原文:Hands-On Image Processing with Python
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
一、图像处理入门
顾名思义,图像处理可以简单地定义为在计算机中(通过代码)使用算法对图像进行处理(分析和操作)。它有几个不同的方面,如图像的存储、表示、信息提取、操作、增强、恢复和解释。在本章中,我们将对图像处理的所有这些不同方面进行基本介绍,并介绍使用 Python 库进行的实际图像处理。本书中的所有代码示例都将使用 Python 3。
我们将从定义什么是图像处理以及图像处理的应用程序开始。然后我们将了解。。。
什么是图像处理和一些应用
让我们首先定义什么是图像,它如何存储在计算机上,以及如何使用 Python 处理它。
什么是图像以及它是如何存储在计算机上的
从概念上讲,最简单形式的图像(单通道;例如,二值或单色、灰度或黑白图像)是二维函数f(x,y),它将坐标对映射为整数/实数,与点的强度/颜色相关。每个点称为一个像素或像素(图片元素)。一幅图像也可以有多个通道(例如彩色 RGB 图像,其中颜色可以用三个通道红、绿、蓝表示)。对于彩色 RGB 图像,(x,y)坐标处的每个像素可以用三元组(rx,y、gx,y、b表示 x,y。
为了能够在计算机上处理它,一幅图像*f(x,y)*需要在空间和空间上进行数字化。。。
什么是图像处理?
图像处理是指在计算机上使用算法和代码对图像进行自动处理、操作、分析和解释。它在电视、摄影、机器人、遥感、医疗诊断和工业检测等科学技术的许多学科和领域都有应用。Facebook 和 Instagram 等社交网站是需要使用/创新许多图像处理算法来处理我们上传的图像的行业的典型例子。我们已经习惯于在日常生活中使用这些网站,每天上传大量图像。
在本书中,我们将使用一些 Python 包来处理图像。首先,我们将使用一组库来进行经典的图像处理:从提取图像数据开始,使用一些算法转换数据,使用库函数进行预处理、增强、恢复、表示(使用描述符)、分割、分类、检测和识别(对象)以进行分析、理解,并更好地解释数据。接下来,我们将使用另一组库来进行基于深度学习的图像处理,这是一种在过去几年中非常流行的技术。
图像处理的一些应用
图像处理的一些典型应用包括医学/生物学领域(例如,X 射线和 CT 扫描)、计算摄影(Photoshop)、指纹认证、人脸识别等。
图像处理流水线
以下步骤描述了图像处理管道中的基本步骤:
-
采集和存储****存储:需要捕获图像(例如使用相机)并将其作为文件(例如 JPEG 文件)存储在某些设备(例如硬盘)上。
-
加载到内存并保存到磁盘:图像需要从磁盘读取到内存并使用某些数据结构(例如,
numpy ndarray)存储,并且数据结构需要在以后序列化到图像文件中,可能是在对图像运行一些算法之后。 -
**操作、增强和恢复:**我们需要运行一些预处理算法来完成以下工作:
- 在图像上运行一些转换(采样和操作;例如,灰度转换)
- 增强图像质量(过滤;例如,去模糊)
- 恢复图像不受噪声影响
-
分割:为了提取感兴趣的对象,需要对图像进行分割。
-
信息提取/表示:图像需要以某种替代形式表示;例如,以下选项之一:
- 可以从图像中计算一些手工制作的特征描述符(例如,使用经典图像处理的 HOG 描述符)
- 一些特征可以从图像中自动学习(例如,通过深度学习在神经网络的隐藏层中学习的权重和偏差值)
- 将使用该替代表示法
来表示图像
-
图像理解/解释**:**此表示将用于通过以下内容更好地理解图像:
- 图像分类(例如,图像是否包含人体对象)
- 对象识别*(例如、*在带有边框的图像中查找汽车对象的位置)
下图描述了图像处理中的不同步骤:

下图表示我们将用于不同图像处理任务的不同模块:

除这些库外,我们还将使用以下库:
-
scipy.ndimage和opencv用于不同的图像处理任务 -
scikit-learn用于经典机器学习 -
tensorflow和keras用于深度学习
在 Python 中设置不同的图像处理库
接下来的几段描述如何安装不同的图像处理库,并设置环境,以便编写代码,使用 Python 中的经典图像处理技术处理图像。在本书的最后几章中,当我们使用基于深度学习的方法时,我们需要使用不同的设置。
安装 pip
我们将使用pip或pip3工具来安装库,因此如果尚未安装,我们需要先安装pip。如本文所述(https://pip.pypa.io/en/stable/installing/#do-i-need-to-install-pip,pip已经安装,如果我们使用从 Python.org 下载的 Python 3>=3.4,或者如果我们在虚拟环境中工作() https://packaging.python.org/tutorials/installing-packages/#creating-使用virtualenv(创建的虚拟环境)https://packaging.python.org/key_projects/#virtualenv 或pyvenv(https://packaging.python.org/key_projects/#venv 。我们只需要确保升级pip(https://pip.pypa.io/en/stable/installing/#upgrading-pip。如何为不同的操作系统或平台安装pip可以在这里找到:https://stackoverflow.com/questions/6587507/how-to-install-pip-with-python-3 。**
***# 在 Python 中安装一些图像处理库
在 Python 中,有许多库可用于图像处理。我们将要使用的是:NumPy、SciPy、scikit image、PIL(枕头)、OpenCV、scikit learn、SimpleITK 和 Matplotlib。
matplotlib库主要用于显示,而numpy将用于存储图像。scikit-learn库将用于建立用于图像处理的机器学习模型,scipy库将主要用于图像增强。scikit-image、mahotas和opencv库将用于不同的图像处理算法。
下面的代码块显示了我们将要使用的库是如何通过pip从 P。。。
安装 Anaconda 配线架
我们还建议下载并安装最新版本的 Anaconda 发行版;这将消除显式安装许多 Python 包的需要
More about installing Anaconda for different OSes can be found at https://conda.io/docs/user-guide/install/index.html.
安装 Jupyter 笔记本电脑
我们将使用Jupyter笔记本编写 Python 代码。因此,我们需要首先在 Python 提示符下安装带有>>> pip install jupyter的jupyter包,然后在浏览器中使用>>> jupyter notebook启动 Jupyter 笔记本应用程序。从那里,我们可以创建新的 Python 笔记本并选择内核。如果我们使用 Anaconda,我们不需要显式安装 Jupyter;最新的 Anaconda 发行版附带 Jupyter。
More about running Jupyter notebooks can be found at http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/execute.html.
我们甚至可以在笔记本电脑单元中安装 Python 包;例如,我们可以使用!pip install scipy命令安装scipy。
For more information …
使用 Python 进行图像 I/O 和显示
图像作为文件存储在磁盘上,因此从文件中读取和写入图像是磁盘 I/O 操作。这些可以通过使用不同库的多种方式来实现;其中一些在本节中显示。让我们首先导入所有必需的包:
# for inline image display inside notebook
# % matplotlib inline
import numpy as np
from PIL import Image, ImageFont, ImageDraw
from PIL.ImageChops import add, subtract, multiply, difference, screen
import PIL.ImageStat as stat
from skimage.io import imread, imsave, imshow, show, imread_collection, imshow_collection
from skimage import color, viewer, exposure, img_as_float, data
from skimage.transform import SimilarityTransform, warp, swirl
from skimage.util import invert, random_noise, montage
import matplotlib.image as mpimg
import matplotlib.pylab as plt
from scipy.ndimage import affine_transform, zoom
from scipy import misc
使用 PIL 读取、保存和显示图像
PIL 函数open()从Image对象中的磁盘读取图像,如下代码所示。图像作为PIL.PngImagePlugin.PngImageFile类的对象加载,我们可以使用宽度、高度和模式等属性来查找图像的大小(宽度x高度像素或图像分辨率)和模式:
im = Image.open("../images/parrot.png") # read the image, provide the correct pathprint(im.width, im.height, im.mode, im.format, type(im))# 453 340 RGB PNG <class 'PIL.PngImagePlugin.PngImageFile'>im.show() # display the image
以下是前面代码的输出:
下面的代码块显示了如何使用 PIL 函数convert()来转换。。。
提供磁盘上映像的正确路径
我们建议创建一个文件夹(子目录)来存储要用于处理的图像(例如,对于 Python 代码示例,我们使用了名为images的文件夹中存储的图像),然后提供文件夹的路径来访问图像,以避免file not found异常。
使用 Matplotlib 读取、保存和显示图像
下一个代码块显示如何使用matplotlib.image中的imread()函数读取浮点numpy ndarray中的图像。像素值表示为介于 0 和 1 之间的实值:
im = mpimg.imread("../images/hill.png") # read the image from disk as a numpy ndarrayprint(im.shape, im.dtype, type(im)) # this image contains an α channel, hence num_channels= 4# (960, 1280, 4) float32 <class 'numpy.ndarray'>plt.figure(figsize=(10,10))plt.imshow(im) # display the imageplt.axis('off')plt.show()
下图显示了前面代码的输出:

下一个代码段。。。
使用 Matplotlib imshow()显示时进行插值
Matplotlib 的imshow()函数提供了许多不同类型的插值方法来绘制图像。当要打印的图像很小时,这些函数特别有用。让我们使用下图所示的小 50 x 50lena图像来查看使用不同插值方法绘制的效果:

下一个代码块演示了如何在imshow()中使用不同的插值方法:
im = mpimg.imread("../images/lena_small.jpg") # read the image from disk as a numpy ndarray
methods = ['none', 'nearest', 'bilinear', 'bicubic', 'spline16', 'lanczos']
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(15, 30),
subplot_kw={'xticks': [], 'yticks': []})
fig.subplots_adjust(hspace=0.05, wspace=0.05)
for ax, interp_method in zip(axes.flat, methods):
ax.imshow(im, interpolation=interp_method)
ax.set_title(str(interp_method), size=20)
plt.tight_layout()
plt.show()
下图显示了前面代码的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IuA9mjlQ-1681961323628)(null)]
使用 scikit 图像读取、保存和显示图像
下一个代码块使用scikit-image中的imread()函数读取uint8类型的numpy ndarray中的图像(8 位无符号整数)。因此,像素值将在 0 和 255 之间。然后使用Image.color模块的hsv2rgb()功能将彩色 RGB 图像转换为 HSV 图像(更改图像类型或模式,稍后讨论)。接下来,通过保持色调和值通道不变,将所有像素的饱和度(色度)更改为恒定值。然后使用rgb2hsv()功能将图像转换回 RGB 模式,以创建新图像,然后保存并显示:
im = imread("../images/parrot.png") # read ...
使用 scikit image 的宇航员数据集
下面的代码块显示了如何使用data模块从scikit-image库的图像数据集中加载astronaut图像。该模块包含一些其他流行的数据集,如 cameraman,可以类似地加载:
im = data.astronaut()
imshow(im), show()
下图显示了前面代码的输出:

一次读取和显示多个图像
我们可以使用 scikit imageio模块的imread_collection()功能将文件名中具有特定图案的所有图像加载到文件夹中,并与imshow_collection()功能同时显示。代码留给读者作为练习。
使用 scipy misc 读取、保存和显示图像
scipy的misc模块也可用于图像 I/O 和显示。以下各节演示如何使用misc模块功能。
使用 scipy.misc 的人脸数据集
下一个代码块展示了如何显示misc模块的face数据集:
im = misc.face() # load the raccoon's face imagemisc.imsave('face.png', im) # uses the Image module (PIL)plt.imshow(im), plt.axis('off'), plt.show()
下图为前一代码的输出,显示misc模块的face画面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FJJlUBua-1681961326681)(null)]
我们可以使用misc.imread()从磁盘读取图像。下一个代码块显示了一个示例:
im = misc.imread('../images/pepper.jpg')print(type(im), im.shape, im.dtype)# <class 'numpy.ndarray'> (225, 225, 3) uint8
在 SciPy 1.0.0 中,I/O 函数的imread()已被弃用,并将被删除。。。
处理不同的图像类型和文件格式,并执行基本的图像处理
在本节中,我们将讨论不同的图像处理函数(使用点变换和几何变换)以及如何处理不同类型的图像。让我们从这个开始
处理不同的图像类型和文件格式
图像可以以不同的文件格式和不同的模式(类型)保存。让我们讨论如何使用 Python 库处理不同文件格式和类型的图像
文件格式
图像文件可以是不同的格式。一些流行的格式包括 BMP(8 位、24 位、32 位)、PNG、JPG(JPEG)、GIF、PPM、PNM 和 TIFF。我们不需要担心图像文件的特定格式(以及元数据的存储方式)来从中提取数据。Python 图像处理库将读取图像并提取数据,以及其他一些对我们有用的信息(例如,图像大小、类型/模式和数据类型)。
从一种文件格式转换为另一种文件格式
使用 PIL,我们可以读取一种文件格式的图像并将其保存到另一种文件格式;例如,从 PNG 到 JPG*,*如下图所示:
im = Image.open("../images/parrot.png")print(im.mode) # RGBim.save("../images/parrot.jpg")
但是如果 PNG 文件处于RGBA模式,我们需要先将其转换为RGB模式,然后再将其保存为 JPG,否则会出现错误。下一个代码块显示如何首先转换然后保存:
im = Image.open("../images/hill.png")print(im.mode)# RGBAim.convert('RGB').save("../images/hill.jpg") # first convert to RGB mode
图像类型(模式)
图像可以是以下不同类型:
- 单通道图像每个像素由单个值表示:
- 二进制(单色)图像(每个像素由单个 0-1 位表示)
- 灰度图像(每个像素可以用 8 位表示,其值通常在 0-255 之间)
- 多通道图像每个像素由一组值表示:
- 三通道图像;例如,以下各项:
- RGB 图像每个像素由三个元组(r、g、b值表示,表示每个像素的红色、绿色和蓝色通道颜色值。
- HSV 图像每个像素由三个元组(h、s、v值表示,分别表示色调(颜色)、饱和度(颜色与白色的混合程度)和值(亮度与黑色的混合程度)每个像素的通道颜色值。HSV 模型以类似于人眼感知颜色的方式描述颜色
- 四通道图像;例如,RGBA 图像每个像素由三个元组(r、g、b、α值表示,最后一个通道表示透明度。
- 三通道图像;例如,以下各项:
从一种图像模式转换为另一种图像模式
我们可以在读取图像本身的同时将 RGB 图像转换为灰度图像。下面的代码正是这样做的:
im = imread("images/parrot.png", as_gray=True)print(im.shape)#(362L, 486L)
请注意,对于某些彩色图像,在转换为灰度时可能会丢失一些信息。以下代码显示了石原牌的示例,用于检测色盲。这次使用color模块的rgb2gray()功能,彩色和灰度图像并排显示。如下图所示,数字8在灰度版中几乎不可见:
im = imread("../images/Ishihara.png")im_g = color.rgb2gray(im)plt.subplot(121), plt.imshow(im, ...
某些颜色空间(通道)
以下是图像的几个常用通道/颜色空间:RGB、HSV、XYZ、YUV、YIQ、YPbPr、YCbCr 和 YDbDr。我们可以使用仿射映射从一个颜色空间转到另一个颜色空间。以下矩阵表示从 RGB 到 YIQ 颜色空间的线性映射:

从一个颜色空间转换到另一个颜色空间
我们可以使用库函数从一个颜色空间转换到另一个颜色空间;例如,以下代码将 RGB 颜色空间转换为 HSV 颜色空间图像:
im = imread("../images/parrot.png")im_hsv = color.rgb2hsv(im)plt.gray()plt.figure(figsize=(10,8))plt.subplot(221), plt.imshow(im_hsv[...,0]), plt.title('h', size=20), plt.axis('off')plt.subplot(222), plt.imshow(im_hsv[...,1]), plt.title('s', size=20), plt.axis('off')plt.subplot(223), plt.imshow(im_hsv[...,2]), plt.title('v', size=20), plt.axis('off')plt.subplot(224), plt.axis('off')plt.show()
下图显示了 h(heu 或颜色:反射光的主波长、s(饱和度或色度)和 v(值或亮度/…)
用于存储图像的数据结构
正如我们已经讨论过的,PIL 使用Image对象存储图像,而 scikit 图像使用numpy ndarray数据结构存储图像数据。下一节介绍如何在这两种数据结构之间进行转换。
转换图像数据结构
下面的代码块显示了如何将 PILImage对象转换为numpy ndarray(由 scikit 图像使用):
im = Image.open('../images/flowers.png') # read image into an Image object with PILim = np.array(im) # create a numpy ndarray from the Image objectimshow(im) # use skimage imshow to display the imageplt.axis('off'), show()
下一个图显示了前面代码的输出,这是一个花的图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-orrexDs4-1681961326898)(null)]
下面的代码块显示如何从numpy ndarray转换为PIL Image对象。运行时,代码显示与上图相同的输出:
im = imread('../images/flowers.png') ...
基本图像处理
不同的 Python 库可用于基本的图像处理。几乎所有的库都将图像存储在numpy ndarray中(例如,用于灰度的二维阵列和用于 RGB 图像的三维阵列)。下图显示彩色lena图像的正x和y方向(原点为图像二维阵列的左上角):

基于 numpy 阵列切片的图像处理
下一个代码块显示如何使用numpy阵列的切片和遮罩在lena图像上创建圆形遮罩:
lena = mpimg.imread("../images/lena.jpg") # read the image from disk as a numpy ndarrayprint(lena[0, 40])# [180 76 83]# print(lena[10:13, 20:23,0:1]) # slicinglx, ly, _ = lena.shapeX, Y = np.ogrid[0:lx, 0:ly]mask = (X - lx / 2) ** 2 + (Y - ly / 2) ** 2 > lx * ly / 4lena[mask,:] = 0 # masksplt.figure(figsize=(10,10))plt.imshow(lena), plt.axis('off'), plt.show()
下图显示了代码的输出:

简单图像变形-使用交叉溶解的两幅图像的α-混合
下面的代码块显示了如何从一张人脸图像(*图像1*是梅西的脸)开始,然后使用两张图像numpy ndarrays的线性组合,以另一张图像(*图像2*是罗纳尔多的脸)结束,公式如下:

我们通过将α从 0 迭代增加到 1 来实现这一点:
im1 = mpimg.imread("../images/messi.jpg") / 255 # scale RGB values in [0,1]
im2 = mpimg.imread("../images/ronaldo.jpg") / 255
i = 1
plt.figure(figsize=(18,15))
for alpha in np.linspace(0,1,20):
plt.subplot(4,5,i)
plt.imshow((1-alpha)*im1 + alpha*im2)
plt.axis('off')
i += 1
plt.subplots_adjust(wspace=0.05, hspace=0.05)
plt.show()
下一幅图显示了使用前一个代码创建的α混合图像序列,该代码将梅西的面部图像交叉分解为罗纳尔多的。从图中的中间图像序列可以看出,简单混合的人脸变形不是很平滑。在接下来的章节中,我们将看到更先进的图像变形技术:

基于 PIL 的图像处理
PIL 为我们提供了许多操作图像的功能;例如,使用点变换更改像素值或对图像执行几何变换。让我们首先加载 parrot PNG 图像,如下代码所示:
im = Image.open("../images/parrot.png") # open the image, provide the correct pathprint(im.width, im.height, im.mode, im.format) # print image size, mode and format# 486 362 RGB PNG
接下来的几节将介绍如何使用 PIL 进行不同类型的图像处理。
裁剪图像
我们可以使用带有所需矩形参数的crop()函数从图像中裁剪相应区域,如下代码所示:
im_c = im.crop((175,75,320,200)) # crop the rectangle given by (left, top, right, bottom) from the image
im_c.show()
下图显示了使用前面代码创建的裁剪图像:

调整图像大小
为了增加或减少图像的大小,我们可以使用resize()函数,该函数分别对图像进行内部上采样或下采样。这将在下一章详细讨论。
调整到更大的图像
让我们从一个 149 x 97 大小的小时钟图像开始,然后创建一个更大的图像。下面的代码片段显示了我们将从中开始的小时钟图像:
im = Image.open("../images/clock.jpg")print(im.width, im.height)# 107 105im.show()
前面代码的输出,小时钟图像,如下所示:

下一行代码显示了如何使用resize()函数。。。
否定图像
我们可以使用point()函数用一个参数函数变换每个像素值。我们可以使用它对图像求反,如下一个代码块所示。像素值使用 1 字节无符号整数表示,这就是为什么从最大可能值中减去它将是每个像素上获得反转图像所需的精确点运算:
im = Image.open("../images/parrot.png")
im_t = im.point(lambda x: 255 - x)
im_t.show()
下图显示负片图像,即前一代码的输出:

将图像转换为灰度
我们可以使用带有'L'参数的convert()函数将 RGB 彩色图像转换为灰度图像,如下代码所示:
im_g = im.convert('L') # convert the RGB color image to a grayscale image
我们将在接下来的几个灰度变换中使用此图像。
一些灰度变换
在这里,我们探讨了几个变换,其中,使用一个函数,将输入图像的每个单个像素值转换为输出图像的相应像素值。功能point()可用于此。每个像素的值介于 0 和 255 之间(包括 0 和 255)。
日志转换
对数变换可用于有效压缩具有动态像素值范围的图像。以下代码使用点变换进行对数变换。可以看出,像素值的范围缩小,来自输入图像的较亮像素变暗,较暗像素变亮,从而缩小像素值的范围:
im_g.point(lambda x: 255*np.log(1+x/255)).show()
下图显示了通过运行前一行代码生成的输出日志转换图像:

幂律变换
该变换用作图像的γ校正。下一行代码显示了如何使用point()函数进行幂律变换,其中γ=0.6:
im_g.point(lambda x: 255*(x/255)**0.6).show()
下图显示了通过运行前一行代码生成的输出幂律变换图像:

一些几何变换
在本节中,我们将讨论通过将适当的矩阵(通常用齐次坐标表示)与图像矩阵相乘来完成的另一组变换。这些变换会更改图像的几何方向,因此得名。
反射图像
我们可以使用transpose()功能来反映关于水平轴或垂直轴的图像:
im.transpose(Image.FLIP_LEFT_RIGHT).show() # reflect about the vertical axis
下图显示了通过运行前一行代码生成的输出图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8agGRlGx-1681961333561)(null)]
旋转图像
我们可以使用rotate()功能旋转。。。
更改图像的像素值
我们可以使用putpixel()功能更改图像中的像素值。接下来,让我们讨论使用函数向图像添加噪声的一个流行应用。
向图像添加椒盐噪声
我们可以从图像中随机选择几个像素,然后将这些像素值的一半设置为黑色,另一半设置为白色,从而在图像中添加一些椒盐噪声。下一个代码段显示了如何添加噪波:
# choose 5000 random locations inside image
im1 = im.copy() # keep the original image, create a copy
n = 5000
x, y = np.random.randint(0, im.width, n), np.random.randint(0, im.height, n)
for (x,y) in zip(x,y):
im1.putpixel((x, y), ((0,0,0) if np.random.rand() < 0.5 else (255,255,255))) # salt-and-pepper noise
im1.show()
下图显示了通过运行前面的代码生成的输出噪声图像:

画图
我们可以从PIL.ImageDraw模块在图像上绘制线条或其他几何形状(例如,绘制椭圆的ellipse()函数),如下一个 Python 代码片段所示:
im = Image.open("../images/parrot.png")draw = ImageDraw.Draw(im)draw.ellipse((125, 125, 200, 250), fill=(255,255,255,128))del drawim.show()
下图显示了通过运行前面的代码生成的输出图像:

在图像上绘制文本
我们可以使用PIL.ImageDraw模块中的text()函数向图像添加文本,如下一个 Python 代码片段所示:
draw = ImageDraw.Draw(im)
font = ImageFont.truetype("arial.ttf", 23) # use a truetype font
draw.text((10, 5), "Welcome to image processing with python", font=font)
del draw
im.show()
下图显示了通过运行前面的代码生成的输出图像:

创建缩略图
我们可以使用thumbnail()功能从图像中创建缩略图,如下所示:
im_thumbnail = im.copy() # need to copy the original image firstim_thumbnail.thumbnail((100,100))# now paste the thumbnail on the image im.paste(im_thumbnail, (10,10))
im.save("../images/parrot_thumb.jpg")
im.show()
此图显示了通过运行前面的代码段生成的输出图像:

计算图像的基本统计信息
我们可以使用stat模块计算一幅图像的基本统计数据(不同通道像素值的平均值、中值、标准偏差等),如下所示:
s = stat.Stat(im)
print(s.extrema) # maximum and minimum pixel values for each channel R, G, B
# [(4, 255), (0, 255), (0, 253)]
print(s.count)
# [154020, 154020, 154020]
print(s.mean)
# [125.41305674587716, 124.43517724970783, 68.38463186599142]
print(s.median)
# [117, 128, 63]
print(s.stddev)
# [47.56564506512579, 51.08397900881395, 39.067418896260094]
绘制图像 RGB 通道的像素值直方图
histogram()函数可用于计算每个通道像素的直方图(像素值与频率的表格),并返回串联输出(例如,对于 RGB 图像,输出包含3 x 256=768值):
pl = im.histogram()plt.bar(range(256), pl[:256], color='r', alpha=0.5)plt.bar(range(256), pl[256:2*256], color='g', alpha=0.4)plt.bar(range(256), pl[2*256:], color='b', alpha=0.3)plt.show()
下图显示了通过运行前面的代码绘制的 R、G 和 B 颜色直方图:
分离图像的 RGB 通道
我们可以使用split()功能分离多通道图像的通道,如下 RGB 图像代码所示:
ch_r, ch_g, ch_b = im.split() # split the RGB image into 3 channels: R, G and B
# we shall use matplotlib to display the channels
plt.figure(figsize=(18,6))
plt.subplot(1,3,1); plt.imshow(ch_r, cmap=plt.cm.Reds); plt.axis('off')
plt.subplot(1,3,2); plt.imshow(ch_g, cmap=plt.cm.Greens); plt.axis('off')
plt.subplot(1,3,3); plt.imshow(ch_b, cmap=plt.cm.Blues); plt.axis('off')
plt.tight_layout()
plt.show() # show the R, G, B channels
下图显示了通过运行前面的代码为每个 R(红色)、G(绿色)和 B(蓝色)通道创建的三个输出图像:

组合图像的多个通道
我们可以使用merge()功能组合多通道图像的通道,如下代码所示,其中通过分割鹦鹉 RGB 图像获得的彩色通道在交换红色和蓝色通道后合并:
im = Image.merge('RGB', (ch_b, ch_g, ch_r)) # swap the red and blue channels obtained last time with split()im.show()
下图显示了通过运行前面的代码段合并 B、G 和 R 通道而创建的 RGB 输出图像:

α-混合两幅图像
blend()函数可用于通过使用常数α插值两个给定图像(大小相同)来创建新图像。两个图像必须具有相同的大小和模式。输出图像如下所示:
out=图像1(1.0-α)+图像2α
如果α为 0.0,则返回第一个图像的副本。如果α为 1.0,则返回第二个图像的副本。下一个代码段显示了一个示例:
im1 = Image.open("../images/parrot.png")
im2 = Image.open("../images/hill.png")
# 453 340 1280 960 RGB RGBA
im1 = im1.convert('RGBA') # two images have different modes, must be converted to the same mode
im2 = im2.resize((im1.width, im1.height), Image.BILINEAR) # two images have different sizes, must be converted to the same size
im = Image.blend(im1, im2, alpha=0.5).show()
下图显示了通过混合前两个图像生成的输出图像:

叠加两幅图像
通过将两个输入图像(大小相同)逐像素相乘,可以将一个图像叠加到另一个图像上。下一个代码段显示了一个示例:
im1 = Image.open("../images/parrot.png")im2 = Image.open("../images/hill.png").convert('RGB').resize((im1.width, im1.height))multiply(im1, im2).show()
下图显示了通过运行前面的代码段叠加两个图像时生成的输出图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eoa8auwN-1681961321680)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/9ecfd999-8b3a-4302-85ef-d164447185d5.png)]
添加两个图像
下一个代码段显示了如何通过逐像素添加两个输入图像(大小相同)来生成图像:
add(im1, im2).show()
下图显示了通过运行上一个代码段生成的输出图像:

计算两幅图像之间的差异
以下代码返回图像之间逐像素差异的绝对值。图像差异可用于检测两个图像之间的变化。例如,下一个代码块显示了如何从 2018 年 FIFA 世界杯比赛的视频记录(来自 YouTube)的两个连续帧计算差分图像:
from PIL.ImageChops import subtract, multiply, screen, difference, addim1 = Image.open("../images/goal1.png") # load two consecutive frame images from the videoim2 = Image.open("../images/goal2.png")im = difference(im1, im2)im.save("../images/goal_diff.png")plt.subplot(311)plt.imshow(im1)plt.axis('off')plt.subplot(312)plt.imshow(im2)plt.axis('off')plt.subplot(313) ...
减去两幅图像并叠加两幅图像负片
subtract()功能可用于首先减去两幅图像,然后将结果除以比例(默认为 1.0)并添加偏移量(默认为 0.0)。类似地,screen()功能可用于将两个反转图像叠加在彼此的顶部。
使用 scikit 图像进行图像处理
正如前面使用 PIL 库所做的,我们还可以使用scikit-image库函数进行图像处理。以下各节显示了一些示例。
使用 warp()函数进行反向扭曲和几何变换
scikit imagetransform模块的warp()函数可用于图像几何变换的反向扭曲(在上一节中讨论),如以下示例所示。
对图像应用仿射变换
我们可以使用SimilarityTransform()函数计算转换矩阵,然后使用warp()函数进行转换,如下一个代码块所示:
im = imread("../images/parrot.png")
tform = SimilarityTransform(scale=0.9, rotation=np.pi/4,translation=(im.shape[0]/2, -100))
warped = warp(im, tform)
import matplotlib.pyplot as plt
plt.imshow(warped), plt.axis('off'), plt.show()
下图显示了通过运行上一个代码段生成的输出图像:

应用漩涡变换
这是 scikit 图像文档中定义的非线性变换。下一个代码片段展示了如何使用swirl()函数实现转换,其中strength是函数的参数,表示swirl的数量,radius表示swirl的像素范围,rotation添加了旋转角度。将radius转化为r是为了确保转化衰减到≈千分之一≈ 规定半径内的 1/1000:
im = imread("../images/parrot.png")swirled = swirl(im, rotation=0, strength=15, radius=200)plt.imshow(swirled)plt.axis('off')plt.show()
下一个图显示了通过运行前面的代码段通过漩涡变换生成的输出图像:
向图像中添加随机高斯噪声
我们可以使用random_noise()功能向图像添加不同类型的噪声。下一个代码示例显示了如何将具有不同方差的高斯噪声添加到图像中:
im = img_as_float(imread("../images/parrot.png"))
plt.figure(figsize=(15,12))
sigmas = [0.1, 0.25, 0.5, 1]
for i in range(4):
noisy = random_noise(im, var=sigmas[i]**2)
plt.subplot(2,2,i+1)
plt.imshow(noisy)
plt.axis('off')
plt.title('Gaussian noise with sigma=' + str(sigmas[i]), size=20)
plt.tight_layout()
plt.show()
下一个图显示了通过运行前面的代码片段添加具有不同方差的高斯噪声生成的输出图像。可以看出,高斯噪声的标准偏差越大,输出图像的噪声越大:

计算图像的累积分布函数
我们可以使用cumulative_distribution()函数计算给定图像的累积分布函数(CDF,我们将在图像增强一章中看到。现在,我们鼓励读者使用这个函数来计算 CDF。
用 Matplotlib 进行图像处理
我们可以使用matplotlib库中的pylab模块进行图像处理。下一节将显示一个示例。
*# 为图像绘制轮廓线
图像的轮廓线是一条曲线,连接所有具有相同特定值的像素。以下代码块显示如何绘制爱因斯坦灰度图像的轮廓线和填充轮廓:
im = rgb2gray(imread("../images/einstein.jpg")) # read the image from disk as a numpy ndarrayplt.figure(figsize=(20,8))plt.subplot(131), plt.imshow(im, cmap='gray'), plt.title('Original Image', size=20) plt.subplot(132), plt.contour(np.flipud(im), colors='k', levels=np.logspace(-15, 15, 100))plt.title('Image Contour Lines', size=20)plt.subplot(133), plt.title('Image Filled Contour', size=20), plt.contourf(np.flipud(im), cmap='inferno')plt.show()
下一个图显示了。。。
使用 scipy.misc 和 scipy.ndimage 模块进行图像处理
我们也可以使用scipy库中的misc和ndimage模块进行图像处理;这是留给读者的练习,让他们找到相关的功能并熟悉它们的用法。
总结
在本章中,我们首先提供了图像处理的基本介绍,以及关于我们试图在图像处理中解决的问题的基本概念。然后,我们讨论了图像处理的不同任务和步骤,以及 Python 中的主要图像处理库,我们将在本书中使用这些库进行编码。接下来,我们讨论了如何在 Python 中安装用于图像处理的不同库,以及如何导入它们并从模块中调用函数。我们还介绍了有关图像类型、文件格式和数据结构的基本概念,以使用不同的 Python 库存储图像数据。然后,我们讨论了如何使用不同的库在 Python 中执行图像 I/O 和显示。最后,我们讨论了如何。。。
问题
- 使用
scikit-image库的函数读取图像集合并将其显示为蒙太奇。 - 使用
scipy ndimage和misc模块的功能对图像进行缩放、裁剪、调整大小和应用仿射变换。 - 创建 Gotham Instagram 过滤器的 Python 翻拍版(https://github.com/lukexyz/CV-Instagram-Filters (提示:使用 PIL
split()、merge()和numpy interp()功能操作图像以创建通道插值(https://www.youtube.com/watch?v=otLGDpBglEA &功能=播放器(嵌入)。 - 使用 scikit image 的
warp()功能实现漩涡变换。注意,swirl变换也可以用以下等式表示:




- 执行以下给出的波形变换(提示:使用 scikit 图像的
warp():


- 使用 PIL 加载带有调色板的 RGB
.png文件,并将其转换为灰度图像。此问题摘自此帖:https://stackoverflow.com/questions/51676447/python-use-pil-to-load-png-file-gives-strange-results/51678271#51678271 。通过索引调色板,将以下 RGB 图像(来自VOC2012数据集)转换为灰度图像:

-
为本章中使用的鹦鹉图像的每个颜色通道绘制 3D 图(提示:使用
mpl_toolkits.mplot3d模块的plot_surface()功能和 NumPy 的meshgrid()功能)。 -
使用 SCIKIT 图像的 To.T0.模块的莱娜 T1 来估计从源到目标图像的单应矩阵,并使用 AUT2 T2 函数嵌入在空白画布中的图像(如下所示):
| 输入图像 | 输出图像 |
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-60AbU86m-1681961333418)(null)] |  |
|
首先,试着自己解决问题。可在此处找到解决方案供您参考:https://sandipanweb.wordpress.com/2018/07/30/some-image-processing-problems/ 。
进一步阅读
-
数字图像处理,Rafael C.Gonzalez 和 Richard E.Woods 关于图像处理概念的书
-
本课程的课堂讲稿/讲义(https://web.stanford.edu/class/ee368/handouts.html 斯坦福大学的课程和本(https://ocw.mit.edu/resources/res-2-006-girls-who-build-cameras-summer-2016/ 麻省理工学院的一个
-
http://scikit-image.org/docs/dev/api/skimage.html
-
https://pillow.readthedocs.io/en/3.1.x/reference/Image.html
-
https://docs.scipy.org/doc/scipy-1.1.0/reference/ndimage.html
-
https://matplotlib.org/gallery
-
http://members.cbio.mines-paristech.fr/~nvaroquaux/formations/scipy 课堂讲稿/advanced/image\u processing/index.html
-
http://www.scipy-lectures.org/
-
https://web.cs.wpi.edu/~emmanuel/courses/cs545/S14/slides/讲师 09.pdf。。。****
二、采样、傅里叶变换和卷积
在本章中,我们将讨论时域和频域中的二维信号。我们将首先讨论空间采样,这是一个用于调整图像大小的重要概念,以及采样中的挑战。我们将尝试使用 Python 库中的函数来解决这些问题。我们还将在图像中引入强度量化;强度量化意味着将使用多少位来存储图像中的像素,以及它对图像质量的影响。您肯定想了解可用于将图像从空间(时间)域转换为频域的离散傅里叶变换(DFT)。您将学习使用numpy和scipy函数使用快速傅里叶变换(FFT算法实现 DFT,并将能够在图像上应用此实现!
您还将有兴趣了解提高卷积速度的 2D 卷积。我们还将了解卷积定理的基本概念。我们将尝试用一个例子来澄清相关性和卷积之间由来已久的混淆。此外,我们将描述来自 SciPy 的一个示例,该示例将向您展示如何通过应用互相关来使用模板查找图像中特定图案的位置。
我们还将介绍一些过滤技术,并了解如何使用 Python 库实现它们。您将有兴趣看到我们使用这些过滤器对图像进行去噪后得到的结果。
我们将在本章中介绍的主题如下:
- 图像形成–采样和量化
- 离散傅里叶变换
- 理解卷积
图像形成–采样和量化
在本节中,我们将描述图像形成的两个重要概念,即采样和量化,并了解如何使用PIL 和scikit-image库对采样和颜色进行量化来调整图像大小。我们将在这里使用实际操作的方法,我们将在看到这些概念实际应用的同时定义它们。准备好的
让我们从导入所有必需的包开始:
% matplotlib inline # for inline image display inside notebookfrom PIL import Imagefrom skimage.io import imread, imshow, showimport scipy.fftpack as fpfrom scipy import ndimage, misc, signalfrom scipy.stats import signaltonoisefrom skimage import data, img_as_floatfrom skimage.color import rgb2grayfrom skimage.transform import ...
取样
采样是指选择/拒绝图像像素,这意味着它是一种空间操作。我们可以使用采样来增加或减小图像的大小,分别使用上采样和下采样。在接下来的几节中,我们将通过示例讨论不同的采样技术。
上采样
正如在第 1 章中简要讨论的,开始图像处理,为了增加图像的大小,我们需要对图像进行上采样。挑战在于,新的较大图像将具有一些像素,而这些像素在原始较小图像中没有相应的像素,我们需要猜测这些未知像素值。我们可以使用以下公式猜测未知像素的值:
- 聚合,例如,其最近的一个或多个已知像素邻域值的平均值
- 使用像素邻域进行双线性或三次插值的插值
基于最近邻的上采样可能会导致输出图像质量差。让我们编写代码来验证这一点:
im = Image.open("../images/clock.jpg") # the original small ...
上采样和插值
为了提高上采样输出的图像质量,可以采用一些插值方法,如双线性插值或双三次插值。让我们看看如何。
双线性插值
让我们考虑一个灰度图像,它基本上是整数网格位置的像素值的二维矩阵。要在网格上的任意点P处插值像素值,可以使用线性插值的 2D 模拟:双线性插值。在这种情况下,对于每个可能的点P(我们要插值),四个相邻点(即Q11、Q12、Q22和Q21)这四个相邻点的强度值将被合并,以计算点 P 处的插值强度,如下图所示:

让我们使用 PILresize()函数进行双线性插值:
im1 = im.resize((im.width*5, im.height*5), Image.BILINEAR) # up-sample with bi-linear interpolation
pylab.figure(figsize=(10,10)), pylab.imshow(im1), pylab.show()
这是调整大小的图像。请注意,当双线性插值与上采样一起使用时,质量是如何提高的:

双三次插值
它是三次插值的扩展,用于在二维规则网格上插值数据点。插值曲面比通过双线性插值或最近邻插值获得的相应曲面更平滑。
双三次插值可以使用拉格朗日多项式、三次样条曲线或三次卷积算法来完成。PIL 在 4x4 环境中使用三次样条插值。
让我们使用 PILresize()函数进行双三次插值:
im.resize((im.width*10, im.height*10), Image.BICUBIC).show() # bi-cubic interpolation
pylab.figure(figsize=(10,10)), pylab.imshow(im1), pylab.show()
看看当我们使用双三次插值时,调整大小的图像的质量是如何提高的:

下采样
为了减小图像的大小,我们需要对图像进行下采样。对于新的较小图像中的每个像素,原始较大图像中将有多个像素。我们可以通过执行以下操作来计算新图像中像素的值:
- 以系统的方式从较大的图像中删除一些像素(例如,如果我们希望图像的大小为原始图像的四分之一,则每隔一行和一列删除一个像素)
- 计算新像素值作为原始图像中对应的多个像素的聚合值
让我们使用tajmahal.jpg图像,并使用resize()函数将其调整为比输入图像小 25 倍的输出图像,同样来自 PIL 库:
im = Image.open("../images/tajmahal.jpg") ...
下采样和抗锯齿
正如我们所看到的,下采样对于缩小图像不是很好,因为它会产生锯齿效果。例如,如果我们试图通过将宽度和高度减少 5 倍来调整原始图像的大小(向下采样),我们将得到如此不完整和糟糕的输出。
抗混叠
这里的问题是,输出图像中的单个像素对应于输入图像中的 25 个像素,但我们对单个像素的值进行采样。我们应该在输入图像的一个小区域上求平均值。这可以使用ANTIALIAS(高质量下采样过滤器)实现;这就是你可以做到的:
im = im.resize((im.width//5, im.height//5), Image.ANTIALIAS)
pylab.figure(figsize=(15,10)), pylab.imshow(im), pylab.show()
使用带抗锯齿的 PIL 创建图像,与前一个图像相同,但质量更好(几乎没有任何伪影/锯齿效果):

抗混叠通常在下采样之前通过平滑图像(通过使用低通滤波器(如高斯滤波器)对图像进行卷积)来完成
现在让我们使用 scikit imagetransform模块的rescale()抗混叠功能来克服另一个图像的混叠问题,即umbc.png图像:
im = imread('../images/umbc.png')
im1 = im.copy()
pylab.figure(figsize=(20,15))
for i in range(4):
pylab.subplot(2,2,i+1), pylab.imshow(im1, cmap='gray'), pylab.axis('off')
pylab.title('image size = ' + str(im1.shape[1]) + 'x' + str(im1.shape[0]))
im1 = rescale(im1, scale = 0.5, multichannel=True, anti_aliasing=False)
pylab.subplots_adjust(wspace=0.1, hspace=0.1)
pylab.show()
下一个屏幕截图显示了前面代码的输出。如图所示,图像被下采样以创建越来越小的输出。当不使用抗锯齿技术时,锯齿效果变得更加突出:

让我们更改代码行以使用抗锯齿:
im1 = rescale(im1, scale = 0.5, multichannel=True, anti_aliasing=True)
这会产生质量更好的图像:

To learn more about interpolation and anti-aliasing, please visit my blog: https://sandipanweb.wordpress.com/2018/01/21/recursive-graphics-bilinear-interpolation-and-image-transformation-in-Python/.
量化
量化与图像的强度相关,可以通过每个像素使用的位数来定义。数字图像通常量化到 256 灰度级。这里,我们将看到,随着用于像素存储的比特数的减少,量化误差增加,导致人为边界或轮廓和像素化,并导致图像质量差。
PIL 量子化
让我们使用 PILImage模块的convert()函数进行颜色量化,P 模式和颜色参数作为可能的最大颜色数。我们还将使用 SciPystats模块的signaltonoise()函数来查找图像(parrot.jpg的信噪比(信噪比),其定义为图像阵列的标准偏差除以平均值:
im = Image.open('../images/parrot.jpg')
pylab.figure(figsize=(20,30))
num_colors_list = [1 << n for n in range(8,0,-1)]
snr_list = []
i = 1
for num_colors in num_colors_list:
im1 = im.convert('P', palette=Image.ADAPTIVE, colors=num_colors)
pylab.subplot(4,2,i), pylab.imshow(im1), pylab.axis('off')
snr_list.append(signaltonoise(im1, axis=None))
pylab.title('Image with # colors = ' + str(num_colors) + ' SNR = ' +
str(np.round(snr_list[i-1],3)), size=20)
i += 1
pylab.subplots_adjust(wspace=0.2, hspace=0)
pylab.show()
这显示了当存储像素的位数减少时,图像质量如何随着颜色量化而降低:

框架二如下:

现在我们将绘制颜色量化对图像信噪比的影响,信噪比通常是衡量图像质量的指标,信噪比越高,质量越好:
pylab.plot(num_colors_list, snr_list, 'r.-')
pylab.xlabel('# colors in the image')
pylab.ylabel('SNR')
pylab.title('Change in SNR w.r.t. # colors')
pylab.xscale('log', basex=2)
pylab.gca().invert_xaxis()
pylab.show()
可以看出,尽管颜色量化减小了图像大小(因为比特/像素的数量减少),但它也使图像质量变差,通过 SNR 测量:

离散傅里叶变换
傅里叶变换方法有着悠久的数学历史,我们不打算在这里讨论它(它可以在任何数字信号处理或数字图像处理理论书籍中找到)。就图像处理而言,我们将只关注 2D离散傅里叶变换(DFT),傅里叶变换方法背后的基本思想是,图像可以被认为是一个 2D 函数,f,,可以表示为正弦和余弦的加权和(傅里叶基本函数)沿二维方向。
我们可以使用 DFT 从图像中的一组灰度像素值(空间/时间域)转换为一组傅里叶系数(频域),并且它是离散的,因为空间和变换。。。
为什么我们需要 DFT?
首先,变换到频域可以更好地理解图像。我们将在接下来的几节中看到,频域中的低频对应于图像中信息的平均总体水平,而高频对应于边缘、噪声和更详细的信息。
通常,图像本质上是平滑的,这就是为什么大多数图像可以使用少量 DFT 系数表示,而所有剩余的更高系数几乎可以忽略不计/零。
这在图像压缩中非常有用,特别是对于傅里叶稀疏图像,其中重建图像只需要少数傅里叶系数,因此只能存储这些频率,而可以丢弃其他频率,从而实现高压缩(例如,在 JPEG 图像压缩算法中,使用了类似的变换,离散余弦变换(DCT)。此外,正如我们将在本章后面看到的,在频域中使用 DFT 进行滤波可能比在空间域中进行滤波快得多
计算 DFT 的快速傅里叶变换算法
快速傅里叶变换(FFT)是一种分治算法,用于递归计算 DFT,其速度(O(N.log2N)时间复杂度)比针对nxn图像的缓慢得多的 O(N2)原始计算快得多。在 Python 中,numpy和scipy库都提供了使用 FFT 算法计算 2D DFT/IDFT 的函数。让我们看几个例子。
*# 带有 scipy.fftpack 模块的 FFT
我们将使用scipy.fftpack模块的fft2()/ifft2()函数,通过使用灰度图像rhino.jpg的 FFT 算法计算 DFT/IDFT:
im = np.array(Image.open('../images/rhino.jpg').convert('L')) # we shall work with grayscale image
snr = signaltonoise(im, axis=None)
print('SNR for the original image = ' + str(snr))
# SNR for the original image = 2.023722773801701
# now call FFT and IFFT
freq = fp.fft2(im)
im1 = fp.ifft2(freq).real
snr = signaltonoise(im1, axis=None)
print('SNR for the image obtained after reconstruction = ' + str(snr))
# SNR for the image obtained after reconstruction = 2.0237227738013224
assert(np.allclose(im, im1)) # make sure the forward and inverse FFT are close to each other
pylab.figure(figsize=(20,10))
pylab.subplot(121), pylab.imshow(im, cmap='gray'), pylab.axis('off')
pylab.title('Original Image', size=20)
pylab.subplot(122), pylab.imshow(im1, cmap='gray'), pylab.axis('off')
pylab.title('Image obtained after reconstruction', size=20)
pylab.show()
以下是输出:

从内联输出的 SNR 值以及输入和重建图像的视觉差异可以看出,重建图像丢失了一些信息。如果我们使用获得的所有系数进行重建,则差异可以忽略不计
绘制频谱图
由于傅里叶系数是复数,我们可以直接观察震级。显示傅里叶变换的量级称为变换的光谱。DFT 的值 F[0,0]称为DC 系数。****
DC 系数太大,无法看到其他系数值,这就是为什么我们需要通过显示变换的对数来拉伸变换值。此外,为了便于显示,变换系数被移位(使用fftshift()),使得 DC 分量位于中心。对创造犀牛图像的傅里叶光谱感到兴奋吗?编码如下:
# the quadrants are needed to be shifted around in order that the low spatial frequencies are in the center of the 2D fourier-transformed ...
带 numpy.FFT 模块的 FFT
可以使用numpy.fft模块的类似函数集计算图像的 DFT。我们将看到一些例子。
计算 DFT 的幅度和相位
我们将使用house.png图像作为输入,从而fft2()得到傅里叶系数的实部和虚部;之后,我们将计算幅值/频谱和相位,最后使用ifft2()重建图像:
import numpy.fft as fpim1 = rgb2gray(imread('../images/house.png'))pylab.figure(figsize=(12,10))freq1 = fp.fft2(im1)im1_ = fp.ifft2(freq1).realpylab.subplot(2,2,1), pylab.imshow(im1, cmap='gray'), pylab.title('Original Image', size=20)pylab.subplot(2,2,2), pylab.imshow(20*np.log10( 0.01 + np.abs(fp.fftshift(freq1))), cmap='gray')pylab.title('FFT Spectrum Magnitude', size=20)pylab.subplot(2,2,3), pylab.imshow(np.angle(fp.fftshift(freq1)), cmap='gray')pylab.title('FFT ...
理解卷积
卷积是对两个图像进行操作的操作,一个是输入图像,另一个是掩码(也称为内核),作为输入图像上的过滤器,生成输出图像
卷积滤波用于修改图像的空间频率特性。它的工作原理是通过将所有相邻像素的加权值相加来确定中心像素的值,从而计算输出图像中像素的新值。输出图像中的像素值是通过在输入图像中遍历内核窗口来计算的,如下一个屏幕截图所示(对于有效模式的卷积;我们将在本章后面看到卷积模式):

如您所见,内核窗口(由输入图像中的箭头标记)遍历图像,并在卷积后获得映射到输出图像上的值。
为什么要卷积图像?
卷积对输入图像应用通用滤波效果。这样做是为了在图像上使用适当的核实现各种效果,例如平滑、锐化和浮雕,以及在诸如边缘检测等操作中。
SciPy 信号卷积的卷积
SciPy 信号模块的convolve2d()功能可用于相关。我们将使用这个函数对具有内核的图像应用卷积。
对灰度图像应用卷积
让我们首先使用卷积和拉普拉斯核从灰度cameraman.jpg图像中检测边缘,并使用box核模糊图像:
im = rgb2gray(imread('../image s/cameraman.jpg')).astype(float)print(np.max(im))# 1.0print(im.shape)# (225, 225)blur_box_kernel = np.ones((3,3)) / 9edge_laplace_kernel = np.array([[0,1,0],[1,-4,1],[0,1,0]])im_blurred = signal.convolve2d(im, blur_box_kernel)im_edges = np.clip(signal.convolve2d(im, edge_laplace_kernel), 0, 1)fig, axes = pylab.subplots(ncols=3, sharex=True, sharey=True, figsize=(18, 6))axes[0].imshow(im, cmap=pylab.cm.gray)axes[0].set_title('Original Image', size=20)axes[1].imshow(im_blurred, cmap=pylab.cm.gray)axes[1].set_title('Box Blur', ...
卷积模式、焊盘值和边界条件
根据您想要对边缘像素执行的操作,有三个参数:mode、boundary和fillvalue,可以传递给 SciPyconvolve2d()函数。在这里,我们将简要讨论mode论点:
-
mode='full':默认模式,输出为输入的全离散线性卷积 -
mode='valid':忽略边缘像素,只计算所有相邻像素(不需要零填充的像素)。输出图像大小小于所有内核的输入图像大小(1 x 1 除外) -
mode='same':输出图像与输入图像大小相同;它相对于'full'输出居中。
对彩色(RGB)图像应用卷积
使用scipy.convolve2d(),我们还可以锐化 RGB 图像。我们必须对每个图像通道分别应用卷积。
让我们使用带有emboss内核和 schar 边缘检测复合内核的tajmahal.jpg图像:
im = misc.imread('../images/tajmahal.jpg')/255 # scale each pixel value in [0,1]print(np.max(im))print(im.shape)emboss_kernel = np.array([[-2,-1,0],[-1,1,1],[0,1,2]])edge_schar_kernel = np.array([[ -3-3j, 0-10j, +3 -3j], [-10+0j, 0+ 0j, +10+0j], [ -3+3j, 0+10j, +3 +3j]])im_embossed = np.ones(im.shape)im_edges = np.ones(im.shape)for i in range(3): im_embossed[...,i] = np.clip(signal.convolve2d(im[...,i], emboss_kernel, mode='same', boundary="symm"),0,1)for i in range(3): ...
带 SciPy ndimage.COLVEL 的卷积
使用scipy.ndimage.convolve(),我们可以直接锐化 RGB 图像(我们不必对每个图像通道分别应用卷积)。
将victoria_memorial.png映像与sharpen内核和emboss内核一起使用:
im = misc.imread('../images/victoria_memorial.png').astype(np.float) # read as float
print(np.max(im))
sharpen_kernel = np.array([0, -1, 0, -1, 5, -1, 0, -1, 0]).reshape((3, 3, 1))
emboss_kernel = np.array(np.array([[-2,-1,0],[-1,1,1],[0,1,2]])).reshape((3, 3, 1))
im_sharp = ndimage.convolve(im, sharpen_kernel, mode='nearest')
im_sharp = np.clip(im_sharp, 0, 255).astype(np.uint8) # clip (0 to 255) and convert to unsigned int
im_emboss = ndimage.convolve(im, emboss_kernel, mode='nearest')
im_emboss = np.clip(im_emboss, 0, 255).astype(np.uint8)
pylab.figure(figsize=(10,15))
pylab.subplot(311), pylab.imshow(im.astype(np.uint8)), pylab.axis('off')
pylab.title('Original Image', size=25)
pylab.subplot(312), pylab.imshow(im_sharp), pylab.axis('off')
pylab.title('Sharpened Image', size=25)
pylab.subplot(313), pylab.imshow(im_emboss), pylab.axis('off')
pylab.title('Embossed Image', size=25)
pylab.tight_layout()
pylab.show()
您将获得这些卷积图像:

锐化后的图像如下所示:

浮雕图像如下所示:

相关与卷积
相关性与卷积运算非常相似,因为它还获取一个输入图像和另一个内核,并通过计算像素邻域值与内核值的加权组合,通过输入遍历内核窗口,并生成输出图像。
唯一的区别是,与相关性不同,卷积在计算加权组合之前会翻转内核两次(相对于水平轴和垂直轴)。
下一个图表从数学上描述了图像上的相关性和卷积之间的差异:

SciPy 信号模块的correlated2d() ...
图像与模板互相关的模板匹配
在本例中,我们将使用眼睛模板图像的互相关(使用图像的内核进行互相关),眼睛在浣熊面部图像中的位置如下所示:
face_image = misc.face(gray=True) - misc.face(gray=True).mean()
template_image = np.copy(face_image[300:365, 670:750]) # right eye
template_image -= template_image.mean()
face_image = face_image + np.random.randn(*face_image.shape) * 50 # add random noise
correlation = signal.correlate2d(face_image, template_image, boundary='symm', mode='same')
y, x = np.unravel_index(np.argmax(correlation), correlation.shape) # find the match
fig, (ax_original, ax_template, ax_correlation) = pylab.subplots(3, 1, figsize=(6, 15))
ax_original.imshow(face_image, cmap='gray')
ax_original.set_title('Original', size=20)
ax_original.set_axis_off()
ax_template.imshow(template_image, cmap='gray')
ax_template.set_title('Template', size=20)
ax_template.set_axis_off()
ax_correlation.imshow(correlation, cmap='afmhot')
ax_correlation.set_title('Cross-correlation', size=20)
ax_correlation.set_axis_off()
ax_original.plot(x, y, 'ro')
fig.show()
您已使用红点标记具有最大互相关值(与模板最佳匹配)的位置:

以下是模板:

应用互相关可获得以下输出:

从前面的图像可以看出,输入图像中浣熊的一只眼睛与眼睛模板图像的互相关度最高。
总结
我们讨论了一些主要与 2D DFT 及其在图像处理中的相关应用相关的重要概念,如频域滤波,并使用 scikit imagenumpy.fft、scipy.fftpack、signal和ndimage模块进行了大量示例。
希望您现在清楚采样和量化这两种重要的图像形成技术。我们已经看到了 2D DFT、FFT 算法的 Python 实现,以及图像去噪和恢复、DFT 在图像处理中的相关和卷积、卷积在滤波器设计中的应用以及相关在模板匹配中的应用。
您现在应该能够编写 Python 代码来执行。。。
问题
问题如下:
-
使用高斯 LPF 实现下采样和消除混叠(提示:先应用高斯滤波器,然后每隔一行和一列进行滤波,将房屋灰度图像减少四次。在下采样之前,比较是否使用 LPF 进行预处理的输出图像)
-
使用 FFT 对图像进行上采样:首先通过在每个交替位置填充零行/列,将
lena灰度图像的大小增加一倍,然后使用 FFT,然后使用 LPF,然后使用 IFFT 获得输出图像。它为什么有效? -
尝试用彩色(RGB)图像应用傅里叶变换和图像重建。(提示:对每个通道分别应用 FFT)。
-
用数学方法和 2D 核例子说明高斯核的傅里叶变换是另一个高斯核。
-
使用
lena图像和非对称 ripple 核生成具有相关和卷积的图像。显示输出图像不同。现在,翻转内核两次(颠倒和左右),并应用与翻转内核的相关性。输出图像是否与使用原始内核进行卷积获得的图像相同
进一步阅读
以下是各种来源的各种参考资料:
- 来自的课堂讲稿 http://fy.chalmers.se/~romeo/RRY025/notes/E1.pdf和http://web.pdx.edu/~jduh/courses/Archive/geog481w07/Students/Ludwig_ImageConvolution.pdf
- 这些幻灯片(https://web.cs.wpi.edu/~emmanuel/courses/cs545/S14/slides/讲师 10.pdf作者:emmanuel Agu 教授
- 牛津大学讲座:http://www.robots.ox.ac.uk/~az/touchts/ia/lect2.pdf*
三、卷积与频域滤波
在本章中,我们将继续讨论二维卷积,并了解如何在频域中更快地进行卷积(使用卷积定理的基本概念)。我们将通过图像上的一个示例来了解相关和卷积*之间的基本区别。我们还将描述来自 SciPy 的一个示例,该示例将展示如何使用互相关在具有模板图像的图像中找到特定图案的位置。最后,我们将描述频域中的几种滤波技术(可以使用*、核卷积实现,例如 box 核或 Gaussian 核),例如高通、低通、带通和带阻滤波器,以及如何通过示例使用 Python 库实现它们。我们将举例说明一些滤波器如何用于图像去噪(例如,band-reject或notch滤波器用于去除图像中的周期性噪声,或反向或维纳滤波器用于去除高斯/运动模糊核模糊的图像)。
**本章涉及的主题如下:
- 卷积定理与频域高斯模糊
- 频域滤波(使用 SciPy
ndimage模块和scikit-image)
卷积定理与频域高斯模糊
在本节中,我们将看到更多使用 Python 模块(如scipy signal和ndimage)对图像进行卷积的应用。让我们从卷积定理开始,看看卷积运算如何在频域变得更容易。
卷积定理的应用
卷积定理表示图像域中的卷积相当于频域中的简单乘法:
**
下图显示了傅里叶变换的应用:

下图显示了频域滤波的基本步骤。我们将原始图像 F*、*和内核(掩码或降级/增强函数)作为输入。首先,需要使用 DFT 将两个输入项转换为频域,然后应用卷积,根据卷积定理,卷积只是(元素)乘法。这将输出频域中的卷积图像,我们需要在其上应用 IDFT 以获得重建图像(原始图像上有一些退化或增强):

现在让我们在一些图像和一些 Python 库函数上看到定理的演示。我们需要像上一章一样导入所有必需的库。
基于 numpy-fft 的频域高斯模糊滤波器
以下代码块显示了如何使用卷积定理和numpy fft在频域中应用高斯滤波器(因为在频域中它只是乘法):
pylab.figure(figsize=(20,15))pylab.gray() # show the filtered result in grayscaleim = np.mean(imread('../images/lena.jpg'), axis=2)gauss_kernel = np.outer(signal.gaussian(im.shape[0], 5), signal.gaussian(im.shape[1], 5))freq = fp.fft2(im)assert(freq.shape == gauss_kernel.shape)freq_kernel = fp.fft2(fp.ifftshift(gauss_kernel))convolved = freq*freq_kernel # by the convolution theorem, simply multiply in the frequency domainim1 = fp.ifft2(convolved).realpylab.subplot(2,3,1), pylab.imshow(im), pylab.title('Original ...
频域中的高斯核
在本节中,我们将在二维和三维绘图中看到高斯核在频域中的样子。
二维中的高斯 LPF 核谱
下一个代码块显示如何使用log变换绘制二维高斯核的光谱:
im = rgb2gray(imread('../images/lena.jpg'))
gauss_kernel = np.outer(signal.gaussian(im.shape[0], 1), signal.gaussian(im.shape[1], 1))
freq = fp.fft2(im)
freq_kernel = fp.fft2(fp.ifftshift(gauss_kernel))
pylab.imshow( (20*np.log10( 0.01 + fp.fftshift(freq_kernel))).real.astype(int), cmap='coolwarm') # 0.01 is added to keep the argument to log function always positive
pylab.colorbar()
pylab.show()
下面的屏幕截图显示了前面代码的输出,带有一个颜色条。由于高斯核是一个低通滤波器,其频谱对于中心频率具有更高的值(它允许更多的低频值),并且随着远离中心到更高频率值的移动而逐渐减小:

下一个屏幕截图显示了沿响应轴的三维高斯核的频谱,有对数标度和没有对数标度。可以看出,高斯核的 DFT 是另一个高斯核。三维绘图的 Python 代码留给读者作为练习(问题 3,带有提示)。
3D中的高斯 LPF 核谱
水平面表示频域中高斯核响应的频率平面和垂直轴,不带对数轴和带对数轴:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rMvCv8la-1681961321688)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/dbb818fc-845c-4dc5-b7e8-09d2716b7ebd.png)]
带 scipy 信号的频域高斯模糊滤波器
以下代码块显示了如何使用 SciPy 信号模块的fftconvolve()函数在频域中运行卷积(内部仅通过乘法和卷积定理):
im = np.mean(misc.imread('../images/mandrill.jpg'), axis=2) print(im.shape)# (224, 225)gauss_kernel = np.outer(signal.gaussian(11, 3), signal.gaussian(11, 3)) # 2D Gaussian kernel of size 11x11 with σ = 3im_blurred = signal.fftconvolve(im, gauss_kernel, mode='same')fig, (ax_original, ax_kernel, ax_blurred) = pylab.subplots(1, 3, figsize=(20,8))ax_original.imshow(im, cmap='gray')ax_original.set_title('Original', size=20)ax_original.set_axis_off()ax_kernel.imshow(gauss_kernel) ...
比较 SciPy convolve()和 fftconvolve()与高斯模糊内核的运行时
我们可以使用 Pythontimeit模块来比较图像域和频域卷积函数的运行时。由于频域卷积涉及单个矩阵乘法,而不是一系列滑动窗口算术计算,因此预计其速度会快得多。以下代码比较运行时:
im = np.mean(misc.imread('../images/mandrill.jpg'), axis=2)
print(im.shape)
# (224, 225)
gauss_kernel = np.outer(signal.gaussian(11, 3), signal.gaussian(11, 3)) # 2D Gaussian kernel of size 11x11 with σ = 3
im_blurred1 = signal.convolve(im, gauss_kernel, mode="same")
im_blurred2 = signal.fftconvolve(im, gauss_kernel, mode='same')
def wrapper_convolve(func):
def wrapped_convolve():
return func(im, gauss_kernel, mode="same")
return wrapped_convolve
wrapped_convolve = wrapper_convolve(signal.convolve)
wrapped_fftconvolve = wrapper_convolve(signal.fftconvolve)
times1 = timeit.repeat(wrapped_convolve, number=1, repeat=100)
times2 = timeit.repeat(wrapped_fftconvolve, number=1, repeat=100)
下面的代码块使用这两种功能显示原始的 Mandrill 图像和模糊图像:
pylab.figure(figsize=(15,5))
pylab.gray()
pylab.subplot(131), pylab.imshow(im), pylab.title('Original Image',size=15), pylab.axis('off')
pylab.subplot(132), pylab.imshow(im_blurred1), pylab.title('convolve Output', size=15), pylab.axis('off')
pylab.subplot(133), pylab.imshow(im_blurred2), pylab.title('ffconvolve Output', size=15),pylab.axis('off')
下面的屏幕截图显示了前面代码的输出。正如所料,convolve()和fftconvolve()功能都会产生相同的模糊输出图像:

下面的代码可视化了运行时之间的差异。每个函数已在具有相同高斯核的相同输入图像上运行 100 次,然后绘制每个函数所用时间的箱线图:
data = [times1, times2]
pylab.figure(figsize=(8,6))
box = pylab.boxplot(data, patch_artist=True) #notch=True,
colors = ['cyan', 'pink']
for patch, color in zip(box['boxes'], colors):
patch.set_facecolor(color)
pylab.xticks(np.arange(3), ('', 'convolve', 'fftconvolve'), size=15)
pylab.yticks(fontsize=15)
pylab.xlabel('scipy.signal convolution methods', size=15)
pylab.ylabel('time taken to run', size = 15)
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,fftconvolve()平均运行速度更快:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G79G1rP9-1681961321688)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/8472af49-4dba-4ed8-97eb-9f853ad28a9c.png)]
频域滤波(HPF、LPF、BPF 和陷波滤波器)
如果我们记得在第 1 章中描述的图像处理管道中,开始图像处理,图像采集后的下一步是图像预处理。图像通常会因亮度和照明的随机变化而损坏,或者对比度较差,因此无法直接使用,需要增强。这是使用过滤器的地方。
什么是过滤器?
过滤是指变换像素强度值以显示某些图像特征,例如:
- 增强:此图像特征提高对比度
- 平滑:该图像特征去除噪声
- 模板匹配:该图像特征检测已知模式
滤波后的图像由离散卷积描述,滤波器由n x n离散卷积掩模描述。
高通滤波器(HPF)
该滤波器仅允许来自图像频域表示的高频(通过 DFT 获得),并阻止所有超出截止值的低频。图像用逆 DFT 重建,由于高频分量对应于边缘、细节、噪声等,HPFs 倾向于提取或增强它们。接下来的几节将演示如何使用numpy、scipy和scikit-image库中的不同函数来实现 HPF 以及 HPF 对图像的影响。
我们可以通过以下步骤在图像上实现 HPF:
- 使用
scipy.fftpack fft2执行 2D FFT,并获得图像的频域表示 - 仅保留高频分量(去除。。。
信噪比随频率截止值的变化
下面的代码块显示了如何用 HPF 的截止频率(F)绘制信噪比*(信噪比的变化:*
pylab.plot(lbs, snrs_hp, 'b.-')
pylab.xlabel('Cutoff Frequency for HPF', size=20)
pylab.ylabel('SNR', size=20)
pylab.show()
以下屏幕截图显示了输出图像的 SNR 如何随 HPF 截止频率的增加而降低:

低通滤波器(LPF)
该滤波器仅允许来自图像频域表示的低频(使用 DFT 获得),并阻止所有超过截止值的高频。图像用逆 DFT 重建,由于高频分量对应于边缘、细节、噪声等,LPF 倾向于去除这些。接下来的几节将演示如何使用numpy、scipy和scikit-image库中的不同函数来实现 LPF 以及 LPF 对图像的影响。
带 scipy ndimage 和 numpy fft 的 LPF
numpy fft模块的fft2()功能也可用于对图像运行 FFT。scipyndimage模块提供了一系列在频域中对图像应用 LPF 的功能。下一节将通过一个示例演示其中一个过滤器(即fourier_gaussian()。
傅里叶-高斯滤波器
来自 scipyndimage模块的此函数实现多维高斯傅里叶滤波器。频率阵列与给定大小的高斯核的傅里叶变换相乘。
下一个代码块演示如何使用 LPF(加权****平均滤波器)模糊lena灰度图像:
import numpy.fft as fpfig, (axes1, axes2) = pylab.subplots(1, 2, figsize=(20,10))pylab.gray() # show the result in grayscaleim = np.mean(imread('../images/lena.jpg'), axis=2)freq = fp.fft2(im)freq_gaussian = ndimage.fourier_gaussian(freq, sigma=4)im1 = fp.ifft2(freq_gaussian)axes1.imshow(im), axes1.axis('off'), axes2.imshow(im1.real) # the imaginary part is an artifactaxes2.axis('off')pylab.show()
以下是。。。
带 scipy fftpack 的 LPF
我们可以通过以下步骤在图像上实现 LPF:
- 使用
scipy.fftpack fft2执行 2D FFT,并获得图像的频域表示 - 仅保留低频分量(去除高频分量)
- 执行逆 FFT 以重建图像
下面的代码显示了实现 LPF 的 Python 代码。从下一个屏幕截图中可以看出,高频分量更多地对应于平均(平面)图像信息,随着我们去除越来越多的高频分量,图像的详细信息(例如,边缘)丢失。
例如,如果我们只保留第一个频率分量,而丢弃所有其他频率分量,在逆 FFT 后获得的结果图像中,我们几乎看不到犀牛,但随着我们保持越来越高的频率,它们在最终图像中变得突出:
from scipy import fftpack
im = np.array(Image.open('../images/rhino.jpg').convert('L'))
# low pass filter
freq = fp.fft2(im)
(w, h) = freq.shape
half_w, half_h = int(w/2), int(h/2)
freq1 = np.copy(freq)
freq2 = fftpack.fftshift(freq1)
freq2_low = np.copy(freq2)
freq2_low[half_w-10:half_w+11,half_h-10:half_h+11] = 0 # block the lowfrequencies
freq2 -= freq2_low # select only the first 20x20 (low) frequencies, block the high frequencies
im1 = fp.ifft2(fftpack.ifftshift(freq2)).real
print(signaltonoise(im1, axis=None))
# 2.389151856495427
pylab.imshow(im1, cmap='gray'), pylab.axis('off')
pylab.show()
以下屏幕截图显示了上述代码的输出,即在输入 rhino 图像上应用 LPF 获得的总输出图像,没有更精细的细节:

下面的代码块显示了如何在阻止高频后在对数域绘制图像的频谱;换句话说,仅允许低频:
pylab.figure(figsize=(10,10))
pylab.imshow( (20*np.log10( 0.1 + freq2)).astype(int))
pylab.show()
以下屏幕截图显示了前面代码的输出,即在图像上应用 LPF 后获得的光谱:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Id1GCCM0-1681961321689)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/a8ac3f38-accb-41c2-853e-5644afbe66b7.png)]
以下代码块显示了 LPF 在摄影师灰度图像上的应用,具有不同的频率截止值 F:
im = np.array(Image.open('../images/cameraman.jpg').convert('L'))
freq = fp.fft2(im)
(w, h) = freq.shape
half_w, half_h = int(w/2), int(h/2)
snrs_lp = []
ubs = list(range(1,25))
pylab.figure(figsize=(12,20))
for u in ubs:
freq1 = np.copy(freq)
freq2 = fftpack.fftshift(freq1)
freq2_low = np.copy(freq2)
freq2_low[half_w-u:half_w+u+1,half_h-u:half_h+u+1] = 0
freq2 -= freq2_low # select only the first 20x20 (low) frequencies
im1 = fp.ifft2(fftpack.ifftshift(freq2)).real
snrs_lp.append(signaltonoise(im1, axis=None))
pylab.subplot(6,4,u), pylab.imshow(im1, cmap='gray'), pylab.axis('off')
pylab.title('F = ' + str(u), size=20)
pylab.subplots_adjust(wspace=0.1, hspace=0)
pylab.show()
以下屏幕截图显示了随着截止频率F的增加,LPF 如何检测图像中越来越多的细节:


信噪比随截止频率的变化
下面的代码块显示了如何绘制 LPF 的截止频率(F)在信噪比(信噪比中的变化:
snr = signaltonoise(im, axis=None)pylab.plot(ubs, snrs_lp, 'b.-')pylab.plot(range(25), [snr]*25, 'r-')pylab.xlabel('Cutoff Freqeuncy for LPF', size=20)pylab.ylabel('SNR', size=20)pylab.show()
下面的屏幕截图显示了输出图像的 SNR 如何随着 LPF 截止频率的增加而降低。红色水平线表示原始图像的 SNR,绘制用于比较:

带狗形滤波器(BPF)
高斯(狗内核的差可以用作 BPF,允许某个频带内的频率,丢弃所有其他频率。下面的代码块显示了如何将 DoG 内核与fftconvolve()一起使用来实现 BPF:
from skimage import img_as_float
im = img_as_float(pylab.imread('../images/tigers.jpeg'))
pylab.figure(), pylab.imshow(im), pylab.axis('off'), pylab.show()
x = np.linspace(-10, 10, 15)
kernel_1d = np.exp(-0.005*x**2)
kernel_1d /= np.trapz(kernel_1d) # normalize the sum to 1
gauss_kernel1 = kernel_1d[:, np.newaxis] * kernel_1d[np.newaxis, :]
kernel_1d = np.exp(-5*x**2)
kernel_1d /= np.trapz(kernel_1d) # normalize the sum to 1
gauss_kernel2 = kernel_1d[:, np.newaxis] * kernel_1d[np.newaxis, :]
DoGKernel = gauss_kernel1[:, :, np.newaxis] - gauss_kernel2[:, :, np.newaxis]
im = signal.fftconvolve(im, DoGKernel, mode='same')
pylab.figure(), pylab.imshow(np.clip(im, 0, 1)), print(np.max(im)),
pylab.show()
以下屏幕截图显示了前面代码块的输出,即使用 BPF 获得的输出图像:

带阻(陷波)滤波器
该滤波器从图像的频域表示(使用 DFT 获得)中阻塞/拒绝一些选定的频率,因此得名。如下一节所述,它有助于从图像中去除周期性噪声。
使用陷波滤波器去除图像中的周期性噪声
在本例中,我们将首先向鹦鹉图像添加一些周期性(正弦)噪声,以创建一个有噪声的鹦鹉图像(这可能是由于干扰某些电信号造成的),然后使用以下代码块观察图像频域中噪声的影响:
from scipy import fftpack
pylab.figure(figsize=(15,10))
im = np.mean(imread("../images/parrot.png"), axis=2) / 255
print(im.shape)
pylab.subplot(2,2,1), pylab.imshow(im, cmap='gray'), pylab.axis('off')
pylab.title('Original Image')
F1 = fftpack.fft2((im).astype(float))
F2 = fftpack.fftshift( F1 )
pylab.subplot(2,2,2), pylab.imshow( (20*np.log10( 0.1 + F2)).astype(int), cmap=pylab.cm.gray)
pylab.xticks(np.arange(0, im.shape[1], 25))
pylab.yticks(np.arange(0, im.shape[0], 25))
pylab.title('Original Image Spectrum')
# add periodic noise to the image
for n in range(im.shape[1]):
im[:, n] += np.cos(0.1*np.pi*n)
pylab.subplot(2,2,3), pylab.imshow(im, cmap='gray'), pylab.axis('off')
pylab.title('Image after adding Sinusoidal Noise')
F1 = fftpack.fft2((im).astype(float)) # noisy spectrum
F2 = fftpack.fftshift( F1 )
pylab.subplot(2,2,4), pylab.imshow( (20*np.log10( 0.1 + F2)).astype(int), cmap=pylab.cm.gray)
pylab.xticks(np.arange(0, im.shape[1], 25))
pylab.yticks(np.arange(0, im.shape[0], 25))
pylab.title('Noisy Image Spectrum')
pylab.tight_layout()
pylab.show()
下面的屏幕截图显示了前面代码块的输出。可以看出,在 u=175 附近的频谱中,水平线上的周期性噪声变得更加突出:

现在,让我们设计一个带阻/带阻(陷波)滤波器,通过在下一个代码块中将相应的频率分量设置为零来消除产生噪声的频率:
F2[170:176,:220] = F2[170:176,230:] = 0 # eliminate the frequencies most likely responsible for noise (keep some low frequency components)
im1 = fftpack.ifft2(fftpack.ifftshift( F2 )).real
pylab.axis('off'), pylab.imshow(im1, cmap='gray'), pylab.show()
下面的屏幕截图显示了前面代码块的输出,即通过应用陷波滤波器恢复的图像。可以看出,原始图像看起来比恢复图像更清晰,因为来自原始图像的一些真实频率也被带阻滤波器与噪声一起拒绝:

图像复原
在图像恢复中,对退化进行建模。这可以(很大程度上)消除降解的影响。挑战在于信息和噪音的丢失。下图显示了基本图像退化模型:

在接下来的几节中,我们将描述两种退化模型(即逆和维纳滤波器)。
FFT 反褶积与反滤波
给定具有已知(假定)模糊核的模糊图像,典型的图像处理任务是恢复(至少是近似)原始图像。这个特殊的任务被称为反褶积。可以在频域中应用以实现这一点的简单滤波器之一是我们将在本节中讨论的逆滤波器。让我们首先使用以下代码使用高斯模糊对灰度lena图像进行模糊处理:
im = 255*rgb2gray(imread('../images/lena.jpg'))
gauss_kernel = np.outer(signal.gaussian(im.shape[0], 3),
signal.gaussian(im.shape[1], 3))
freq = fp.fft2(im)
freq_kernel = fp.fft2(fp.ifftshift(gauss_kernel)) # this is our H
convolved = freq*freq_kernel # by convolution theorem
im_blur = fp.ifft2(convolved).real
im_blur = 255 * im_blur / np.max(im_blur) # normalize
现在我们可以对模糊图像使用逆滤波器(使用相同的H)来恢复原始图像。以下代码块演示了如何执行此操作:
epsilon = 10**-6
freq = fp.fft2(im_blur)
freq_kernel = 1 / (epsilon + freq_kernel) # avoid division by zero
convolved = freq*freq_kernel
im_restored = fp.ifft2(convolved).real
im_restored = 255 * im_restored / np.max(im_restored)
print(np.max(im), np.max(im_restored))
pylab.figure(figsize=(10,10))
pylab.gray()
pylab.subplot(221), pylab.imshow(im), pylab.title('Original image'), pylab.axis('off')
pylab.subplot(222), pylab.imshow(im_blur), pylab.title('Blurred image'), pylab.axis('off')
pylab.subplot(223), pylab.imshow(im_restored), pylab.title('Restored image with inverse filter'), pylab.axis('off')
pylab.subplot(224), pylab.imshow(im_restored - im), pylab.title('Diff restored & original image'), pylab.axis('off')
pylab.show()
下面的屏幕截图显示了输出。可以看出,尽管逆滤波器对模糊图像进行去模糊处理,但仍存在一些信息损失:

以下屏幕截图分别以对数比例显示了逆核(HPF)、原始lena图像、高斯 LPF 模糊lena图像和恢复图像的频谱。Python 代码留给您作为练习(3):

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UeJJLIya-1681961321692)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/6748ffbe-99f2-4dfd-95d2-dfc7b4963bd9.png)]
如果输入图像有噪声,则逆滤波器(HPF)性能较差,因为噪声在输出图像中也会增强(参见问题部分中的问题 4)。
类似地,我们可以使用逆滤波器对使用已知运动模糊核模糊的图像进行去模糊。代码保持不变;只有内核发生了更改,如下面的代码所示。请注意,我们需要创建一个大小等于原始图像大小的零填充内核,然后才能在频域中应用卷积(使用np.pad();细节留给您作为练习):
kernel_size = 21 # a 21 x 21 motion blurred kernel
mblur_kernel = np.zeros((kernel_size, kernel_size))
mblur_kernel[int((kernel_size-1)/2), :] = np.ones(kernel_size)
mblur_kernel = mblur_kernel / kernel_size
# expand the kernel by padding zeros
以下屏幕截图显示了先前定义的运动模糊内核的频谱:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QeEvXDMY-1681961321692)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/5e5b2849-a619-43ff-b99a-f22d5a8070b4.png)]
以下屏幕截图显示了带有运动模糊图像的反向过滤器的输出:

用维纳滤波器进行图像反褶积
在上一节中,我们已经看到了如何使用逆滤波器从模糊图像(具有已知模糊核)中获得(近似)原始图像。图像处理中的另一个重要任务是去除损坏的信号中的噪声。这也称为图像恢复。以下代码块显示了如何使用scikit-image restoration模块的无监督维纳滤波器进行图像去噪和反褶积:
from skimage import color, data, restorationim = color.rgb2gray(imread('../images/elephant_g.jpg'))from scipy.signal import convolve2d as conv2n = 7psf = np.ones((n, n)) / n**2im1 = conv2(im, psf, 'same')im1 += 0.1 * astro.std() * np.random.standard_normal(im.shape) ...
基于 FFT 的图像去噪
下一个示例取自http://www.scipy-lectures.org/intro/scipy/auto_examples/solutions/plot_fft_image_denoise.html 。这个例子演示了如何通过使用 LPF 和 FFT 对高频傅里叶元素进行分块,首先对图像进行去噪。让我们首先使用以下代码块显示有噪灰度图像:
im = pylab.imread('../images/moonlanding.png').astype(float)
pylab.figure(figsize=(10,10))
pylab.imshow(im, pylab.cm.gray), pylab.axis('off'), pylab.title('Original image'), pylab.show()
以下屏幕截图显示了前面代码块的输出,即原始带噪图像:

以下代码块显示噪声图像的频谱:
from scipy import fftpack
from matplotlib.colors import LogNorm
im_fft = fftpack.fft2(im)
def plot_spectrum(im_fft):
pylab.figure(figsize=(10,10))
pylab.imshow(np.abs(im_fft), norm=LogNorm(vmin=5), cmap=pylab.cm.afmhot), pylab.colorbar()
pylab.figure(), plot_spectrum(fftpack.fftshift(im_fft))
pylab.title('Spectrum with Fourier transform', size=20)
以下屏幕截图显示了前面代码的输出,即原始噪声图像的傅里叶光谱:

FFT 中的滤波器
以下代码块显示了如何拒绝一组高频并实现 LPF 以衰减图像中的噪声(对应于高频分量):
# Copy the original spectrum and truncate coefficients.# Define the fraction of coefficients (in each direction) to keep askeep_fraction = 0.1im_fft2 = im_fft.copy()# Set r and c to the number of rows and columns of the array.r, c = im_fft2.shape# Set all rows to zero with indices between r*keep_fraction and r*(1-keep_fraction)im_fft2[int(r*keep_fraction):int(r*(1-keep_fraction))] = 0# Similarly with the columnsim_fft2[:, int(c*keep_fraction):int(c*(1-keep_fraction))] = 0pylab.figure(), plot_spectrum(fftpack.fftshift(im_fft2)),pylab.title('Filtered Spectrum') ...
重建最终图像
以下代码块显示了如何使用 IFFT 从过滤的傅里叶系数重建图像:
# Reconstruct the denoised image from the filtered spectrum, keep only the real part for display.
im_new = fp.ifft2(im_fft2).real
pylab.figure(figsize=(10,10)), pylab.imshow(im_new, pylab.cm.gray),
pylab.axis('off')
pylab.title('Reconstructed Image', size=20)
下面的屏幕截图显示了前面代码的输出,这是一个更清晰的输出图像,通过频域滤波从原始噪声图像中获得:

总结
在本章中,我们讨论了一些主要与二维卷积有关的重要概念及其在图像处理中的相关应用,如空域滤波。我们还讨论了几种不同的频域滤波技术,并用scikit-image numpy fft、scipy、fftpack、signal和ndimage模块的多个示例进行了说明。我们首先介绍卷积定理及其在频域滤波中的应用,各种频域滤波器,如 LPF、HPF 和陷波滤波器,最后介绍反卷积及其在设计图像恢复滤波器(如逆滤波器和维纳滤波器)中的应用。
完成本章后,读者应该能够编写 Python 代码。。。
问题
- 使用
mpl_toolkits.mplot3d模块在 3D 中绘制图像、高斯核和频域卷积后获得的图像的频谱(输出应类似于各部分所示的表面)。(提示:np.meshgrid()功能将在surface绘图中派上用场)。对反向过滤器也重复此练习。 - 向
lena图像添加一些随机噪声,用高斯核模糊图像,然后尝试使用逆滤波器恢复图像,如相应示例所示。发生了什么,为什么? - 使用 SciPy 信号的
fftconvolve()函数在频域中对彩色图像应用高斯模糊。 - 使用 SciPy 的
ndimage模块的fourier_uniform()和fourier_ellipsoid()功能,分别在频域中的图像上应用具有长方体和椭球核*、*的 LPF。
进一步阅读
- https://www.cs.cornell.edu/courses/cs1114/2013sp/sections/S06_convolution.pdf
- http://www.aip.de/groups/soe/local/numres/bookcpdf/c13-3.pdf
- http://www.cse.usf.edu/~r1k/MachineVisionBook/MachineVision.files/MachineVision_Chapter4.pdf
- https://web.stanford.edu/class/ee367/slides/lecture6.pdf
- https://pdfs.semanticscholar.org/presentation/50e8/fb095faf6ed51e03c85a2fcb7eb1ae1b1009.pdf
- http://www.robots.ox.ac.uk/~az/touchts/ia/lect2.pdf*****
四、图像增强
在本章中,我们将讨论图像处理中一些最基本的工具,如均值/中值滤波和直方图均衡化,它们仍然是最强大的工具之一。图像增强的目的是提高图像质量或使特定特征显得更加突出。这些技术是更通用的技术,并且不假设退化过程的强模型(与图像恢复不同)。图像增强技术的一些例子是对比度拉伸、平滑和锐化。我们将使用 Python 库函数和PIL、scikit-image和scipy ndimage库描述这些技术的基本概念和实现。我们将熟悉简单且仍然流行的方法。
我们将从逐点强度变换开始,然后讨论对比度拉伸、阈值、半色调和抖动算法,以及相应的 Python 库函数。然后,我们将讨论不同的直方图处理技术,如直方图均衡化(其全局和自适应版本)和直方图匹配。然后,将描述几种图像去噪技术。首先,将描述一些线性平滑技术,例如平均滤波器和高斯滤波器,然后是相对较新的非线性噪声平滑技术,例如中值滤波、双边滤波和非局部均值滤波,以及如何在 Python 中实现它们。最后,将描述具有数学形态学的不同图像操作及其应用,以及实现。
本章涉及的主题如下:
- 逐点强度变换–像素变换
- 直方图处理、直方图均衡化、直方图匹配
- 线性噪声平滑(平均滤波器)
- 非线性噪声平滑(中值滤波器)
逐点强度变换–像素变换
如在第 1 章开始图像处理中所述,逐点强度变换操作将传递函数T应用于输入图像的每个像素f(x,y),以在输出图像中生成对应的像素。变换可以表示为g(x,y)=T(f(x,y))或等效为s=T(r),其中r是输入图像中像素的灰度,s是输出图像中相同像素的变换灰度。这是一种无内存操作,位置(x、y处的输出强度仅取决于同一点的输入强度。相同强度的像素得到相同的变换。这不会带来新的信息。。。
对数变换
当我们需要压缩或拉伸图像中一定范围的灰度时,对数变换非常有用;例如,为了显示傅里叶频谱(其中直流分量值远高于其他分量,因此如果没有对数变换,几乎总是看不到其他频率分量)。对数变换的点变换函数为一般形式 ,其中c为常数*。*
,其中c为常数*。*
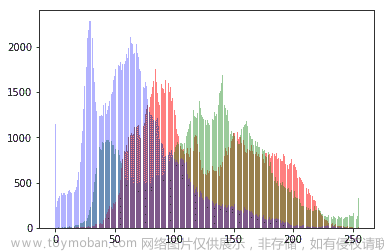
让我们实现输入图像颜色通道的直方图:
def plot_image(image, title=''):
pylab.title(title, size=20), pylab.imshow(image)
pylab.axis('off') # comment this line if you want axis ticks
def plot_hist(r, g, b, title=''):
r, g, b = img_as_ubyte(r), img_as_ubyte(g), img_as_ubyte(b)
pylab.hist(np.array(r).ravel(), bins=256, range=(0, 256), color='r', alpha=0.5)
pylab.hist(np.array(g).ravel(), bins=256, range=(0, 256), color='g', alpha=0.5)
pylab.hist(np.array(b).ravel(), bins=256, range=(0, 256), color='b', alpha=0.5)
pylab.xlabel('pixel value', size=20), pylab.ylabel('frequency', size=20)
pylab.title(title, size=20)
im = Image.open("../images/parrot.png")
im_r, im_g, im_b = im.split()
pylab.style.use('ggplot')
pylab.figure(figsize=(15,5))
pylab.subplot(121), plot_image(im, 'original image')
pylab.subplot(122), plot_hist(im_r, im_g, im_b,'histogram for RGB channels')
pylab.show()
以下屏幕截图显示了应用对数变换前原始图像颜色通道直方图的输出:

现在,让我们使用 PIL 图像模块的point()功能应用对数变换,并对 RGB 图像不同颜色通道直方图的变换产生影响:
im = im.point(lambda i: 255*np.log(1+i/255))
im_r, im_g, im_b = im.split()
pylab.style.use('ggplot')
pylab.figure(figsize=(15,5))
pylab.subplot(121), plot_image(im, 'image after log transform')
pylab.subplot(122), plot_hist(im_r, im_g, im_b, 'histogram of RGB channels log transform')
pylab.show()
输出显示了不同颜色通道的直方图压缩方式:

幂律变换
正如我们已经看到的,使用第 1 章中的 PILpoint()函数,开始图像处理中的点变换(传递函数为一般形式,s=T(r)=c.rγ,其中c为常数)在灰度图像上进行,这次让我们对带有scikit-image的 RGB 彩色图像应用幂律变换,然后可视化变换对颜色通道直方图的影响:
im = img_as_float(imread('../images/earthfromsky.jpg'))gamma = 5im1 = im**gammapylab.style.use('ggplot')pylab.figure(figsize=(15,5))pylab.subplot(121), plot_hist(im[...,0], im[...,1], im[...,2], 'histogram for RGB channels (input)')pylab.subplot(122), plot_hist(im1[...,0], im1[...,1], im1[...,2], 'histogram for RGB channels ...
对比拉伸
对比度拉伸操作将低对比度图像作为输入,并拉伸较窄的强度值范围以跨越期望的较宽值范围,以便输出高对比度输出图像,从而增强图像的对比度。它只是一个应用于图像像素值的线性缩放函数,因此图像增强没有那么剧烈(与其更复杂的对应直方图均衡化相比,稍后将进行描述)。以下屏幕截图显示了对比度拉伸的点变换功能:

从前面的屏幕截图可以看出,在可以执行拉伸之前,需要指定像素值上限和下限(图像将在其上被归一化)(例如,对于灰度图像,限制通常设置为 0 和 255,以便输出图像跨越可用像素值的整个范围)。我们需要从原始图像的 CDF 中找到一个合适的值m。对比度拉伸变换通过使原始图像中的值m以下的级别变暗(换言之,将值拉伸到下限),并使值m之前的级别变亮(将值拉伸到上限),从而产生比原始图像更高的对比度在原始图像中。以下各节介绍如何使用 PIL 库实现对比度拉伸。
使用 PIL 作为点操作
让我们首先加载一个彩色 RGB 图像,并将其跨颜色通道分割,以可视化不同颜色通道的像素值直方图:
im = Image.open('../images/cheetah.png')im_r, im_g, im_b, _ = im.split()pylab.style.use('ggplot')pylab.figure(figsize=(15,5))pylab.subplot(121)plot_image(im)pylab.subplot(122)plot_hist(im_r, im_g, im_b)pylab.show()
下面的屏幕截图显示了上一个代码块的输出。可以看出,输入的猎豹图像是低对比度图像,因为颜色通道直方图集中在特定的值范围内(右偏),而不是分布在所有可能的像素值上:
对比度拉伸操作拉伸过度集中的灰度。。。
使用 PIL 图像增强模块
ImageEnhance模块也可用于对比度拉伸。下面的代码块显示了如何使用来自对比度对象的enhance()方法来增强相同输入图像的对比度:
contrast = ImageEnhance.Contrast(im)
im1 = np.reshape(np.array(contrast.enhance(2).getdata()).astype(np.uint8), (im.height, im.width, 4))
pylab.style.use('ggplot')
pylab.figure(figsize=(15,5))
pylab.subplot(121), plot_image(im1)
pylab.subplot(122), plot_hist(im1[...,0], im1[...,1], im1[...,2]), pylab.yscale('log',basey=10)
pylab.show()
下面显示了代码的输出。可以看出,输入图像的对比度增强,颜色通道直方图向端点拉伸:

阈值
这是一个点操作,通过将低于某个阈值的所有像素变为零,将高于该阈值的所有像素变为一,从灰度图像创建二值图像,如以下屏幕截图所示:

如果g(x,y)是f(x,y)在某个全局阈值T下的阈值版本,则可以应用以下内容:

为什么我们需要一个二进制图像?有几个原因,例如,我们可能对将图像分为前景和背景感兴趣;该图像将使用黑白打印机打印(以及所有。。。
有固定的门槛
下面的代码块显示了如何使用 PILpoint()功能对固定阈值进行阈值化:
im = Image.open('../images/swans.jpg').convert('L')
pylab.hist(np.array(im).ravel(), bins=256, range=(0, 256), color='g')
pylab.xlabel('Pixel values'), pylab.ylabel('Frequency'),
pylab.title('Histogram of pixel values')
pylab.show()
pylab.figure(figsize=(12,18))
pylab.gray()
pylab.subplot(221), plot_image(im, 'original image'), pylab.axis('off')
th = [0, 50, 100, 150, 200]
for i in range(2, 5):
im1 = im.point(lambda x: x > th[i])
pylab.subplot(2,2,i), plot_image(im1, 'binary image with threshold=' + str(th[i]))
pylab.show()
下面的屏幕截图显示了前面代码的输出。首先,我们可以从以下方面看到输入图像中像素值的分布:

此外,从下面可以看出,使用不同灰度阈值获得的二值图像未正确着色,导致被称为**假轮廓的伪像:
*

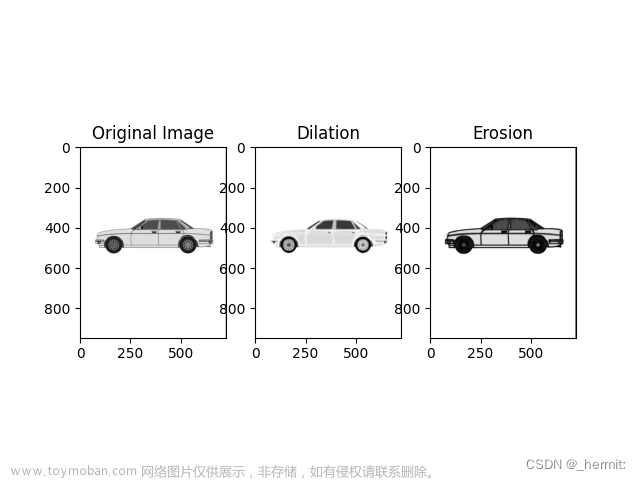
在讨论图像分割时,我们将在第 6 章、形态学图像处理中详细讨论几种不同的阈值算法。
半色调
在阈值化(二进制量化)中减少假轮廓伪影的一种方法是在量化之前向输入图像添加均匀分布的白噪声。具体地说,对于灰度图像的每个输入像素,f(x,y),我们添加一个独立的均匀[-128128]随机数,然后进行阈值化。这种技术被称为半色调。以下代码块显示了一个实现:
im = Image.open('../images/swans.jpg').convert('L')im = Image.fromarray(np.clip(im + np.random.randint(-128, 128, (im.height, im.width)), 0, 255).astype(np.uint8))pylab.figure(figsize=(12,18))pylab.subplot(221), plot_image(im, 'original image (with noise)')th = [0, 50, 100, 150, 200]for i in range(2, 5): im1 = im.point(lambda ...
具有误差扩散的 Floyd-Steinberg 抖动
同样,为了防止大规模模式(例如假轮廓),使用有意应用的噪声形式来随机化量化误差。这个过程被称为抖动。Floyd Steinberg 算法使用误差扩散技术实现抖动,换句话说,它将像素的剩余量化误差推(加)到相邻像素上,稍后处理。它根据以下屏幕截图中所示的分布将量化误差展开,作为相邻像素的映射:

在先前的截图中,当前像素用星(*)表示,空白像素表示先前扫描的像素。该算法从左到右、从上到下扫描图像。每次量化误差分布在相邻像素(尚未被扫描)之间时,它依次量化像素值,而不影响已经被量化的像素。因此,如果已向下舍入多个像素,则更可能通过算法向上舍入后续像素,从而使平均量化误差接近于零。
以下屏幕截图显示了算法伪代码:

下面的屏幕截图显示了使用前面伪代码的 Python 实现获得的输出二进制图像;与之前的半色调方法相比,它在获得的二值图像质量方面有了显著的改进:

代码留作练习。
直方图处理–直方图均衡化和匹配
直方图处理技术为改变图像中像素值的动态范围提供了更好的方法,从而使其强度直方图具有所需的形状。正如我们所看到的,对比度拉伸操作的图像增强受到限制,因为它只能应用线性缩放函数。
通过使用非线性(非单调)传递函数将输入像素强度映射到输出像素强度,直方图处理技术可以更强大。在本节中,我们将使用scikit-image库的曝光模块演示两种技术的实现,即直方图均衡化和直方图匹配。。。
基于 scikit 图像的对比度拉伸和直方图均衡化
直方图均衡化使用单调和非线性映射,该映射重新分配输入图像中的像素强度值,使得输出图像具有均匀的强度分布(平坦直方图),从而增强图像的对比度。下面的屏幕截图描述了直方图均衡化的转换函数:

下面的代码块显示了如何使用曝光模块的equalize_hist()功能对 scikit 图像*进行直方图均衡化。*直方图均衡化实现有两种不同的风格:一种是对整个图像进行全局操作,另一种是局部(自适应)操作,通过将图像划分为块并在每个块上运行直方图均衡化来完成:
img = rgb2gray(imread('../images/earthfromsky.jpg'))
# histogram equalization
img_eq = exposure.equalize_hist(img)
# adaptive histogram equalization
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)
pylab.gray()
images = [img, img_eq, img_adapteq]
titles = ['original input (earth from sky)', 'after histogram equalization', 'after adaptive histogram equalization']
for i in range(3):
pylab.figure(figsize=(20,10)), plot_image(images[i], titles[i])
pylab.figure(figsize=(15,5))
for i in range(3):
pylab.subplot(1,3,i+1), pylab.hist(images[i].ravel(), color='g'), pylab.title(titles[i], size=15)
pylab.show()
下面的屏幕截图显示了上一个代码块的输出。可以看出,直方图均衡化后,输出图像的直方图变得几乎均匀(以x轴表示像素值,以y轴表示对应的频率),尽管自适应直方图均衡化比全局直方图均衡化更清楚地揭示了图像的细节:


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t2p3OTDq-1681961321697)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/ea138e57-e7c5-4c9e-8625-10d36c704fb2.png)]
以下屏幕截图显示了局部(近似均匀)与自适应(拉伸和分段均匀)直方图均衡化的像素分布变化情况:

以下代码块将使用两种不同的直方图处理技术(即对比度拉伸和直方图均衡化)获得的图像增强与scikit-image进行比较:
import matplotlib
matplotlib.rcParams['font.size'] = 8
def plot_image_and_hist(image, axes, bins=256):
image = img_as_float(image)
axes_image, axes_hist = axes
axes_cdf = axes_hist.twinx()
axes_image.imshow(image, cmap=pylab.cm.gray)
axes_image.set_axis_off()
axes_hist.hist(image.ravel(), bins=bins, histtype='step', color='black')
axes_hist.set_xlim(0, 1)
axes_hist.set_xlabel('Pixel intensity', size=15)
axes_hist.ticklabel_format(axis='y', style='scientific', scilimits=(0, 0))
axes_hist.set_yticks([])
image_cdf, bins = exposure.cumulative_distribution(image, bins)
axes_cdf.plot(bins, image_cdf, 'r')
axes_cdf.set_yticks([])
return axes_image, axes_hist, axes_cdf
im = io.imread('../images/beans_g.png')
# contrast stretching
im_rescale = exposure.rescale_intensity(im, in_range=(0, 100), out_range=(0, 255))
im_eq = exposure.equalize_hist(im) # histogram equalization
im_adapteq = exposure.equalize_adapthist(im, clip_limit=0.03) # adaptive histogram equalization
fig = pylab.figure(figsize=(15, 7))
axes = np.zeros((2, 4), dtype = np.object)
axes[0, 0] = fig.add_subplot(2, 4, 1)
for i in range(1, 4):
axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0])
for i in range(0, 4):
axes[1, i] = fig.add_subplot(2, 4, 5+i)
axes_image, axes_hist, axes_cdf = plot_image_and_hist(im, axes[:, 0])
axes_image.set_title('Low contrast image', size=20)
y_min, y_max = axes_hist.get_ylim()
axes_hist.set_ylabel('Number of pixels', size=20)
axes_hist.set_yticks(np.linspace(0, y_max, 5))
axes_image, axes_hist, axes_cdf = plot_image_and_hist(im_rescale, axes[:,1])
axes_image.set_title('Contrast stretching', size=20)
axes_image, axes_hist, axes_cdf = plot_image_and_hist(im_eq, axes[:, 2])
axes_image.set_title('Histogram equalization', size=20)
axes_image, axes_hist, axes_cdf = plot_image_and_hist(im_adapteq, axes[:,3])
axes_image.set_title('Adaptive equalization', size=20)
axes_cdf.set_ylabel('Fraction of total intensity', size=20)
axes_cdf.set_yticks(np.linspace(0, 1, 5))
fig.tight_layout()
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,自适应直方图均衡化在使输出图像的细节更清晰方面提供了比直方图均衡化更好的结果:

使用低对比度彩色 cheetah 输入图像,前面的代码生成以下输出:

直方图匹配
直方图匹配是一个过程,其中图像的直方图与另一参考(模板)图像的直方图相匹配。算法如下:
- 将为每个图像计算累积直方图,如以下屏幕截图所示。
- 对于任意给定的像素值x**i【待调整】在输入图像中,我们需要通过匹配输入图像的直方图和模板图像的直方图,在输出图像中找到对应的像素值x**j。
-
x*i像素值具有由G(x**i给出的累积直方图值。找到一个像素值*xj,使得参考图像中的累积分布值,即H(x**j)等于【T28 G(xi。
** 将输入数据值*xi替换为x*j:*
*# RGB 图像的直方图匹配
对于每个颜色通道,可以独立进行匹配,以获得如下输出:

输出图像

实现这一点的 Python 代码留给读者作为练习(问题部分的问题 1)。
线性噪声平滑
线性(空间)滤波是一种具有(邻域中)像素值加权和的函数。它是对图像的线性操作,可用于模糊/降噪。在预处理步骤中使用模糊;例如,删除小的(不相关的)细节。几种常用的线性滤波器是盒滤波器和高斯滤波器。滤波器是用一个小的(例如,3 x 3)内核(mask)实现的,通过在输入图像上滑动 mask 并将滤波器函数应用于输入图像中的每个可能像素来重新计算像素值(与遮罩对应的输入图像的中心像素值被像素值的加权和替换,并带有来自遮罩的权重)。。。
PIL 光整
以下各节说明如何使用 PILImageFilter模块的功能进行线性噪声平滑;换句话说,使用线性滤波器进行噪声平滑。
使用 ImageFilter.BLUR 进行平滑
以下显示了如何使用 PILImageFilter模块的滤波功能应用模糊来消除噪声图像。输入图像上的噪声级别会发生变化,以查看其对模糊过滤器的影响。本例的输入图像使用流行的 mandrill(狒狒)图像;图像受知识共享许可证(的保护 https://creativecommons.org/licenses/by-sa/2.0/ ),可在找到 https://www.flickr.com/photos/uhuru1701/2249220078 并在 SIPI 图像数据库中:http://sipi.usc.edu/database/database.php?volume=misc &图像=10#顶部:
i = 1pylab.figure(figsize=(10,25))for prop_noise in np.linspace(0.05,0.3,3): im = Image.open('../images/mandrill.jpg') # choose 5000 random locations inside ...
使用框模糊核进行平均平滑
下面的代码块显示了如何使用 PILImageFilter.Kernel()函数和大小为 3 x 3 和 5 x 5 的框模糊核(平均滤波器)平滑带噪图像:
im = Image.open('../images/mandrill_spnoise_0.1.jpg')
pylab.figure(figsize=(20,7))
pylab.subplot(1,3,1), pylab.imshow(im), pylab.title('Original Image', size=30), pylab.axis('off')
for n in [3,5]:
box_blur_kernel = np.reshape(np.ones(n*n),(n,n)) / (n*n)
im1 = im.filter(ImageFilter.Kernel((n,n), box_blur_kernel.flatten()))
pylab.subplot(1,3,(2 if n==3 else 3))
plot_image(im1, 'Blurred with kernel size = ' + str(n) + 'x' + str(n))
pylab.suptitle('PIL Mean Filter (Box Blur) with different Kernel size',
size=30)
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,输出图像是通过将较大尺寸的框模糊核与平滑的噪声图像卷积而获得的:

高斯模糊滤波器的平滑
高斯模糊滤波器也是一种线性滤波器,但与简单平均滤波器不同,它采用内核窗口内像素的加权平均值来平滑像素(对应于相邻像素的权重随相邻像素到像素的距离呈指数下降)。以下代码显示了如何使用 PILImageFilter.GaussianBlur()来平滑具有不同内核半径参数值的噪声较大的图像:
im = Image.open('../images/mandrill_spnoise_0.2.jpg')pylab.figure(figsize=(20,6))i = 1for radius in range(1, 4): im1 = im.filter(ImageFilter.GaussianBlur(radius)) pylab.subplot(1,3,i), plot_image(im1, 'radius = ' + str(round(radius,2))) i += 1pylab.suptitle('PIL ...
使用 SciPy ndimage 比较盒核和高斯核的平滑
我们也可以使用 SciPy 的ndimage模块函数将线性滤波器应用于平滑图像。下面的代码片段演示了将线性滤波器应用于因脉冲(椒盐)噪声而退化的顶钻图像的结果:
from scipy import misc, ndimage
import matplotlib.pylab as pylab
im = misc.imread('../images/mandrill_spnoise_0.1.jpg')
k = 7 # 7x7 kernel
im_box = ndimage.uniform_filter(im, size=(k,k,1))
s = 2 # sigma value
t = (((k - 1)/2)-0.5)/s # truncate parameter value for a kxk gaussian kernel with sigma s
im_gaussian = ndimage.gaussian_filter(im, sigma=(s,s,0), truncate=t)
fig = pylab.figure(figsize=(30,10))
pylab.subplot(131), plot_image(im, 'original image')
pylab.subplot(132), plot_image(im_box, 'with the box filter')
pylab.subplot(133), plot_image(im_gaussian, 'with the gaussian filter')
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,与σ=2 的相同大小的高斯滤波器相比,相同内核大小的盒滤波器对输出图像的模糊程度更高:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WTHtuAFL-1681961321699)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/57e43eca-0ad3-4173-bd1c-6af8e612b4a7.png)]
非线性噪声平滑
非线性(空间)滤波器也作用于邻域,通过像线性滤波器一样在图像上滑动内核(掩码)来实现。然而,滤波操作是有条件地基于邻域中像素的值,并且它们通常不以乘积和的方式显式地使用系数。例如,可以使用非线性滤波器有效地降低噪声,其基本功能是计算滤波器所在邻域中的中值灰度值。该滤波器是非线性滤波器,因为中值计算是非线性运算。中值滤波器非常流行,因为对于某些类型的随机噪声(例如,脉冲噪声),它们。。。
PIL 光整
PILImageFilter模块提供一组用于图像非线性去噪的功能。在本节中,我们将用示例演示其中的一些。
使用中值滤波器
中值滤波器用相邻像素值的中值替换每个像素。此过滤器非常适合去除椒盐噪声,尽管它可以去除图像中的小细节。我们需要对邻域强度进行排名,然后选择中间值。中值滤波对统计异常值具有弹性,模糊程度较低,且易于实现。下面的代码块显示了如何使用 PILImageFilter模块的MedianFilter()函数,在添加不同级别的噪声和用于中值滤波器的不同大小的内核窗口的情况下,从带噪的山楂图像中去除椒盐噪声:
i = 1pylab.figure(figsize=(25,35))for prop_noise in np.linspace(0.05,0.3,3): ...
使用最大和最小过滤器
下面的代码显示了如何使用MaxFilter()去除图像中的椒盐噪声,然后使用MinFilter()去除图像中的椒盐噪声:
im = Image.open('../images/mandrill_spnoise_0.1.jpg')
pylab.subplot(1,3,1)
plot_image(im, 'Original Image with 10% added noise')
im1 = im.filter(ImageFilter.MaxFilter(size=sz))
pylab.subplot(1,3,2), plot_image(im1, 'Output (Max Filter size=' + str(sz) + ')')
im1 = im1.filter(ImageFilter.MinFilter(size=sz))
pylab.subplot(1,3,3), plot_image(im1, 'Output (Min Filter size=' + str(sz) + ')', size=15)
pylab.show()
下面的屏幕截图显示了上一个代码块的输出。可以看出,最大和最小滤波器分别在去除噪声图像中的椒盐噪声方面有一定的效果:

使用 scikit 图像平滑(去噪)
scikit-image库还在恢复模块中提供了一组非线性滤波器。在以下部分中,我们将讨论两个非常有用的过滤器,即双边和非局部均值过滤器。
使用双边滤波器
双边滤波器是一种边缘保持平滑滤波器。对于该过滤器,中心像素被设置为其某些相邻像素值的加权平均值,只有亮度与中心像素大致相似的像素。在本节中,我们将了解如何使用scikit-image包的双边滤波器实现对图像进行去噪。首先,让我们从以下灰度级山脉图像创建一个带噪图像:

下面的代码块演示如何使用 numpyrandom_noise()函数:
im = color.rgb2gray(img_as_float(io.imread('../images/mountain.png')))
sigma = 0.155
noisy = random_noise(im, var=sigma**2)
pylab.imshow(noisy)
下面的屏幕截图显示了通过使用前面的代码将随机噪声添加到原始图像中而创建的噪声图像:

下面的代码块演示了如何使用双边滤波器对先前的噪声图像进行去噪,参数σ颜色和*σ空间*的值不同:
pylab.figure(figsize=(20,15))
i = 1
for sigma_sp in [5, 10, 20]:
for sigma_col in [0.1, 0.25, 5]:
pylab.subplot(3,3,i)
pylab.imshow(denoise_bilateral(noisy, sigma_color=sigma_col,
sigma_spatial=sigma_sp, multichannel=False))
pylab.title(r'$\sigma_r=$' + str(sigma_col) + r', $\sigma_s=$' + str(sigma_sp), size=20)
i += 1
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,如果标准偏差更高,图像会变得更模糊,但噪声更小。执行上一个代码块需要几分钟,因为在 RGB 图像上的实现速度更慢:

使用非本地手段
非局部平均是一种保留纹理的非线性去噪算法。在该算法中,对于任何给定像素,仅使用与感兴趣像素具有相似局部邻居的相邻像素的值的加权平均值来设置给定像素的值。换句话说,将以其他像素为中心的小面片与以感兴趣像素为中心的面片进行比较。在本节中,我们将通过使用非局部均值滤波器对带噪鹦鹉图像进行去噪来演示该算法。函数的h参数控制面片权重的衰减,作为面片之间距离的函数。如果h较大,则允许不同面片之间更平滑。下面的代码块显示。。。
使用 scipy ndimage 进行平滑
scipyndimage模块提供一个名为percentile_filter()的函数,它是中值滤波器的通用版本。以下代码块演示如何使用此筛选器:
lena = misc.imread('../images/lena.jpg')
# add salt-and-pepper noise to the input image
noise = np.random.random(lena.shape)
lena[noise > 0.9] = 255
lena[noise < 0.1] = 0
plot_image(lena, 'noisy image')
pylab.show()
fig = pylab.figure(figsize=(20,15))
i = 1
for p in range(25, 100, 25):
for k in range(5, 25, 5):
pylab.subplot(3,4,i)
filtered = ndimage.percentile_filter(lena, percentile=p, size=(k,k,1))
plot_image(filtered, str(p) + ' percentile, ' + str(k) + 'x' + str(k) + ' kernel')
i += 1
pylab.show()
下面的屏幕截图显示了前面代码的输出。可以看出,在所有百分位滤波器中,具有较小内核大小的中值滤波器(对应于第 50 个第百分位)能够最好地去除椒盐噪声,同时丢失图像中尽可能少的细节:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gCMjzgIF-1681961331098)(null)]
总结
在本章中,我们讨论了不同的图像增强方法,从点变换(例如,对比度拉伸和阈值)开始,然后是基于直方图处理的技术(例如,直方图均衡化和直方图匹配),然后是基于线性(例如,均值和高斯)的图像去噪技术和非线性(例如,中值、双边和非局部均值)滤波器。
到本章结束时,读者应该能够为点变换(例如,负片、幂律变换和对比度拉伸)、基于直方图的图像增强(例如,直方图均衡化/匹配)和图像去噪(例如,均值/中值滤波器)编写 Python 代码。。。
问题
- 实现彩色 RGB 图像的直方图匹配。
- 使用
skimage.filters.rank中的equalize()函数实现局部直方图均衡化,并将其与具有灰度图像的skimage.exposure中的全局直方图均衡化进行比较。 - 使用此处描述的算法实现 Floyd Steinberg 误差扩散抖动 https://en.wikipedia.org/wiki/Floyd%E2%80%93Steinberg_dithering 并将灰度图像转换为二值图像。
- 使用 PIL 中的
ModeFilter()对图像进行线性平滑。什么时候有用? - 显示一幅图像,该图像可以从几个噪声图像中恢复,这些图像是通过简单地取噪声图像的平均值,将随机高斯噪声添加到原始图像中获得的。中位数也有用吗?
进一步阅读
- http://paulbourke.net/miscellaneous/equalisation/
- https://pdfs.semanticscholar.org/presentation/3fb7/fa0fca1bab83d523d882e98efa0f5769ec64.pdf
- https://www.comp.nus.edu.sg/~cs4243/doc/SciPy%20reference.pdf
- https://en.wikipedia.org/wiki/Floyd%E2%80%93Steinberg_dithering
- https://en.wikipedia.org/wiki/Floyd%E2%80%93Steinberg_dithering**
五、基于导数的图像增强
在本章中,我们将继续讨论图像增强,即改善图像外观或有用性的问题。我们将主要关注用于计算图像梯度/导数的空间滤波技术,以及如何将这些技术用于图像中的边缘检测。首先,我们将从使用一阶(偏)导数的图像梯度的基本概念开始,如何计算离散导数,然后讨论二阶导数/拉普拉斯算子。我们将看到如何使用它们在图像中查找边缘。接下来,我们将讨论使用 Python 图像处理库 PIL、scikit-image的过滤模块和 SciPy 的ndimage模块对图像进行锐化/去锐化的几种方法。接下来,我们将了解如何使用不同的过滤器(sobel、canny、LoG等)并将其与图像卷积以检测图像中的边缘。最后,我们将讨论如何计算高斯/拉普拉斯图像金字塔(使用scikit-image),并使用图像金字塔平滑混合两幅图像。本章涉及的主题如下:
- 图像导数梯度,拉普拉斯
- 锐化和去锐化遮罩(带 PIL,
scikit-image、SciPyndimage) - 使用导数和滤波器进行边缘检测(Sobel、Canny、LOG、DOG 等,使用 PIL,
scikit-image - 图像金字塔(高斯和拉普拉斯)-混合图像(带
scikit-image
图像导数-梯度和拉普拉斯
我们可以用有限差分法计算数字图像的(偏)导数。在本节中,让我们讨论如何计算图像导数、梯度和拉普拉斯函数,以及它们为什么有用。通常,让我们从导入所需的库开始,如以下代码块所示:
import numpy as npfrom scipy import signal, misc, ndimagefrom skimage import filters, feature, img_as_floatfrom skimage.io import imreadfrom skimage.color import rgb2grayfrom PIL import Image, ImageFilterimport matplotlib.pylab as pylab
导数和梯度
下图显示了如何使用有限差分(具有正向和中心差分,后者更精确)计算图像I(这是一个函数f(x,y))的偏导数,可以使用卷积和所示的内核来实现。该图还定义了梯度向量、其大小(对应于边的强度)和方向(垂直于边)。输入图像中强度(灰度值)急剧变化的位置对应于图像一阶导数强度中存在峰值/尖峰(或低谷)的位置。换句话说,梯度幅值中的峰值标记边缘位置,我们需要对梯度幅值设置阈值,以在图像中找到边缘:

下面的代码块显示了如何使用前面显示的卷积核计算梯度(以及幅度和方向),并将灰度国际象棋图像作为输入。它还绘制图像像素值和梯度向量的 x 分量如何随图像中第一行的 y 坐标变化(x=0):
def plot_image(image, title):
pylab.imshow(image), pylab.title(title, size=20), pylab.axis('off')
ker_x = [[-1, 1]]
ker_y = [[-1], [1]]
im = rgb2gray(imread('../images/chess.png'))
im_x = signal.convolve2d(im, ker_x, mode='same')
im_y = signal.convolve2d(im, ker_y, mode='same')
im_mag = np.sqrt(im_x**2 + im_y**2)
im_dir = np.arctan(im_y/im_x)
pylab.gray()
pylab.figure(figsize=(30,20))
pylab.subplot(231), plot_image(im, 'original'), pylab.subplot(232), plot_image(im_x, 'grad_x')
pylab.subplot(233), plot_image(im_y, 'grad_y'), pylab.subplot(234), plot_image(im_mag, '||grad||')
pylab.subplot(235), plot_image(im_dir, r'$\theta$'), pylab.subplot(236)
pylab.plot(range(im.shape[1]), im[0,:], 'b-', label=r'$f(x,y)|_{x=0}$', linewidth=5)
pylab.plot(range(im.shape[1]), im_x[0,:], 'r-', label=r'$grad_x (f(x,y))|_{x=0}$')
pylab.title(r'$grad_x (f(x,y))|_{x=0}$', size=30)
pylab.legend(prop={'size': 20})
pylab.show()
下图显示了前面代码块的输出。从下图可以看出,x 和 y 方向上的偏导数分别检测图像中的垂直和水平边缘。梯度大小显示图像中不同位置的边缘强度。此外,如果我们从对应于一行(例如,第 0 行)的原始图像中拾取所有像素,我们可以看到一个方波(对应于交替的白色和黑色强度模式),而同一组像素的梯度大小在强度上有尖峰(突然增加/减少),这些对应于(垂直)边缘:


在同一图像上显示幅值和渐变
在前面的示例中,边缘的大小和方向显示在不同的图像中。我们可以创建一个 RGB 图像,并将R、G和B的值设置为如下,以在同一图像中显示大小和方向:

使用与上一个示例中相同的代码,我们仅使用以下代码替换右下子批次代码:
im = np.zeros((im.shape[0],im.shape[1],3))im[...,0] = im_mag*np.sin(im_ang)im[...,1] = im_mag*np.cos(im_ang)pylab.title(r'||grad||+$\theta$', size=30), pylab.imshow(im), pylab.axis('off')
然后,使用老虎图像,我们得到显示的输出。。。
拉普拉斯的
Rosenfeld 和 Kak 已经证明,最简单的各向同性导数算子是拉普拉斯算子,其定义如下图所示。拉普拉斯算子逼近图像的二阶导数并检测边缘。它是各向同性(旋转不变)算子,零交叉标记边缘位置;我们将在本章后面讨论更多关于这一点的内容。换句话说,在输入图像的一阶导数有尖峰/尖峰(或低谷)的位置,在输入图像的二阶导数的相应位置有过零:

关于拉普拉斯算子的几点注记
让我们来看看下面的注释:
-
 是一个标量(与梯度不同,梯度是一个向量)
是一个标量(与梯度不同,梯度是一个向量) - 使用单个核(掩码)计算拉普拉斯函数(与梯度不同,梯度通常有两个核,x和y方向的偏导数)
- 作为标量,它没有任何方向,因此我们会丢失方向信息
-
 是二阶偏导数的和(梯度表示由一阶偏导数组成的向量),但较高的。。。
是二阶偏导数的和(梯度表示由一阶偏导数组成的向量),但较高的。。。
噪声对梯度计算的影响
用有限差分法计算的导数滤波器对噪声非常敏感。正如我们在上一章中看到的,图像中强度值与其相邻像素非常不同的像素通常是噪声像素。一般来说,噪声越大,强度变化越大,使用滤波器获得的响应越强。下一个代码块向图像添加一些高斯噪声,以查看对梯度的影响。让我们再次考虑图像的一行(精确地行 0),并让我们将强度绘制为{ To.T0} x OrthT1 位置:
from skimage.util import random_noise
sigma = 1 # sd of noise to be added
im = im + random_noise(im, var=sigma**2)
下图显示了在向象棋图像添加一些随机噪声后上一个代码块的输出。如我们所见,向输入图像添加随机噪声对(偏)导数和梯度幅度有很大影响;与边缘相对应的峰值与噪声几乎无法区分,并且图案被破坏:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LpgBYPcE-1681961321703)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/525c0130-ec59-49fe-a606-aed87d00a8a1.png)]

在应用导数滤波器之前对图像进行平滑应该是有帮助的,因为它会删除可能是噪声的高频分量,并强制(噪声)像素(与它们的邻居不同)看起来更像它们的邻居。因此,解决方案是首先使用 LPF(如高斯滤波器)平滑输入图像,然后在平滑图像中找到峰值(使用阈值)。这就产生了对数滤波器(如果我们使用二阶导数滤波器),我们将在本章后面探讨。
锐化和去锐化掩蔽
锐化的目的是突出显示图像中的细节或增强已模糊的细节。在本节中,我们将讨论一些技术,并通过一些示例演示几种不同的图像锐化方法。
拉普拉斯锐化
可以使用拉普拉斯滤波器通过以下两个步骤锐化图像:
- 将拉普拉斯滤波器应用于原始输入图像。
- 将步骤 1获得的输出图像与原始输入图像相加(以获得锐化图像)。下面的代码块演示了如何使用
scikit-image``filters模块的laplace()功能实现上述算法:
from skimage.filters import laplace
im = rgb2gray(imread('../images/me8.jpg'))
im1 = np.clip(laplace(im) + im, 0, 1)
pylab.figure(figsize=(20,30))
pylab.subplot(211), plot_image(im, 'original image')
pylab.subplot(212), plot_image(im1, 'sharpened image')
pylab.tight_layout()
pylab.show()
以下是先前代码块、原始图像和使用先前算法的锐化图像的输出:


反锐化掩蔽
反锐化遮罩是一种锐化图像的技术,从图像本身中减去模糊版本的图像。反锐化掩模使用的典型混合公式如下:锐化=原始+(原始)− 模糊)×金额。
这里,数量是一个参数。接下来的几节将演示如何使用 Python 中的 SciPy 函数的ndimage模块实现这一点。
使用 SciPy ndimage 模块
如前所述,我们可以首先模糊图像,然后计算细节图像作为原始图像和模糊图像之间的差值,以实现反锐化掩蔽。锐化后的图像可以作为原始图像和细节图像的线性组合来计算。下图再次说明了该概念:

下面的代码块显示了如何使用 SciPyndimage模块实现灰度图像的反锐化掩模操作(彩色图像也可以这样做,留给读者练习),使用上述概念:
def rgb2gray(im):
'''
the input image is an RGB image
with pixel values for each channel in [0,1]
'''
return np.clip(0.2989 * im[...,0] + 0.5870 * im[...,1] + 0.1140 * im[...,2], 0, 1)
im = rgb2gray(img_as_float(misc.imread('../images/me4.jpg')))
im_blurred = ndimage.gaussian_filter(im, 5)
im_detail = np.clip(im - im_blurred, 0, 1)
pylab.gray()
fig, axes = pylab.subplots(nrows=2, ncols=3, sharex=True, sharey=True, figsize=(15, 15))
axes = axes.ravel()
axes[0].set_title('Original image', size=15), axes[0].imshow(im)
axes[1].set_title('Blurred image, sigma=5', size=15), axes[1].imshow(im_blurred)
axes[2].set_title('Detail image', size=15), axes[2].imshow(im_detail)
alpha = [1, 5, 10]
for i in range(3):
im_sharp = np.clip(im + alpha[i]*im_detail, 0, 1)
axes[3+i].imshow(im_sharp), axes[3+i].set_title('Sharpened image, alpha=' + str(alpha[i]), size=15)
for ax in axes:
ax.axis('off')
fig.tight_layout()
pylab.show()
下面的屏幕截图显示了前面代码块的输出。可以看出,随着α值的增加,输出变得更尖锐:


使用导数和滤波器进行边缘检测(Sobel、Canny 等)
如前所述,构成图像中边缘的像素是图像强度函数中突然快速变化(不连续)的像素,边缘检测的目标是识别这些变化。因此,边缘检测是一种预处理技术,其中输入为 2D(灰度)图像,输出为一组曲线(称为边缘。在边缘检测过程中提取图像的显著特征;使用边缘的图像表示比使用像素的图像表示更紧凑。边缘检测器输出梯度的大小(作为灰度图像),现在,为了获得边缘像素(作为二值图像)。。。
使用偏导数计算梯度幅值
如前所述,使用偏导数的(正向)有限差分近似计算的梯度幅度(可以认为是边缘强度)可用于边缘检测。下面的屏幕截图显示了通过使用与上次相同的代码来计算梯度大小,然后使用斑马输入的灰度图像以[0,1]间隔剪裁像素值而获得的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YnBEbj1P-1681961321705)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/53d8dce4-c46f-4c1d-b34c-66f1265bd524.png)]
下面的屏幕截图显示了渐变幅度图像。如图所示,边缘看起来更厚且多像素宽:

为了获得每一个边缘都有一个像素宽的二值图像,我们需要应用非最大值抑制算法,如果像素不是像素邻域中沿梯度方向的局部最大值,则移除该像素。算法的实现留给读者作为练习。以下屏幕截图显示了带有非最大抑制的输出:

非最大值抑制算法
- 该算法首先检查边缘的角度(方向)(由边缘检测器输出)。
- 如果像素值在与其边缘角度相切的直线上不是最大值,则该像素值是要从边缘贴图中删除的候选像素。
- 这是通过将边缘方向(360)拆分为八个相等的间隔(角度为 22.50 度)来实现的。下表显示了不同的情况和要采取的措施:

- 我们可以通过观察π/8 范围并相应地设置一系列 if 条件的切向比较来实现这一点。
- 可以清楚地观察到边缘细化的效果(从上一张图像中)。。。
基于 scikit 图像的 Sobel 边缘检测器
与使用有限差分法相比,(一阶)导数可以更好地近似。下图中所示的 Sobel 运算符经常使用:

Sobel 算子的标准定义中不包括 1/8 项,因为出于边缘检测的目的,它不会产生差异,尽管需要标准化项才能正确获得梯度值。下一个 Python 代码片段展示了如何分别使用scikit-image的filters模块的sobel_h()、sobel_y()和sobel()函数来查找水平/垂直边缘,并使用 Sobel 运算符计算梯度大小:
im = rgb2gray(imread('../images/tajmahal.jpg')) # RGB image to gray scale
pylab.gray()
pylab.figure(figsize=(20,18))
pylab.subplot(2,2,1)
plot_image(im, 'original')
pylab.subplot(2,2,2)
edges_x = filters.sobel_h(im)
plot_image(edges_x, 'sobel_x')
pylab.subplot(2,2,3)
edges_y = filters.sobel_v(im)
plot_image(edges_y, 'sobel_y')
pylab.subplot(2,2,4)
edges = filters.sobel(im)
plot_image(edges, 'sobel')
pylab.subplots_adjust(wspace=0.1, hspace=0.1)
pylab.show()
下面的屏幕截图显示了前面代码块的输出。可以看出,图像的水平和垂直边缘由水平和垂直 Sobel 滤波器检测,而使用 Sobel 滤波器计算的梯度幅度图像在两个方向上检测边缘:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EPK1ViYR-1681961321707)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/aa566922-cef1-4b02-82e8-c5cdb67c0df2.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lab6ACBg-1681961321707)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/66695144-8480-4a32-8ae2-3cadb8107214.png)]
具有 scikit 图像的不同边缘检测器–Prewitt、Roberts、Sobel、Scharr 和 Laplace
图像处理算法中使用了很多不同的边缘检测算子;它们都是离散的(一阶或二阶)微分算子,它们试图逼近图像强度函数的梯度(例如,我们前面讨论过的 Sobel 算子)。下图所示的内核是用于边缘检测的几种常用内核。例如,常用的近似于一阶图像导数的导数滤波器是 Sobel、Prewitt、Sharr 和 Roberts 滤波器,而近似于二阶导数的导数滤波器是拉普拉斯滤波器:
如scikit-image文件中所述。。。
基于 scikit 图像的 Canny 边缘检测器
Canny 边缘检测器是一种流行的边缘检测算法,由 John F.Canny 开发。此算法具有以下多个步骤:
-
平滑/降噪:边缘检测操作对噪声敏感。因此,在一开始,使用 5 x 5 高斯滤波器从图像中去除噪声。
-
计算梯度的大小和方向:然后对图像应用 Sobel 水平和垂直滤波器,以计算每个像素的边缘梯度大小和方向,如前所述。然后将计算出的梯度角(方向)四舍五入为表示每个像素的水平、垂直和两个对角线方向的四个角之一。
-
非最大抑制:在这一步中,边缘被减薄–可能不构成边缘的任何不需要的像素被移除。要做到这一点,每个像素都要检查它是否是其邻域中梯度方向上的局部最大值。结果,获得具有薄边缘的二值图像。
-
链接和滞后阈值:此步骤决定检测到的所有边缘是否都是强边缘。为此,使用了一对(滞后)阈值
min_val和max_val。确定边缘是强度梯度值高于max_val的边缘。确保非边是强度梯度值低于min_val的边,它们将被丢弃。位于这两个阈值之间的边根据其连通性分类为边或非边。如果它们连接到“确定边缘”像素,则它们被视为边缘的一部分。否则,它们也会被丢弃。这一步还去除了小像素噪声(假设边缘是长线)。
最后,算法输出图像的强边缘。下面的代码块显示了如何使用scikit-image实现 Canny 边缘检测器:
im = rgb2gray(imread('../images/tiger3.jpg'))
im = ndimage.gaussian_filter(im, 4)
im += 0.05 * np.random.random(im.shape)
edges1 = feature.canny(im)
edges2 = feature.canny(im, sigma=3)
fig, (axes1, axes2, axes3) = pylab.subplots(nrows=1, ncols=3, figsize=(30, 12), sharex=True, sharey=True)
axes1.imshow(im, cmap=pylab.cm.gray), axes1.axis('off'), axes1.set_title('noisy image', fontsize=50)
axes2.imshow(edges1, cmap=pylab.cm.gray), axes2.axis('off')
axes2.set_title('Canny filter, $\sigma=1$', fontsize=50)
axes3.imshow(edges2, cmap=pylab.cm.gray), axes3.axis('off')
axes3.set_title('Canny filter, $\sigma=3$', fontsize=50)
fig.tight_layout()
pylab.show()
下面的屏幕截图显示了前面代码的输出;对于初始高斯 LPF,使用具有不同 sigma 值的 Canny 滤波器检测边缘。如图所示,sigma 值越低,原始图像越不模糊,因此可以找到更多的边缘(更精细的细节):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-79zKxsxM-1681961321707)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/3af8a217-a041-4e2a-ac30-7d3812b0928b.png)]
原木和狗过滤器
高斯(LoG)的拉普拉斯滤波器只是另一个线性滤波器,它是高斯滤波器和拉普拉斯滤波器在图像上的组合。由于 2nd导数对噪声非常敏感,因此在应用拉普拉斯算子之前通过平滑图像来消除噪声始终是一个好主意,以确保噪声不会加剧。由于卷积的关联性,可以将其视为采用高斯滤波器的 2nd导数(拉普拉斯),然后将得到的(组合)滤波器应用于图像,因此称为 LoG。可以使用两个具有不同标度(方差)的高斯(DoG)差有效地近似,如下图所示:
下面的代码块。。。
带有 SciPy ndimage 模块的日志过滤器
SciPyndimage模块的gaussian_laplace()功能也可以用来实现日志,如下代码块所示:
img = rgb2gray(imread('../images/zebras.jpg'))
fig = pylab.figure(figsize=(25,15))
pylab.gray() # show the filtered result in grayscale
for sigma in range(1,10):
pylab.subplot(3,3,sigma)
img_log = ndimage.gaussian_laplace(img, sigma=sigma)
pylab.imshow(np.clip(img_log,0,1)), pylab.axis('off')
pylab.title('LoG with sigma=' + str(sigma), size=20)
pylab.show()
以下图像显示了使用具有不同平滑参数σ(高斯滤波器的标准偏差)值的对数滤波器获得的输入图像和输出图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ln95WKK2-1681961321708)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/9678f9a3-1be5-40aa-a41a-2e054cea3bdd.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bMB0ckFw-1681961321708)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/6d264f80-f8be-4739-8dca-3676c89a1d41.png)]
基于对数滤波器的边缘检测
下面介绍使用LOG滤波器进行边缘检测的步骤:
-
首先,输入图像需要平滑(通过与高斯滤波器卷积)。
-
然后,平滑后的图像需要用拉普拉斯滤波器进行卷积,得到输出图像为*∇ 2(I(x,y)G(x,y))。
-
最后,需要计算在最后一步中获得的图像的过零点,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wrw6voa3-1681961321708)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/53da382b-67a9-4633-abdf-8c8acc326b2e.png)]
基于过零计算的 Marr 和 Hildreth 边缘检测算法
Marr 和 Hildreth 提出了计算对数卷积图像中的过零点(将边缘检测为二值图像)。通过将对数平滑的图像定义为二值图像来查看其符号,可以识别边缘像素。计算过零的算法如下:
- 首先,将对数卷积图像转换为二值图像,将像素值替换为
1表示正值,将0表示负值 - 为了计算过零像素,我们只需查看此二值图像中非零区域的边界
- 边界可以通过查找任何非零像素来找到,该像素的近邻为零
- 因此,对于每个像素,如果它是非零的,考虑它的八个邻居;如果任何相邻像素为零,则该像素可被识别为边缘
此功能的实现留作练习。以下代码块描述了通过零交叉检测到的同一斑马图像的边缘:
fig = pylab.figure(figsize=(25,15))
pylab.gray() # show the filtered result in grayscale
for sigma in range(2,10, 2):
pylab.subplot(2,2,sigma/2)
result = ndimage.gaussian_laplace(img, sigma=sigma)
pylab.imshow(zero_crossing(result)) # implement the function zero_crossing() using the above algorithm
pylab.axis('off')
pylab.title('LoG with zero-crossing, sigma=' + str(sigma), size=20)
pylab.show()
下面的屏幕截图显示了前面代码块的输出,在不同的σ标度下,边缘仅通过零交叉来识别:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UJM2BJOB-1681961321708)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/ef188972-07db-4c6b-8bc5-151df730a9a3.png)]
前面的图像显示了以 LoG/DoG 作为边缘检测器的零交叉。需要注意的是,过零点形成闭合轮廓。
用 PIL 查找和增强边缘
PIL 的ImageFilter模块的filter功能也可用于查找和增强图像中的边缘。以下代码块显示了以UMBC library图像作为输入的示例:
from PIL.ImageFilter import (FIND_EDGES, EDGE_ENHANCE, EDGE_ENHANCE_MORE)im = Image.open('../images/umbc_lib.jpg')pylab.figure(figsize=(18,25))pylab.subplot(2,2,1)plot_image(im, 'original (UMBC library)')i = 2for f in (FIND_EDGES, EDGE_ENHANCE, EDGE_ENHANCE_MORE): pylab.subplot(2,2,i) im1 = im.filter(f) plot_image(im1, str(f)) i += 1pylab.show()
以下屏幕截图显示了使用不同边缘查找/增强过滤器的上述代码的输出:
图像金字塔(高斯和拉普拉斯)-混合图像
我们可以从原始图像开始,迭代创建更小的图像,首先通过平滑(使用高斯滤波器避免抗锯齿,然后通过子采样(统称为减少)来构建图像的高斯金字塔在每次迭代中从上一级别的图像开始,直到达到最小分辨率。以这种方式创建的图像金字塔称为高斯金字塔。通过单独编辑频带(例如,图像混合),这些功能适用于搜索超范围(例如,模板匹配)、预计算和图像处理任务。类似地,图像的拉普拉斯金字塔可以通过从高斯金字塔中最小尺寸的图像开始,然后通过扩展(上采样加平滑)该级别的图像并从高斯金字塔的下一级别的图像中减去该图像来构建,重复这个过程,直到达到原始图像大小。在本节中,我们将看到如何编写 python 代码来计算图像金字塔,然后查看用于混合两个图像的图像金字塔的应用程序。
带有 scikit 图像变换金字塔模块的高斯金字塔
可以使用scikit-image.transform.pyramid模块的pyramid_gaussian()函数计算输入图像的高斯金字塔。从原始图像开始,该函数调用pyramid_reduce()函数,以递归方式获得平滑和向下采样的图像。下面的代码块演示了如何使用lenaRGB 输入图像计算和显示这样的高斯金字塔:
from skimage.transform import pyramid_gaussianimage = imread('../images/lena.jpg')nrows, ncols = image.shape[:2]pyramid = tuple(pyramid_gaussian(image, downscale=2))pylab.figure(figsize=(20,5))i, n = 1, len(pyramid)for p in pyramid: pylab.subplot(1,n,i), pylab.imshow(p) pylab.title(str(p.shape[0]) ...
具有 scikit 图像变换金字塔模块的拉普拉斯金字塔
可以使用scikit-image.transform.pyramid模块的pyramid_laplacian()函数计算输入图像的拉普拉斯金字塔。该函数从原始图像及其平滑版本的差分图像开始,计算下采样图像和平滑图像,并取这两个图像的差分递归计算对应于每个层的图像。创建拉普拉斯金字塔的动机是实现压缩,因为对于 0 左右的可预测值,压缩率更高。
用于计算拉普拉斯金字塔的代码类似于先前用于计算高斯金字塔的代码;这是留给读者的练习。以下屏幕截图显示了lena灰度图像的拉普拉斯金字塔:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wh95djqz-1681961321709)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/9705405c-7945-4f35-8f12-b9cb90f58918.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eYNYbw7B-1681961321709)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/378a89ab-5e44-45a2-8af0-b49cc8275fb3.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wd0oThH8-1681961321709)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/36cef8b9-2d6b-4479-9991-f668849d575e.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zLrseRoL-1681961321709)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/1b524b56-6cc3-494b-b36f-2a755895c1be.png)]
请注意,如果我们使用scikit-image的pyramid_gaussian()和pyramid_laplacian()函数,拉普拉斯金字塔中的最低分辨率图像和高斯金字塔中的最低分辨率图像将是不同的图像,这是我们不想要的。我们想要建立一个拉普拉斯金字塔,其中最小分辨率的图像与高斯金字塔的图像完全相同,因为这将使我们能够仅从其拉普拉斯金字塔构建图像。在接下来的几节中,我们将讨论使用scikit-image的expand()和reduce()函数构建我们自己的金字塔的算法。
构造高斯金字塔
可通过以下步骤计算高斯金字塔:
- 从原始图像开始。
- 在金字塔的每一层迭代计算图像,首先通过平滑图像(使用高斯滤波器),然后对其进行下采样。
- 在图像大小足够小的级别停止(例如,1 x 1)。
- 实现前面算法的函数留给读者作为练习;我们只需在以下函数中添加几行即可完成实现:
from skimage.transform import pyramid_reduce def get_gaussian_pyramid(image): ''' input: an RGB image output: the Gaussian Pyramid of the image as a list ''' gaussian_pyramid = [] # add code here # iteratively ...
仅从拉普拉斯金字塔重建图像
下图显示了如何仅从其拉普拉斯金字塔重建图像,如果我们按照上一节中描述的算法构造图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FqgHwFAI-1681961321709)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/fcd408ae-d122-4097-bfda-10af051d17b5.png)]
请查看以下代码块:
def reconstruct_image_from_laplacian_pyramid(pyramid):
i = len(pyramid) - 2
prev = pyramid[i+1]
pylab.figure(figsize=(20,20))
j = 1
while i >= 0:
prev = resize(pyramid_expand(prev, upscale=2), pyramid[i].shape)
im = np.clip(pyramid[i] + prev,0,1)
pylab.subplot(3,3,j), pylab.imshow(im)
pylab.title('Level=' + str(j) + ' ' + str(im.shape[0]) + 'x' + str(im.shape[1]), size=20)
prev = im
i -= 1
j += 1
pylab.subplot(3,3,j), pylab.imshow(image)
pylab.title('Original image' + ' ' + str(image.shape[0]) + 'x' + str(image.shape[1]), size=20)
pylab.show()
return im
image = img_as_float(imread('../images/apple.png')[...,:3]) # only use the color channels and discard the alpha
pyramid = get_laplacian_pyramid(get_gaussian_pyramid(image))
im = reconstruct_image_from_laplacian_pyramid(pyramid)
下面的屏幕截图显示了前面代码的输出,即原始图像是如何通过拉普拉斯金字塔(Laplacian pyramid)最终构建的,只需对每个级别的图像使用expand()操作,并将其迭代添加到下一级别的图像中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RoVFQdkM-1681961321710)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/e7fba4b7-b58b-4064-84e8-848b282ea6d7.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FbSGT9sa-1681961321710)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/3a67b791-f7f1-45ba-bcff-1ed6be25bb2f.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7lgQe7m4-1681961321710)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/handson-imgproc-py/img/572a509d-7fc7-4736-ac73-c9be41783105.png)]
将图像与金字塔混合
假设我们有两个 RGB 彩色输入图像,a(苹果)和B(橙色),以及第三个二值掩模图像,M;这三幅图像的大小都相同。目标是在遮罩M的引导下,将图像A与B混合(如果遮罩图像 M 中的像素值为 1,则表示该像素取自图像A,否则取自图像B。以下算法可用于使用图像A和B的拉普拉斯金字塔混合两幅图像(通过使用来自A和B的拉普拉斯金字塔相同级别的图像的线性组合计算混合金字塔),使用掩模图像M的高斯金字塔的同一层级的权重),然后从中重建输出图像。。。
总结
在本章中,我们首先讨论了使用几种滤波器(Sobel、Prewitt、Canny 等)以及通过计算图像的梯度和拉普拉斯算子对图像进行边缘检测。然后,我们讨论了 LoG/DoG 算子,以及如何实现它们,以及如何利用零交叉检测边缘。接下来,我们讨论了如何计算图像金字塔,并使用拉普拉斯金字塔平滑地混合两幅图像。最后,我们讨论了如何使用scikit-image检测斑点。完成本章后,读者应该能够使用不同的过滤器在图像中使用 Python 实现边缘检测器(Sobel、Canny 等)。此外,读者应该能够实现过滤器来锐化图像,并使用 LoG/DoG 查找不同比例的边缘。最后,他们应该能够将图像与拉普拉斯/高斯金字塔混合,并在不同尺度空间的图像中实现斑点检测。在下一章中,我们将讨论图像的特征检测和提取技术。
问题
-
使用
skimage.filters模块的unsharp_mask()功能和radius和amount参数的不同值来锐化图像。 -
使用 PIL
ImageFilter模块的UnsharpMask()功能以及radius和percent参数的不同值来锐化图像。 -
使用锐化内核[[0,-1,0]、-1,5,-1]、[0,-1,0]]锐化彩色(RGB)图像。(提示:对每个颜色通道逐一使用 SciPy
signal模块的convolve2d()功能。) -
使用 SciPy
ndimage模块,可直接锐化彩色图像(无需逐个锐化单个颜色通道)。 -
使用
skimage.transform模块的pyramid_laplacian()函数计算并显示带有lena灰度输入图像的高斯金字塔。 -
建筑
进一步阅读
-
https://web.stanford.edu/class/cs448f/lectures/5.2/Gradient%20Domain.pdf
-
https://web.stanford.edu/class/ee368/Handouts/Lectures/2014_Spring/Combined_Slides/11-Edge-Detection-Combined.pdf
-
https://www.cs.cornell.edu/courses/cs6670/2011sp/lectures/lec02_filter.pdf
-
http://www.cs.toronto.edu/~mangas/teaching/320/slides/CSC320L05.pdf
-
http://www.cse.psu.edu/~rtc12/CSE486/讲师 11.pdf
-
http://graphics.cs.cmu.edu/courses/15-463/2005_fall/www/Lectures/Pyramids.pdf
-
http://www.eng.tau.ac.il/~ipapps/Slides/讲师 05.pdf
-
https://sandipanweb.wordpress.com/2017/05/16/some-more-computational-photography-merging-and-blending-images-using-gaussian-and-laplacian-pyramids-in-python/
-
http://www.me.umn.edu/courses/me5286/vision/VisionNotes/2017/ME5286-Lecture7-2017-EdgeDetection2.pdf
-
https://www.cs.rutgers.edu/~elgammal/classes/cs334/EdgesandContours.pdf
-
https://web.fe.up.pt/~campilho/PDI/NOTES/EdgeDetection.pdf
-
http://www.cs.cornell.edu/courses/cs664/2008sp/handouts/edges.pdf
-
http://www.cs.cmu.edu/~16385/s17/Slides/4.0_Image_Gradients_ 和 _Gradients_Filtering.pdf
-
http://www.hms.harvard.edu/bss/neuro/bornlab/qmbc/beta/day4/marr-hildreth-edge-prsl1980.pdf
-
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.420.3300 &rep=rep1&type=pdf
-
http://persci.mit.edu/pub_pdfs/pyramid83.pdf
-
http://persci.mit.edu/pub_pdfs/spline83.pdf
-
http://ftp.nada.kth.se/CVAP/reports/cvap198.pdf
-
https://www.cs.toronto.edu/~mangas/teaching/320/assignments/a3/tcomm83.pdf
-
https://www.cs.toronto.edu/~mangas/teaching/320/assignments/a3/spline83.pdf
-
http://6.869.csail.mit.edu/fa16/lecture/lecture6.pdf文章来源:https://www.toymoban.com/news/detail-690548.html
-
https://docs.opencv.org/3.1.0/dc/dff/tutorial_py_pyramids.html文章来源地址https://www.toymoban.com/news/detail-690548.html
到了这里,关于Python 图像处理实用指南:1~5的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!