
基本语法
fdisk -l 功能描述:查看磁盘分区详情
fdisk 硬盘设备名 功能描述:对新增硬盘进行分区操作
-
选项说明
-l 显示所有硬盘的分区列表
-
经验技巧
该命令必须在 root 用户下才能使用
-
功能说明
-
Linux 分区
Device:分区序列
Boot:引导
Start:从X磁柱开始
End:到Y磁柱结束
Blocks:容量
Id:分区类型ID
System:分区类型
-
分区操作按键说明
m:显示命令列表
p:显示当前磁盘分区
n:新增分区
w:写入分区信息并退出
q:不保存分区信息直接退出
-
-
案例实操
查看系统分区情况
[root@hadoop100 ~]# fdisk -l
磁盘 /dev/sda:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x000d8ed6设备 Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 10487807 4194304 82 Linux swap / Solaris
/dev/sda3 10487808 41943039 15727616 83 Linux
1.10 进程管理类
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系统资源。
1.10.1 ps查看当前系统进程状态
ps:process status 进程状态
-
基本语法
ps aux | grep xxx 功能描述:查看系统中所有进程
ps -ef | grep xxx 功能描述:可以查看子父进程之间的关系
-
选项说明
- a 列出带有终端的所有用户的进程
- x 列出当前用户的所有进程,包括没有终端的进程
- u 面向用户友好的显示风格
- -e 列出所有进程
- -u 列出某个用户关联的所有进程
- -f 显示完整格式的进程列表
-
功能说明
-
ps aux 显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的 ID 号
%CPU:该进程占用 CPU 资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位 KB;
RSS:该进程占用实际物理内存的大小,单位 KB;
TTY:该进程是在哪个终端中运行的。对于 CentOS 来说,tty1 是图形化终端,
tty2-tty6 是本地的字符界面终端。pts/0-255 代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行状态、S:睡眠状态、T:暂停状态、 Z:僵尸状态、s:包含子进程、l:多线程、+:前台显示
START:该进程的启动时间
TIME:该进程占用 CPU 的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
-
ps -ef 显示信息说明
UID:用户 ID
PID:进程 ID
PPID:父进程 ID
C:CPU 用于计算执行优先级的因子。数值越大,表明进程是 CPU 密集型运算, 执行优先级会降低;数值越小,表明进程是 I/O 密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU 时间
CMD:启动进程所用的命令和参数
-
-
经验技巧
如果想查看进程的 CPU 占用率和内存占用率,可以使用 aux;
如果想查看进程的父进程 ID 可以使用 ef;
-
案例实操
[guozihan@hadoop100 ~]$ ps aux
[guozihan@hadoop100 ~]$ ps -ef
1.10.2 kill终止进程
-
基本语法
kill [选项] 进程号 功能描述:通过进程号杀死进程
killall 进程名称 功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用
-
选项说明
-9 表示强迫进程立即停止
-
案例实操
通过进程ID杀死进程
[guozihan@hadoop100 ~]$ kill -9 10773
通过进程名称杀死进程
[guozihan@hadoop100 ~]$ killall firefox
1.10.3 pstree查看进程树
-
基本语法
pstree [选项]
-
选项说明
-p 显示进程的 PID
-u 显示进程的所属用户
-
案例实操
显示进程 pid
[guozihan@hadoop100 ~]$ pstree -p
显示进程所属用户
[guozihan@hadoop100 ~]$ pstree -u
1.10.4 top实时监控系统进程状态
-
基本命令
top [选项]
-
选项说明
-d 秒数 指定 top 命令每隔几秒更新。默认是 3 秒在 top 命令的交互模式当 中可以执行的命令
i 使 top 不显示任何闲置或者僵死进程
-p 通过指定监控进程 ID 来仅仅监控某个进程的状态
-
操作说明
P 以 CPU 使用率排序,默认就是此项
M 以内存的使用率排序
N 以 PID 排序
q 退出 top
-
查询结果字段解释




-
案例实操
[guozihan@hadoop100 ~]$ top -d 1
[guozihan@hadoop100 ~]$ top -i
[guozihan@hadoop100 ~]$ top -p 2575
执行上述命令后,可以按 P、M、N 对查询出的进程结果进行排序
1.10.5 netstat 显示网络状态和端口占用信息
-
基本语法
netstat -anp | grep 进程号 功能描述:查看该进程网络信息
netstat –nlp | grep 端口号 功能描述:查看网络端口号占用情况
-
选项说明
-a 显示所有正在监听(listen)和未监听的套接字(socket)
-n 拒绝显示别名,能显示数字的全部转化成数字
-l 仅列出在监听的服务状态
-p 表示显示哪个进程在调用
-
案例实操
通过进程号查看sshd进程的网络信息
[root@hadoop100 guozihan]# netstat -anp | grep sshd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1162/sshdtcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 2796/sshd: guozihan
tcp 0 0 192.168.182.100:22 192.168.182.1:51375 ESTABLISHED 2788/sshd: guozihan
tcp6 0 0 :::22 ::😗 LISTEN 1162/sshdtcp6 0 0 ::1:6010 ::😗 LISTEN 2796/sshd: guozihan
unix 3 [ ] STREAM CONNECTED 42723 2796/sshd: guozihanunix 3 [ ] STREAM CONNECTED 29707 1162/sshd
unix 3 [ ] STREAM CONNECTED 42724 2788/sshd: guozihan
unix 2 [ ] DGRAM 42720 2788/sshd: guozihan
查看某端口号是否被占用
[root@hadoop100 guozihan]# netstat -nltp | grep 22
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 1464/dnsmasqtcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1162/sshd
tcp6 0 0 :::22 ::😗 LISTEN 1162/sshd
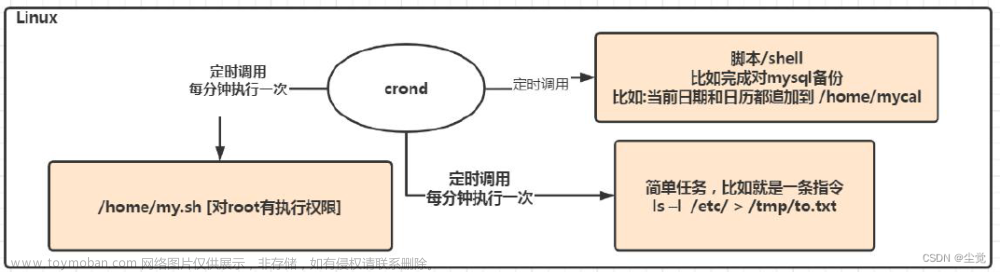
1.11 crontab系统定时任务
1.11.1 crontab服务管理
重新启动 crond 服务
[root@hadoop101 ~]# systemctl restart crond
1.11.2 crontab定时任务设置
-
基本语法
crontab [选项]
-
选项说明
-e 编辑 crontab 定时任务
-l 查询 crontab 任务
-r 删除当前用户所有的 crontab 任务
-
参数说明



-
实例实操
每隔 1 分钟,向/root/bailongma.txt 文件中添加一个 11 的数字文章来源:https://www.toymoban.com/news/detail-688793.html
*/1 * * * * /bin/echo ”11” >> /root/bailongma.txt文章来源地址https://www.toymoban.com/news/detail-688793.html
到了这里,关于Linux(实操篇三)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!