摘要:本文整理自阿里云高级开发工程师曾庆栋(曦乐)在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分:
- 传统数据仓库分析实现方案简介
- Paimon+StarRocks 构建湖仓一体数据分析实现方案
- StarRocks 与 Paimon 结合的使用方式与实现原理
- StarRocks 社区湖仓分析未来规划
点击查看原文视频 & 演讲PPT文章来源地址https://www.toymoban.com/news/detail-689906.html
一、传统数据仓库分析实现方案简介
传统数据仓库分析的实现是一个典型 Lambda 架构,通过下图我们可以看出传统架构主要分为两层:上层是实时链路层,下层是离线链路层。它们的数据通过左侧的数据摄入层,通过不同路径将数据统一整合到像 Kafka 这样的消息队列中间件中,然后将数据分为两份相同的数据,分别由实时链路和批量链路进行处理,最终汇总到数据服务层,实现对用户提供数据分析服务的能力。

Lambda 架构的出现主要是因为用户对于实时分析需求的出现,以及流处理技术的逐渐成熟。但是它也有一些明显的弊端,如上图所示,它需要维护两套系统,这就会导致部署成本和人力成本都会增加。当业务变更的时候,也需要修改两套系统来适应业务的变化。
随着流处理技术的逐渐成熟,Lambda 架构之后又推出了 Kappa 架构,如下图所示。

Kappa 架构是使用流处理链路来代替原来的 Lambda 架构,因为流处理的成熟,所以通过一套系统去完成实时和离线的计算成为可能。
Kappa 架构有一个前提,它认为对于历史数据的重复计算,在非必要的情况下是不用进行的。这就使得当用户需要重新计算历史数据或是出现新业务变动的时候,往往需要将整个数据摄入阶段的过程重放一次。在大量消费历史数据的情况下,必然造成资源浪费,并遇到一些瓶颈。
二、Paimon+StarRocks 构建湖仓一体数据分析实现方案
2.1 数据湖中心
第一个方案是 Paimon 和 StarRocks 构建湖仓一体数据分析的数据湖中心方案。

StarRocks 本身是一个 MPP 的数据库,同时可以外接多种格式的数据湖组件,可以以单纯作为查询引擎去外接数据湖组件,实现查询功能。如上图,通过 StarRocks 或 Spark 都可以对 ODS 等数据层的 Paimon 组件进行查询。
在这个架构里,Paimon 通过对数据的落盘和索引,弥补了上文介绍的 Kappa 架构中消息队列中间件在数据的修改、回溯、查询等方面的不足,从而使得这个架构的容错率更高,支持的能力也更广泛。同时在批处理方面,Paimon 也可以完全兼容 HIVE 的能力。
2.2 加速查询
第二个方案是 Paimon 和 StarRocks 构建湖仓一体数据分析的加速查询方案。

它与第一个方案的区别是几乎整个系统都由 StarRocks 单独完成。当数据接入 Paimon,使它作为 ODS 层之后,通过 StarRocks 的外表特性来读取 Paimon 上的数据,建立一层物化视图来作为 DWD 层。
StarRocks 的物化视图具有一定的 ETL 的能力,当它作为 DWD 层之后,又通过第二层嵌套物化视图来作为 DWS 层,最终提供给数据服务层进行数据分析。
通过 StarRocks 的这套系统配合 Paimon 这个架构的两个优点是:
- 简化了运维,因为它不用再去维护各种组件,只需要 StarRocks 和 Paimon 就可以完成数据分析方案的构建;
- 查询速度快,因为 StarRocks 是一套从构建索引、数据存储、查询优化都自成体系的一个数据湖引擎,所以它相比上文介绍的其他各种查询引擎速度更快。
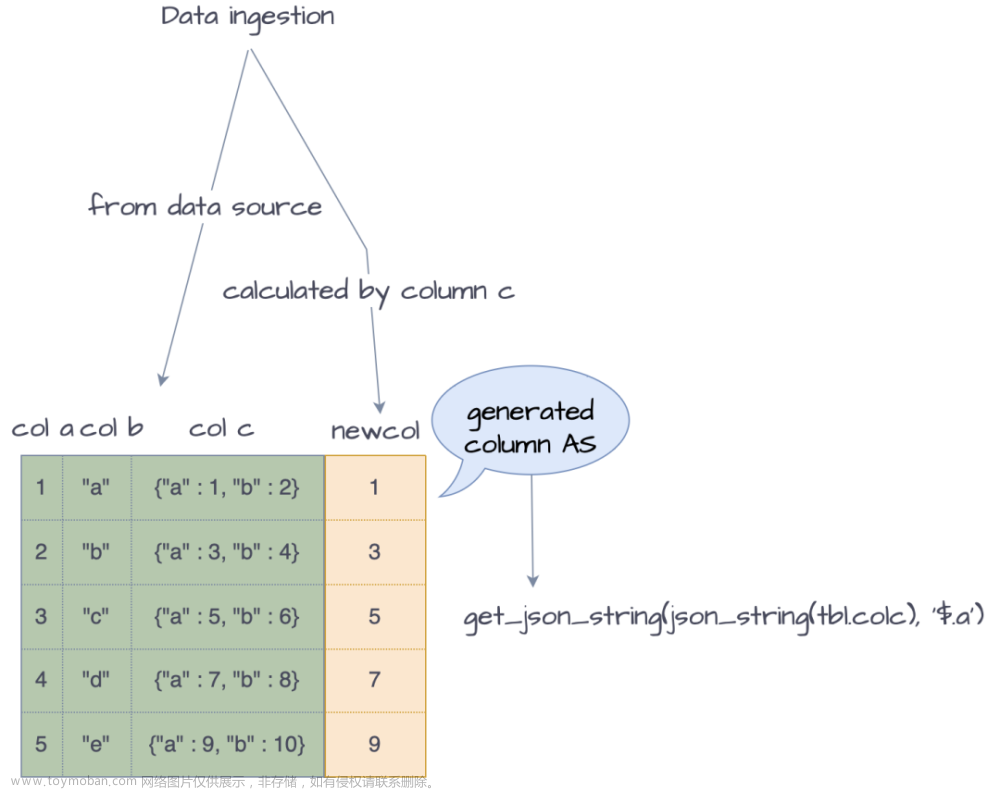
2.3 物化视图

上图右侧 SQL 是描述如何建立一个 StarRocks 异步物化视图。它主要有以下几个特点:
- 通过 SQL 定义,上手简单,方便维护;
- 预计算,降低查询延时,减少重复计算开销;
- 自动查询路由,无需改写 SQL,透明加速;
- 支持异步自动刷新数据,定时刷新,智能按分区刷新;
- 支持多表构建,基表可来自内表、外表和已有的物化视图。
2.4 冷热分离
这是通过 Paimon + StarRocks 实现冷热分离的特性。

冷热分离的概念,是希望可以将经常查询的热数据存储到查询快的像 StarRocks 这种 OLAP 引擎上,不经常查询的冷数据存储到比较廉价的远程文件存储组件,比如 OSS 和 HDFS。
如上图 Paimon + StarRocks 冷热分离的例子,如果构建了这样一个冷热分离的 MV 表,当查询到这张表的时候,会自动选择在 StarRocks 上分布的这个热数据和在 Paimon 分布的冷数据。然后对查询结果合并,并返回给用户。
三、StarRocks 与 Paimon 结合的使用方式与实现原理
3.1 Paimon 外表使用
得益于 StarRocks 对外表 Catalog 的抽象,在 Paimon 推出不久,StarRocks 就以实现相应接口的方式,实现了对于 Paimon 外表的支持。在对接 Paimon 外表时,只需要在 StarRocks 上执行下面这条 Create External Catalog 语句,对 Type 指定为 Paimon,填写上对应的路径之后就可以直接查询 Paimon 中的数据了。

3.2 JNI Connector
JNI Connector 是使得 StarRocks 和 Paimon 结合的一个比较重要的特性。

JNI Connector 的背景是 StarRocks 对于数据处理的组件是 C++ 程序编写的,但是数据湖组件提供的 SDK 大多数是 Java 的,没有 C++ 的 SDK,如果 StarRocks 想要通过 BE 访问数据湖组件底层数据的话,只能访问它原生的 ORC/Parquet 等格式,无法应用这些组件所提供的高级功能。
JNI Connector 是一个抽象的,针对所有外表 Java SDK 都可以适用的 Connector。它用于 StarRocks 的 BE 组件上,是处于 BE 和数据湖组件 Java SDK 之间的中间层。
JNI Connector 的主要功能是调用数据湖组件的 Java SDK 去读取数据湖的数据,然后将读取到的数据以 StarRocks 的 BE 可识别的内存排列方式写入到一块堆外内存上,然后将这个内存交接给 BE C++程序去运行,这样就使得它可以将 BE 和 Java SDK 进行衔接。
JNI Connector 有以下几个特点:
- 快速接入各类 Java 数据源,无需考虑数据转换;
- 提供简单易用的 Java 接口;
- 已支持 Hudi MOR Table,Paimon Table;
- 支持 Struct, Map, Array 复杂类型;
- BE 代码零侵入,不需要考虑 C++具体实现。
下图是 JNI Connector 当中一些细节的介绍。

上面是定长字段存储格式,下面是变长字段的存储格式。
-
定长字段存储格式
- 第一部分是对于这一列中每一行数据是否为 Null 的定义。
- 第二部分是数据部分,这里存储定长的具体的数据。
-
变长字段存储格式
- 第一部分是对于这一列中每一行是否 Null 的数组;
- 第二部分是描述第三部分具体数据中每一行数据开始读取的起始地址;
- 第三部分是具体数据。
四、StarRocks 社区湖仓分析未来规划
当前 StarRocks 已经支持了 Paimon 的一部分特性,还有一些暂未实现。那么未来计划完善 Paimon 表分析的特性如下:
-
支持分析复杂类型
-
支持列统计信息
-
支持元数据缓存
-
支持 time travel
-
支持基于 Paimon 外表的流式物化视图
Q&A
Q:请问物化视图如何做到有效管理?
A:物化视图在建立之后是可以自动刷新和调度的,不需要依赖外部组件去触发刷新。查询改写能力使得用户可以只查 base 表,不需要去指定查某个物化视图。这两个特性减少了不少管理方面的问题。而对于物化视图与 base 表之间、以及嵌套物化视图之间的依赖关系,EMR-Serverless-StarRocks 后续会推出一个任务调度与表依赖关系的 web 展示功能。
Q:Paimon+StarRocks 湖仓一体数据分析方案,在数据安全,比如访问控制、数据审计等,是否有具体的规划?
A:目前我了解到的 StarRocks 关于数据管理权限是基于角色分配的查看、修改等权限,对于不同角色赋予不同权限。另外,对于 OSS 或 HDFS 上的数据会有对应的组件认证功能。
Q:请问以 StarRocks 为主体的湖仓一体架构中,在从 Paimon 读取数据之后,会写回到 Paimon 吗?
A:在从 Paimon 读取完 ODS 层的数据后,会流入 StarRocks 的物化视图,之后是一层嵌套的 StarRocks 物化视图,并不会写回到 Paimon。文章来源:https://www.toymoban.com/news/detail-689906.html
点击查看原文视频 & 演讲PPT
到了这里,关于Paimon+StarRocks 湖仓一体数据分析方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!