分析&回答
这是 Flink 相关工作中最常出现的问题,值得大家搞明白。
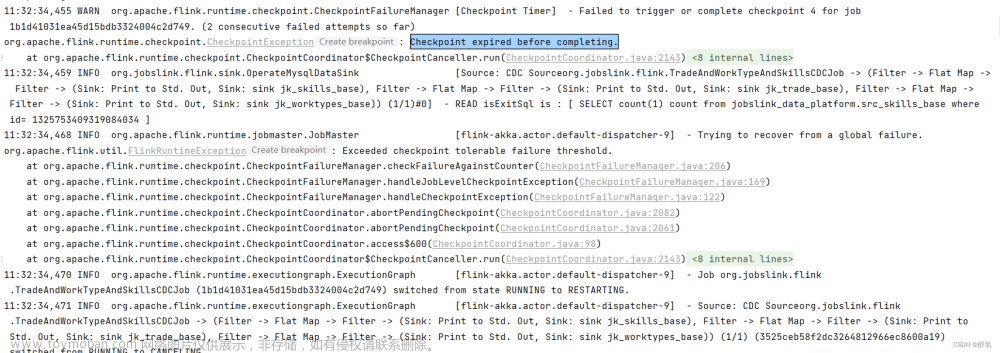
1. 先找到超时的subtask序号
图有点问题,因为都是成功没失败的,尴尬了。

借图:

2. 找到对应的机器和任务
方法很多,这里看自己习惯和公司提供的系统。
3. 根据日志排查问题
- netstat -nap| grep 端口号 就找到对应的pid了,
- 然后ps aux | grep pid 就找到任务目录和日志了。
比如下一种情况:
- 接着去jobmanager上查看这个checkpoint的一些延迟信息
- 根据这些失败的task的id去查询这些任务落在哪一个taskmanager上,经过排查发现,是同一台机器,通过ui看到该机器流入的数据明显比别的流入量大
- 因此是因为数据倾斜导致了这个问题,追根溯源还是下游消费能力不足的问题
反思&扩展
Flink Checkpoint 失败有很多种原因,常见的失败原因如下:
- 用户代码逻辑没有对于异常处理,让其直接在运行中抛出。比如解析 Json 异常,没有捕获,导致 Checkpoint失败,或者调用 Dubbo 超时异常等等。
- 依赖外部存储系统,在进行数据交互时,出错,异常没有处理。比如输出数据到 Kafka、Redis、HBase等,客户端抛出了超时异常,没有进行捕获,Flink 任务容错机制会再次重启。
- 内存不足,频繁GC,超出了 GC 负载的限制。比如 OOM 异常
- 网络问题、机器不可用问题等等。
Checkout 在 Flink 中非常重要,其他指标大家也需要多关注。
 文章来源:https://www.toymoban.com/news/detail-689010.html
文章来源:https://www.toymoban.com/news/detail-689010.html
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!文章来源地址https://www.toymoban.com/news/detail-689010.html
到了这里,关于如何排查 Flink Checkpoint 失败问题?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!