OCR多语言识别模型构建
构建多语言识别模型方案
合合,百度,腾讯,阿里这四家的不错
调研多家,发现有两种方案,但是大多数厂商都是将多语言放在一个字典里,构建1w~2W的字典,训练一个可识别多种语言的模型;
合合通用多语言:
https://www.textin.com/experience/text_recognize_3d1
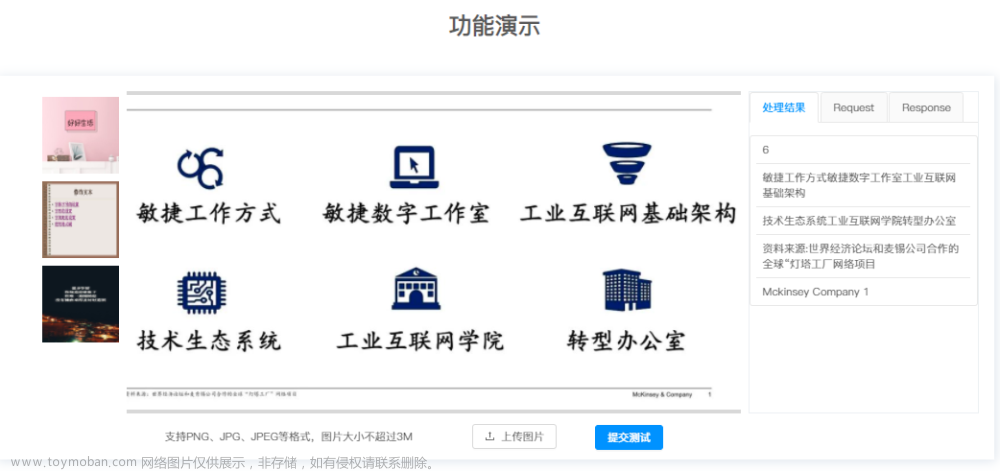
 百度的通用模型:
百度的通用模型:
https://ai.baidu.com/tech/ocr/general?p=%E5%8A%9F%E8%83%BD%E6%BC%94%E7%A4%BA&from=experience
版式相关文章来源:https://www.toymoban.com/news/detail-690698.html
https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout文章来源地址https://www.toymoban.com/news/detail-690698.html
到了这里,关于OCR多语言识别模型构建资料收集的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[C#]调用tesseact-ocr的traineddata模型进行ocr文字识别](https://imgs.yssmx.com/Uploads/2024/02/783178-1.jpeg)