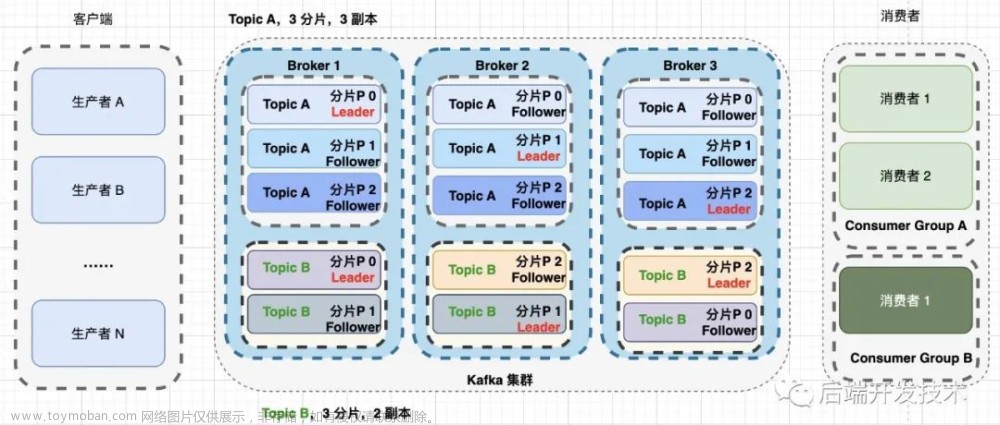
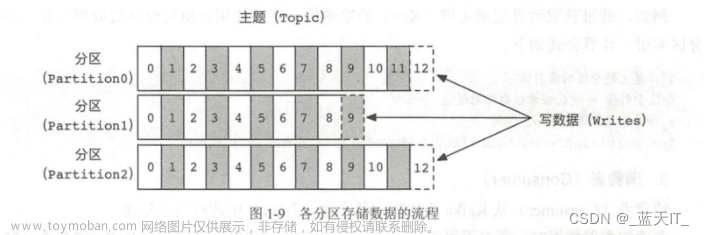
昨日内容回顾:
- ES的加密及客户端的连接方式,比如logstash,filebeat,curl,es-head,postman...
- zk单点部署
- kafka单点部署
- kafka的集群扩容
- kafka集群架构
- kafka的堆内存调优
- kafka的集群宏观架构
Q1: 为什么需要配置"dvertised.listeners".
因为没有配置主机名解析导致的问题。
Q2: 一个分区数写入数据是有序的,但为什么多个分区数写入就是无序的呢?
因为消费者是从多个分区读取的,顺序无法确定。
Q3: leader同步follower是如何同步的?
follower主动去leader拉取数据。
Q4: leader挂掉之后发生了哪些事,请说明?
leader挂掉后,follower会成为新的leader,需要借助zookeeper实现。
Q5: follower挂掉之后如何解决,会发生哪些问题?
leader会根据replica.lag.time.max.ms定义的间隔时间,超出该范围leader就会将其剔除ISR列表。
Q6: 当follower数据和leader不同时,又会发生啥事?
leader会根据replica.lag.time.max.ms定义的间隔时间,超出该范围leader就会将其剔除ISR列表。
Q7: 当消费者数据延迟时如何解决问题?请说明原因。
将多个消费者加入到同一个消费者组进行消费,但是要注意消费者数量不能大于分区数数量。
Q8: 请问多副本,例如一个分区3个副本,kafka会存在数据丢失的风险吗?请说明原因。
会,还是ISR的存在。
相关术语:
Log End Offset (简称"LEO"):
每个partition的最后一个日志的偏移量。
High Water(简称"HW"):
所有ISR列表中最小的LEO。
所有的消费者只能读取到HW之前的偏移量数据。
ISR:
和leader数据同步的所有副本集合。
OSR:
和leader数据不同的所有副本集合。
AR:
是ISR+OSR,指的是所有副本集合。
replica.lag.time.max.ms: 30000ms ---> 30s
当follower节点超过30秒没有向leader发送fetch请求或者follower的LEO不等于leader的LEO时,leader会将follower踢出ISR列表。
zookeeper的基础操作:
1.简介
zookeeper是一个分布式协调服务,其扮演的是辅助的功能。本身并不支持存储大量数据,每个znode默认可以存储大约2M的数据。
2.什么是znode
所谓的znode指的是zookeeper node,相当于Linux的目录,只不过znode下不仅仅可以存储子znode,其本身也能够存数据。
3.znode的基础管理
登录:
# zkCli.sh
增:
create /test
创建一个"/test"的znode。
create /test/b
支持多级路径创建,但要求父路径是必须存在的。
删:
delete /test/a
删除"/test/a"的znode,要求znode为空。
deleteall /test
删除"/test"的所有内容,可以删除非空znode。
改:
set /test/c/1111 bbbbbbbbbb
修改"/test/c/1111"的znode存储数据。
查: *****
ls /
查看/的znode下有哪些子znode。
ls /test -R
递归查看"/test"子路径下的所有znode。
get /test
查看数据。
kafka 0.8.0 多实例部署:
1.解压软包包
tar xf kafka_2.8.0-0.8.0.tar.gz -C /oldboyedu/softwares/
2.修改配置文件
vim /oldboyedu/softwares/kafka_2.8.0-0.8.0/config/server.properties
...
broker.id=101
# kafka的监听端口
port=19092
log.dirs=/oldboyedu/data/kafka080
zookeeper.connect=10.0.0.101:2181/oldboyedu-linux82-kafka080
3.101节点同步数据
data_rsync.sh /oldboyedu/softwares/kafka_2.8.0-0.8.0/
4.102节点修改broker.id
vim /oldboyedu/softwares/kafka_2.8.0-0.8.0/config/server.properties
...
broker.id=102
5.103节点修改broker.id
vim /oldboyedu/softwares/kafka_2.8.0-0.8.0/config/server.properties
...
broker.id=102
6.zookeeper创建znode
create /oldboyedu-linux82-kafka080
7.启动kafka
cd /oldboyedu/softwares/kafka_2.8.0-0.8.0 && ./bin/kafka-server-start.sh config/server.properties &>/dev/null &
8.检查zookeeper集群的ids信息
ls /oldboyedu-linux82-kafka080/brokers/ids
早期kafka 0.9之前的offset存储在zookeeper:
1.查看topic信息
./bin/kafka-list-topic.sh --zookeeper 10.0.0.101:2181/oldboyedu-linux82-kafka080
2.启动生产者
./bin/kafka-console-producer.sh --broker-list 10.0.0.101:19092,10.0.0.102:19092,10.0.0.103:19092 --topic oldboyedu-linux82
3.启动消费者
./bin/kafka-console-consumer.sh --zookeeper 10.0.0.101:2181/oldboyedu-linux82-kafka080 --topic oldboyedu-linux82
4.查看偏移量,注意"console-consumer-78441"根据您的环境适当改变即可
get /oldboyedu-linux82-kafka080/consumers/console-consumer-78441/offsets/oldboyedu-linux82/0
从kafka 0.9之后的版本之后支持将offset存储在kafka的"__consumer_offsets"内置topic中:
1.查看kafka内置"__consumer_offsets"的方式
kafka-console-consumer.sh --bootstrap-server 10.0.0.101:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning | grep oldboyedu-linux82
....
# [消费者组,消费的topic,分区数]::OffsetAndMetadata(偏移量,...)
[linux82-elk,oldboyedu-linux82,4]::OffsetAndMetadata(offset=5, leaderEpoch=Optional[0], metadata=, commitTimestamp=1661498621467, expireTimestamp=None)
[linux82-elk,oldboyedu-linux82,1]::OffsetAndMetadata(offset=4, leaderEpoch=Optional[0], metadata=, commitTimestamp=1661498621467, expireTimestamp=None)
[linux82-elk,oldboyedu-linux82,2]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[0], metadata=, commitTimestamp=1661498621467, expireTimestamp=None)
[linux82-elk,oldboyedu-linux82,0]::OffsetAndMetadata(offset=4, leaderEpoch=Optional[0], metadata=, commitTimestamp=1661498621467, expireTimestamp=None)
[linux82-elk,oldboyedu-linux82,3]::OffsetAndMetadata(offset=3, leaderEpoch=Optional[0], metadata=, commitTimestamp=1661498621467, expireTimestamp=None)
2.查看消费者组信息,注意观察"linux82-elk"的消费者组是否有消息延迟!
kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --all-groups
kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --group linux82-elk
...
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
linux82-elk oldboyedu-linux82 4 5 6 1 - - -
linux82-elk oldboyedu-linux82 1 4 4 0 - - -
linux82-elk oldboyedu-linux82 2 3 4 1 - - -
linux82-elk oldboyedu-linux82 0 4 5 1 - - -
linux82-elk oldboyedu-linux82 3 3 5 2 - - -
3.修改配置文件
vim /oldboyedu/softwares/kafka_2.13-3.2.1/config/consumer.properties
...
group.id=linux82-elk
4.基于配置文件启动消费者
kafka-console-consumer.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic oldboyedu-linux82 --from-beginning --consumer.config /oldboyedu/softwares/kafka_2.13-3.2.1/config/consumer.properties
5.再次查看消费者信息
kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --group linux82-elk
kafka生产环境应该监控哪些指标:
(1)监控kafka的程序是否正常运行;
(2)数据是否有延迟;
(3)是否频繁涉及到ISR列表的变化;
(4)iops;
(5)其他参数可参考<<kafka权威指南>>;
安装开源工具监控kafka集群:
1.安装MySQL数据库并授权
1.1 部署mariadb
yum -y install mariadb-server
systemctl start mariadb
1.2 修改配置文件
vim /etc/my.cnf
...
[mysqld]
# 跳过名称解析。
skip-name-resolve
1.3 重启服务并测试链接
systemctl restart mariadb
mysql -u linux82 -poldboyedu -h 10.0.0.103
1.4 创建数据库
CREATE DATABASE oldboyedu_linux82 DEFAULT CHARACTER SET utf8mb4;
1.5 授权
CREATE USER linux82 IDENTIFIED BY 'oldboyedu';
GRANT ALL ON oldboyedu_linux82.* TO linux82;
SHOW GRANTS FOR linux82;
2.修改kafka开启JMX
2.1 修改启动脚本
vim /oldboyedu/softwares/kafka_2.13-3.2.1/bin/kafka-server-start.sh
...
# 大概在30行左右
export KAFKA_HEAP_OPTS="-Xmx256m -Xms256m"
export JMX_PORT="8888"
2.2 同步启动脚本到其他节点
data_rsync.sh /oldboyedu/softwares/kafka_2.13-3.2.1/bin/kafka-server-start.sh
2.3 所有重启kafka服务
kafka-server-stop.sh
kafka-server-start.sh $KAFKA_HOME/config/server.properties &>/dev/null &
3.启动zookeeper的JMX端口
3.1 修改启动脚本
vim /oldboyedu/softwares/apache-zookeeper-3.8.0-bin/bin/zkServer.sh +77
...
# 大概是在77行左右
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
3.2 重启zookeeper服务
zkServer.sh restart
4.安装kafka eagle监控工具
4.1 解压软件包
unzip kafka-eagle-bin-2.0.8.zip
tar xf efak-web-2.0.8-bin.tar.gz -C /oldboyedu/softwares/
4.2 修改kafka eagle启动脚本的堆内存大小
vim /oldboyedu/softwares/efak-web-2.0.8/bin/ke.sh
...
export KE_JAVA_OPTS="-server -Xmx256m -Xms256m -XX:MaxGCPauseMillis=20 -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
4.3 修改配置文件
cat > /oldboyedu/softwares/efak-web-2.0.8/conf/system-config.properties <<EOF
efak.zk.cluster.alias=linux82,cluster2
linux82.zk.list=10.0.0.101:2181/oldboyedu-linux82-kafka3.2.1
cluster2.zk.list=10.0.0.101:2181/oldboyedu-linux82-kafka080
linux82.efak.broker.size=20
kafka.zk.limit.size=32
efak.webui.port=8048
linux82.efak.offset.storage=kafka
cluster2.efak.offset.storage=zk
linux82.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
efak.metrics.charts=true
efak.metrics.retain=15
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
efak.topic.token=keadmin
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://10.0.0.103:3306/oldboyedu_linux82?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=linux82
efak.password=oldboyedu
EOF
4.4 配置环境变量
cat > /etc/profile.d/kafka_eagle.sh <<EOF
#!/bin/bash
export KE_HOME=/oldboyedu/softwares/efak-web-2.0.8
export PATH=$PATH:$KE_HOME/bin
EOF
4.5 启动kafka eagle服务,第一次需要等一会,可能有点漫长哈!大概30s~1分钟左右
ke.sh start
kafka集群压力测试:
1.简介
所谓压力测试就是对一个集群的处理能力的上限做一个评估。为将来集群扩容提供有效的依据。
2.为什么要进行压力测试
(1)压力测试可以了解当前集群的处理能力上限;
(2)当修改集群的配置参数后,压力测试可以协助运维人员去参考本次调优的效果;
(3)压力测试的结果以后可以作为参考扩容集群的有效依据;
3.实战案例
install -d /tmp/kafka-test/
cat > oldboyedu-kafka-test.sh <<'EOF'
# 创建topic
kafka-topics.sh --bootstrap-server 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic oldboyedu-kafka-2022 --replication-factor 1 --partitions 10 --create
# 启动消费者消费数据
nohup kafka-consumer-perf-test.sh --broker-list 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic oldboyedu-kafka-2022 --messages 100000000 &>/tmp/kafka-test/oldboyedu-kafka-consumer.log &
# 启动生产者写入数据
nohup kafka-producer-perf-test.sh --num-records 100000000 --record-size 1000 --topic oldboyedu-kafka-2022 --throughput 1000000 --producer-props bootstrap.servers=10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 &> /tmp/kafka-test/oldboyedu-kafka-producer.log &
EOF
bash oldboyedu-kafka-test.sh
参数说明:
kafka-consumer-perf-test.sh
---messages:
指定消费消息的数量。
--broker-list:
指定broker列表。
--topic:
指定topic主体。
kafka-producer-perf-test.sh
-num-records
生产消息的数量。
--record-size:
每条消息的大小,单位是字节。
--topic:
指定topic主体。
--throughput
设置每秒发送的消息数量,即指定最大消息的吞吐量,若设置为-1代表不限制!
--producer-props bootstrap.servers
指定broker列表。
温馨提示:
本案例测试大约会生成93GB( echo "100000000 * 1000/1024/1024/1024" | bc)的数据,如果硬盘资源不足的小伙伴可以暂时不用测试了,或者该小上面提到的参数。
今日内容回顾:
- kafka的ISR工作机制原理 *****
- ZK的znode基础操作 ***
- kafka多实例部署
- kafka eagle监控工具
- kafka集群压力测试 ***文章来源:https://www.toymoban.com/news/detail-691046.html
下次课程:
- kafka优化
- kafka配合elk使用案例
- zk的ACL
- zk的监控工具
- zk调优
- ES8集群环境搭建文章来源地址https://www.toymoban.com/news/detail-691046.html
到了这里,关于kafka的ISR工作机制原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!