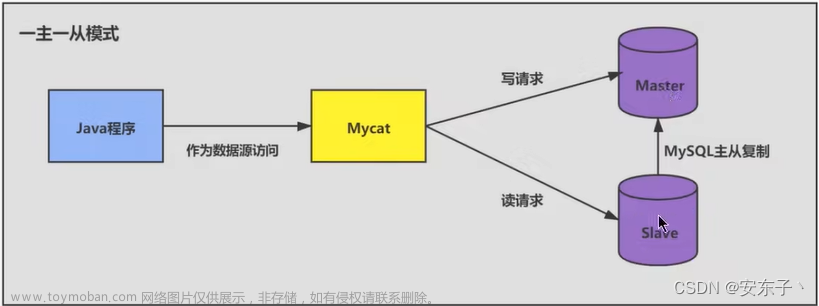
业务场景1:几千万数据量的工单表快速优化
数据库分区技术:
数据库分区并不是生成一个新的表,而是将表的数据均衡分配到不同的磁盘,系统或不同的服务器存储介质中,实际上还是一张表。业务代码不需要做任何改动。
数据库分区的优点:比起单个文件系统或硬盘,分区可以存储更多的数据。
在清理数据时,可以直接删除废弃数据所在的分区。
可以大幅度的提升查询效率,类似于分库分表,比如说有2000万的数据,分成10个分区,每个分区就只有200万的数据,那么我查询的时候,也就只查这200万的数据。
缺点:数据库分区有个限制,分区字段必须是唯一索引,也就是说我的所有的查询条件都得带上这个唯一索引,来告诉数据库,去查询哪个分区。而且这种方案更加依托于dba团队,又是将压力给到了数据库,所以这种方案基本上不使用。但是也有个好处就是,不需要引入其他框架,仅仅靠数据库就能实现。
冷热分离的简介:
冷热分离就是在处理数据的时候,将数据分为冷库和热库,冷库存放到走到终态的数据,不经常使用的数据,热库存放还需要修改和经常使用的数据。
什么情况下我们可以使用冷热分离:
1,数据走到终态后,只有读的需求,没有写的需求,比如说订单走到终态,就不会再有状态变更。
2,用户能接受新旧数据分开查询,比如某些电商默认只让查3个月以内的订单,要想查询3个月以外的,就得访问其他的页面。也就是说不会出现同时查询冷、热数据的需求。
冷热分离的实现思路:
一、冷热数据都用mysql
需要考虑的问题:
1,怎么判断一个数据用冷数据还是热数据
一般情况下我们可以根据主表的字段来确定,比如说创建时间,状态。在我们使用的过程中,具体怎么区分冷数据和热数据,还得根据具体的业务需要、
2,如何触发冷热分离
触发冷热分离有三种方案
1,业务代码来实现。当表的数据变更时,每次变更都进行一次判断,看看能不能进入到冷库,如果能,就放到冷库,删除热库数据(实时性最强,改动最大)
2,通过监听mysql的binlog日志(低延迟)
3,通过定时任务,定时扫描,将能放到冷库的数据进行归档(高延时,不能做到实时性)
3,如何实现冷热分离
实现冷热分离就是判断数据是否能进入到冷库,如果能,插入冷数据,删除热数据,但是需要我们注意几点:
1,事务一致性问题:需要我们研发做好兜底方案。
最常用的就是加一个字段,用来标志数据是否可以进入到冷数据,然后定时任务每天去扫描看看数据是否一致。
2,数据量大的问题
可以采用批处理的方式,即一次性可以对多条数据进行处理
3,并发处理
当数据非常大的时候,采用批处理也达不到要求,就要采用多线程,这里要做好锁,可以用数据库锁来实现。
4,如何使用冷热分离
可以根据前端页面来区分
5,历史数据如何迁移
可以编写java程序来进行迁移,如果采用的是定时任务方案,不需要关注。
二、冷数据存放到hbase
上面第一期,冷热数据都用mysql,存在两个问题:
用户还是会存在查询冷数据的场景。并且用户在查询冷数据的时候依旧很慢。
那么就需要一种数据库,可以存放上亿的数据,并且支持简单的组合关键字查询,并且存放的数据不会在变更。所以我们采用hbase来实现。
hbase是一种天然支持分布式的数据库,因为他是非关系型数据库,每个表之间都没有实际的联系,hbase同一行的数据没有存放到一起,所以hbase只能做一些简单的查询,实现不了复杂的查询。文章来源:https://www.toymoban.com/news/detail-689439.html
冷热分离的弊端:
对业务要求非常高,要求冷热数据不能同时查询,冷数据不能被修改,冷数据不能进行复杂的查询,但是他的性价比非常高,可以快速的实现项目的优化。文章来源地址https://www.toymoban.com/news/detail-689439.html
到了这里,关于数据库调优 --- 冷热分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!