文章来源地址https://www.toymoban.com/news/detail-689132.html
目录
1、直接寻址表
2、直接寻址表缺点
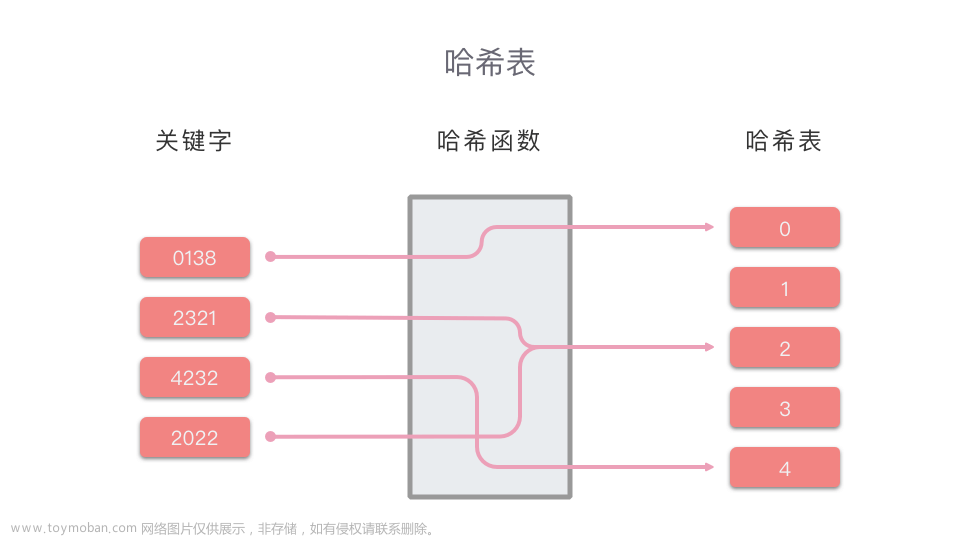
3、哈希
4、哈希表
5、解决哈希冲突
6、拉链法
7、常见哈希函数
8、哈希表的实现
8.1迭代器iter()和__iter__
8.2str()和repr()
8.3代码实现哈希表
8.4哈希表的应用

1、直接寻址表

2、直接寻址表缺点

3、哈希
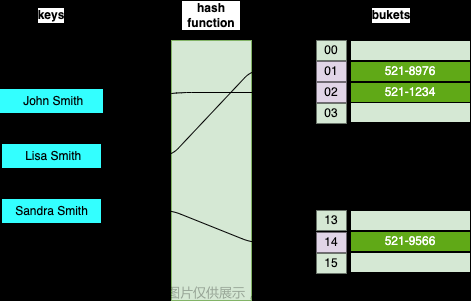
- 直接寻址表:key为k的元素放到k的位置上
- 改进直接寻址表:哈希(Hashing)
- 构建大小为m的寻址表T
- key为k的元素放到h(k)的位置上
- h(k)是一个函数,其将域U映射到表T[0,1,2,...,m-1]
4、哈希表

5、解决哈希冲突

6、拉链法

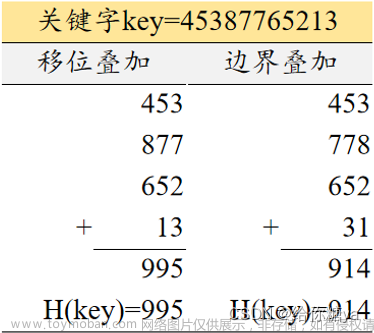
7、常见哈希函数

8、哈希表的实现
8.1迭代器iter()和__iter__
- 从根本上说,迭代器就是有一个next()方法的对象,而不是通过索引来计数。
- 迭代器更大的功劳是提供了一个统一的访问集合的接口。
- 迭代器为类序列对象提供了一个类序列的接口。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
- 迭代器只能往前不会后退。
- python的迭代无缝地支持序列对象,而且它还允许程序员迭代非序列类型,包括用户定义的对象。
- 迭代器用起来很灵巧,你可以迭代不是序列但表现出序列行为的对象,例如字典的键、一个文件的行。
def iter_test():
i = iter('happy')#!!!
try:
while True:
print i.next()
except StopIteration:
pass
s = {'one':1,'two':2,'three':3}
print s
m = iter(s) #!!!
try:
while True:
print m.next() #s[m.next()]
except StopIteration:
pass
if __name__ == '__main__':
iter_test()h
a
p
p
y
{'three': 3, 'two': 2, 'one': 1}
three
two
one- 使用类实现
__iter__()和next()函数 - 另一个创建迭代器的方法是使用类,一个实现了
__iter__()和next()方法的类可以作为迭代器使用。 - next方法:返回迭代器的下一个元素
- __iter__方法:返回迭代器对象本身
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def next(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 10: # 退出循环的条件
raise StopIteration();
return self.a # 返回下一个值
if __name__ == '__main__':
for n in Fib():
print n 1
1
2
3
5
88.2str()和repr()
- Python 内置函数
repr()和str()分别调用对象的__repr__和__str__ -
repr()更能显示出对象的类型、值等信息,对象描述清晰的。 而str()能够让我们最快速了解到对象的内容,可读性较高 - 在 Python 交互式命令行下直接输出对象默认使用的是
__repr__
import datetime
s = 'hello'
d = datetime.datetime.now()
print(str(s))
print(repr(s))
print(str(d))
print(repr(d))hello
'hello'
2023-6-13 22:39:18.014587
datetime.datetime(2023, 6, 13, 22, 39, 18, 14587)Note:
- map()函数
def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]8.3、代码实现哈希表
# hash
class Linklist:
class Node:
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
def __init__(self, node):
self.node = node
def __next__(self):
if self.node:
cur_node = self.node
self.node = cur_node.next
return cur_node.item
else:
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None):
self.head = None
self.tail = None
if iterable:
self.extend(iterable)
def append(self, obj):
s = Linklist.Node(obj)
if not self.head:
self.head = s
self.tail = s
else:
self.tail.next = s
self.tail = s
def extend(self, iterable):
for obj in iterable:
self.append(obj)
def find(self, obj):
for n in self:
if n == obj:
return True
else:
return False
def __iter__(self):
return self.LinkListIterator(self.head)
def __repr__(self):
return "<<" + ",".join(map(str, self)) + ">>"
# 类似于集合的结构
class HashTable:
def __init__(self, size=101):
self.size = size
self.T = [Linklist() for i in range(self.size)]
def h(self, k):
return k % self.size
def insert(self, k):
i = self.h(k)
if self.find(k):
print("Douplicated insert")
else:
self.T[i].append(k)
def find(self, k):
i = self.h(k)
return self.T[i].find(k)
lk = Linklist([1, 2, 3, 4])
print(lk)
ht = HashTable()
ht.insert(0)
ht.insert(1)
# hash
class Linklist:
class Node:
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
def __init__(self, node):
self.node = node
def __next__(self):
if self.node:
cur_node = self.node
self.node = cur_node.next
return cur_node.item
else:
raise StopIteration
def __iter__(self):
return self
def __init__(self, iterable=None):
self.head = None
self.tail = None
if iterable:
self.extend(iterable)
def append(self, obj):
s = Linklist.Node(obj)
if not self.head:
self.head = s
self.tail = s
else:
self.tail.next = s
self.tail = s
def extend(self, iterable):
for obj in iterable:
self.append(obj)
def find(self, obj):
for n in self:
if n == obj:
return True
else:
return False
def __iter__(self):
return self.LinkListIterator(self.head)
def __repr__(self):
return "<<" + ",".join(map(str, self)) + ">>"
# 类似于集合的结构
class HashTable:
def __init__(self, size=101):
self.size = size
self.T = [Linklist() for i in range(self.size)]
def h(self, k):
return k % self.size
def insert(self, k):
i = self.h(k)
if self.find(k):
print("Douplicated insert")
else:
self.T[i].append(k)
def find(self, k):
i = self.h(k)
return self.T[i].find(k)
lk = Linklist([1, 2, 3, 4])
print(lk)
ht = HashTable()
ht.insert(0)
ht.insert(1)
ht.insert(3)
ht.insert(102)
print(",".join(map(str, ht.T)))
结果
<<1,2,3,4>>
<<1,2,3,4>>
<<0>>,<<1,102>>,<<>>,<<3>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>,<<>>
Process finished with exit code 08.4、哈希表的应用

MD5算法




文章来源:https://www.toymoban.com/news/detail-689132.html
到了这里,关于Python篇——数据结构与算法(第六部分:哈希表)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!