一、在IDEA中执行以下语句

或者用windows徽标+R 输入cmd 进入命令提示符

输入scala直接进入编写界面

1、Scala的常用数据类型
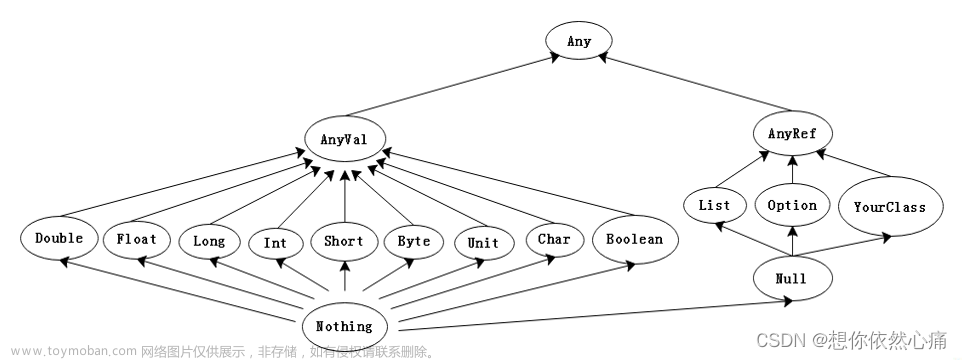
注意:在Scala中,任何数据都是对象。例如:
scala> 1
res0: Int = 1
scala> 1.toString
res1: String = 1
scala> "1".toInt
res2: Int = 1
scala> "abc".toInt
java.lang.NumberFormatException: For input string: "abc"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at scala.collection.immutable.StringLike$class.toInt(StringLike.scala:272)
at scala.collection.immutable.StringOps.toInt(StringOps.scala:29)
... 32 elided1. 数值类型:Byte,Short,Int,Long,Float,Double
Byte: 8位有符号数字,从-128 到 127
Short: 16位有符号数据,从-32768 到 32767
Int: 32位有符号数据
Long: 64位有符号数据
例如:
val a:Byte = 10
a+10
得到:res9: Int =
这里的res9是新生成变量的名字
val b:Short = 20
a+b
注意:在Scala中,定义变量可以不指定类型,因为Scala会进行类型的自动推导。
2. 字符类型和字符串类型:Char和String
对于字符串,在Scala中可以进行插值操作。
scala> val s1="Hello World"
s1: String = Hello World
scala> "My Name is ${s1}"
res4: String = My Name is ${s1}
scala> s"My Name is ${s1}"
res5: String = My Name is Hello World3. Unit类型:相当于Java中的void类型
scala> val f=()
f: Unit = ()
scala> val f={}
f: Unit = ()4. Nothing类型:一般表示在执行过程中,产生了Exception
例如,我们定义一个函数如下:
scala> def myfunction=throw new Exception("Some Error")
myfunction: Nothing2、Scala变量的申明和使用
使用val和var申明变量
例如:scala> val answer = 8 * 3 + 2 可以在后续表达式中使用这些名称
val:定义的值实际是一个常量
要申明其值可变的变量:var
注意:可以不用显式指定变量的类型,Scala会进行自动的类型推到
3、Scala的函数和方法的使用
可以使用Scala的预定义函数
例如:求两个值的最大值
scala> max(1,2)
<console>:12: error: not found: value max
max(1,2)
^
scala> import scala.math._
import scala.math._
scala> max(1,2)
res7: Int = 2
scala> var result:Int=max(1,2)
result: Int = 2也可以使用def关键字自定义函数
语法:

//求两个参数的和
def sum(x:Int,y:Int):Int=x+y
sum(1,2)
var d=sum(1,2)
//求每个数学的阶乘
def myFactor(x:Int):Int={
//采用递归算法得到阶乘
//注意:在SCALA 中,if..else 是一个表达式,所有有返回值,相当于省略的return
if (x<=1)
1
else
x*myFactor(x-1)
}
myFactor(5)4、Scala的条件表达式
Scala的if/else语法结构和Java或C++一样。
不过,在Scala中,if/else是表达式,有值,这个值就是跟在if或else之后的表达式的值。
5、Scala的循环
Scala拥有与Java和C++相同的while和do循环
Scala中,可以使用for和foreach进行迭代
使用for循环案例:
//定义一个集合
var list=List("Mary","Tom","Mike")
println("************for 第一种写法************")
for (s<-list) println(s)
println("************for 第二种写法************")
for {
s<-list
if(s.length>3)
} println(s)
println("************for 第三种写法************")
for (s<-list if s.length<=3) println(s)注意:
(*) <- 表示Scala中的generator,即:提取符
(*)第三种写法是第二种写法的简写
在for循环中,还可以使用yield关键字来产生一个新的集合
//定义一个集合
var list=List("Mary","Tom","Mike")
println("************for 第四种写法************")
var newList= for {
s<-list
s1=s.toUpperCase
} yield (s1)使用while循环:注意使用小括号,不是中括号
println("************while 循环************")
var i=0
while(i<list.length){
println(list(i))
i+=1
}使用do ... while循环
println("************do while 循环************")
var i=0
do {
println(list(i))
i+=1
}while (i<list.length)使用foreach进行迭代
scala> val list=List("Mary","Tom","Mike")
list: List[String] = List(Mary, Tom, Mike)
scala> list.foreach(println)
Mary
Tom
Mike注意:在上面的例子中,foreach接收了另一个函数(println)作为值
6、Scala函数的参数
Scala中,有两种函数参数的求值策略
Call By Value:对函数实参求值,且仅求一次
Call By Name:函数实参每次在函数体内被用到时都会求值
//Scala中函数参数的求值策略
// 1.call by value
def test1(x:Int,y:Int):Int=x+x
test1(3+4,8)
//2. call by name
def test2(x: => Int,y: =>Int):Int=x+x
test2(3+4,8)稍微复杂一点的例子:
x是call by value,y是call by name
def bar(x:Int,y: => Int):Int = 1
定义一个死循环
def loop():Int = loop
调用:
bar(1,loop) //输出1
bar(loop,1) //死循环
我们来分析一下,上面两个调用执行的过程:

Scala中的函数参数
默认参数
代名参数
可变参数
//默认参数
def func1(name:String="Tom"):String ="Hello "+name
func1()
func1("marry")
//带名参数
def func2(str:String="Good Morning",name:String="Tom",age:Int=20)=str+name+" and the age of "+name + " is "+age
func2()
func2(age=25)
//变长参数:求多个数字的和
def sum(args:Int*)={
var result=0
for(arg<-args) result+=arg
result
}7、Scala的Lazy值(懒值)
当val被申明为lazy时,它的初始化将被推迟,直到我们首次对它取值。
val x:Int =10
//定义y的时候才有lazy来休息,在定义它时候不会对其运算
lazy val y:Int=x+1
//第一次使用的时候,才会对其求值
y一个更为复杂一点的例子:读取文件:
//第一次读取一个存在的文件
val words=scala.io.Source.fromFile("d:\\temp\\a.txt").mkString
lazy val words1=scala.io.Source.fromFile("d:\\temp\\a.txt").mkString
words1
//第二次读取一个不存在的文件,这时不会报错
lazy val words2=scala.io.Source.fromFile("d:\\temp\\abc.txt").mkString
//第一次调用的时候,才会对其运算,才会出现Exception
words28、异常的处理
Scala异常的工作机制和Java或者C++一样。直接使用throw关键字抛出异常。
使用try...catch...finally来捕获和处理异常:
//1.采用 try catch finally 来捕获异常和处理异常
try{
val words=scala.io.Source.fromFile("d:\\temp\\abc.txt").mkString
} catch {
case ex:java.io.FileNotFoundException => {
println("File Not Found")
}
case ex:IllegalArgumentException => {
println("Illegal Argument Exception")
}
case _:Exception =>{
println("*****Other Exception ****")
}
}finally {
println("****** final block ******")
}
//2.如果一个函数的返回类型是Nothing, 表示:在函数执行的过程中产生异样
def func1()=throw new IllegalArgumentException("Some Error Happened")
//3.if else 语句:如果在一个分支中产生了异常,则另外一个分支的返回值,将作为 if else 返回值的类型
val x=10
if(x>10){
scala.math.sqrt(x)
}else{
throw new IllegalArgumentException("The value should be not")
}9、Scala中的数组
Scala数组的类型:
定长数组:使用关键字Array
//定长数组
val a=new Array[Int](10)
val b=new Array[String](5)
val c=Array("Tom","Mary","Mike")变长数组:使用关键字ArrayBuffer
//变长数组: ArrayBuffer
val d = scala.collection.mutable.ArrayBuffer[Int] ()
//往变长数组中加入元素
d+=1
d+=2
d+=3
//往变长数组中加入多个元素
d+=(10,12,13)
//去掉最后两个值
d.trimEnd(2)
d.trimStart(2)
//将ArrayBuffer 转换成Array
d.toArray遍历数组
//遍历数组
var a=Array("Tom","Mary","Mike")
//使用for 循环进行遍历
for (s<-a) println(s)
//对数组进行转换,新生成一个数组 yield
val b = for {
s<-a
s1=s.toUpperCase
}yield (s1)
//可以使用foreach进行循环输出
a.foreach(println)
b.foreach(println)Scala数组的常用操作
import scala.collection.mutable.ArrayBuffer
val myArray = Array(1,10,2,3,5,4)
//求最大值
myArray.max
//求最小值
myArray.min
//求和
myArray.sum
//定义一个变长数组
var myArray1=ArrayBuffer(1,10,2,3,5,4)
//排序
myArray1.sortWith(_ > _)
//升序
myArray1.sortWith(_ < _)Scala的多维数组
和Java一样,多维数组是通过数组的数组来实现的。
也可以创建不规则的数组,每一行的长度各不相同。
//定义一个固定长度的二维数组
val matrix = Array.ofDim[Int](3,4)
matrix(1)(2)=10
matrix
//定义一个二维数组,其中每个元素是一个一维数组,其长度不固定
val triangle = new Array[Array[Int]](10)
//通过一个循环赋值
for(i<-0 until( triangle.length)) triangle(i)=new Array[Int](i+1)
//观察这个二维数组中的每一个元素的长度
triangle10、映射
映射就是Map集合,由一个(key,value)组成。
-> 操作符用来创建
映射的类型分为:不可变Map和可变Map
//不可变得Map
val math = scala.collection.immutable.Map("Alice"->80,"Bob"->95,"Mary"->70)
//可变的Map
val english = scala.collection.mutable.Map("Alice"->80,"Bob"->95,"Mary"->70)
val chinese = scala.collection.mutable.Map(("Alice",80),("Bob",95),("Mary",70))映射的操作
获取映射中的值
//1.获取Map中的值
chinese("Bob") //chinese.get("Bob")
//chinese("Tom") 如果不存在,会抛出 Exception
//Map.constains 判断可以时候存在
if(chinese.contains("Alice")){
chinese("Alice")
}else{
-1
}
//简写
chinese.getOrElse("Alice",-1)迭代映射
//迭代映射
for (s<-chinese) println(s)
chinese.foreach(println)11、元组(Tuple)
元组是不同类型的值的聚集。
例如:val t = (1, 3.14, "Fred") // 类型为Tuple3[Int, Double, java.lang.String]
这里:Tuple是类型,3是表示元组中有三个元素。文章来源:https://www.toymoban.com/news/detail-689689.html
元组的访问和遍历:文章来源地址https://www.toymoban.com/news/detail-689689.html
//定义tuple,包含3个元素
val t1=(1,2,"Tom")
val t2= new Tuple4("Mary",3.14,100,"Hello")
//访问tuple中的组员 _1
t2._1
t2._2
t2._3
t2._4
//t2._5 ---->error
//遍历 Tuple: for foreach ???
t2.productIterator.foreach(println)
//注意:要遍历Tuple中的元素,需要首先生成对应的迭代器,不能直接使用for 或者 foreach到了这里,关于2023_Spark_实验四:SCALA基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!