HTTP 协议定义
HTTP协议,直译为超文本传输协议,是一种用于分布式、协作、超媒体的信息系统的应用协议。HTTP协议是万维网数据通信的基础。HTTP协议在客户端-服务器计算模型中充当请求-响应协议。客户端向服务器提交HTTP请求消息。服务器提供HTML文件和其他内容等资源,或代表客户端执行其他功能,并向客户端返回响应消息。
下面是维基百科对HTTP协议的定义:
The Hypertext Transfer Protocol(HTTP) is an application protocol for distributed, collaborative, hypermedia
information systems. HTTP is the foundation of data communication for the World Wide Web, where hypertext
documents include hyperlinks to other resources that the user can easily access, for example by a mouse click
or by tapping the screen in a web browser.
此外,还有medium网站rcrohitcse提供的HTTP协议的定义:
HTTP functions as a request–response protocol in the client–server computing model. A web browser, for example,
may be the client and an application running on a computer hosting a website may be the server.
The client submits an HTTP request message to the server. The server, which provides resources such as HTML
files and other content, or performs other functions on behalf of the client, returns a response message to
the client. The response contains completion status information about the request and may also contain requested
content in its message body.
HTTP 协议标准可以参考官网。HTTP协议的主要特点可概括如下:
(1) 支持客户/服务器模式(现在更多的应用在浏览器-服务器模式中)。
(2) 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
(3) 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
(4) 无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
(5) 无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。(使用Cookie和Sesseion记录数据)
超媒体简介
超媒体是由Fred Nelson在1965年定义。超媒体是对超文本的扩展,即通过点击网络浏览器上的文本链接打开新网页的能力。超媒体通过允许用户点击图像、电影、图形和除文本之外的其他媒体来创建非线性信息网络,从而对此进行了扩展。原文定义如下:
Hypermedia is an extension to what is known as hypertext, or the ability to open new Web pages by clicking text links
on a Web browser. Hypermedia extends upon this by allowing the user to click images, movies, graphics and other media
apart from text to create a nonlinear network of information. The term was coined by Fred Nelson in 1965.
用一句话来概述,Hypermedia(超媒体) = 超文本 + 多媒体。
超文本
超文本是用超链接的方法,将各种不同空间的文字信息组织在一起的网状文本。超文本是一种用户界面范式,用以显示文本及与文本之间相关的内容。超文本普遍以电子文档方式存在,其中的文字包含有可以链接到其他位置或者文档的连结,允许从当前阅读位置直接切换到超文本连结所指向的位置。超文本的格式有很多,目前最常使用的是超文本标记语言(标准通用标记语言下的一个应用)及富文本格式。
多媒体
多媒体是多种媒体的综合,一般包括文本,声音和图像等多种媒体形式。在计算机系统中,多媒体指组合两种或两种以上媒体的一种人机交互式信息交流和传播媒体。使用的媒体包括文字、图片、照片、声音 、动画和影片,以及程序所提供的互动功能。
HTTP 工作原理简介
HTTP 协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。请求/响应模型示例如下:

HTTP 请求/响应一般可分为六步:(1) 建立TCP连接;(2) 发送HTTP请求;(3) 服务器处理请求;(4) 返回HTTP响应;(5) 释放TCP连接;(6) 浏览器解析返回的资源和数据。更详细的介绍可以参考笔者浏览器输入URL后的执行过程一文。
(1) 建立TCP连接
一个HTTP客户端,通常是浏览器,主动与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。TCP连接建立的过程也被称为“三次握手”。
(2) 发送HTTP请求
通过TCP三次握手建立好连接后,浏览器便可以将HTTP请求报文发送给服务器。一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
(3) 服务器处理请求
Web服务器解析请求,定位请求资源。再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过Web服务器返回给浏览器。
(4) 返回HTTP响应
Web服务器将资源复本写到TCP套接字,由客户端读取。一个响应报文由响应行、响应头部、空行和响应数据4部分组成。
(5) 释放TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求。TCP连接的释放也被称为“四次挥手”。
(6) 浏览器解析返回的资源和数据
浏览器首先解析状态行,查看请求是否成功的状态码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。浏览器读取响应数据html,根据html的语法对其进行格式化,并在浏览器窗口中显示。
HTTP URL
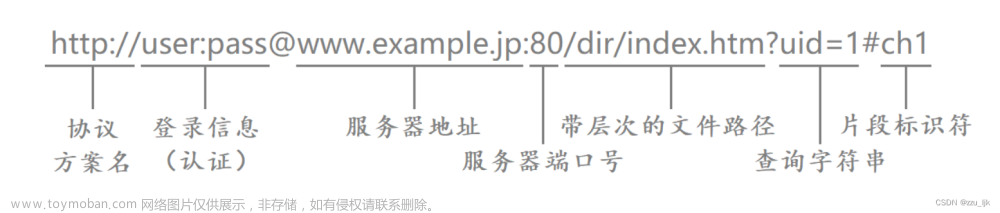
URL全称是Uniform Resource Locator,中文叫统一资源定位符,用来唯一标识某一处资源在Internet的位置,从而实现Internet上资源的定位。接下来以下面的URL(faked url)为例,介绍下URL的各部分组成:
http://user:password@www.github.com:8080/news/index.html?boardID=5&ID=24618&page=1#uniformresourcelocator
一个完整的URL包括以下几部分:
(1) 协议:必填,指定使用的传输协议,如HTTP、HTTPS、FTP等。显然,示例URL使用的传输协议是HTTP协议。此外,协议后面的“//”为分隔符。
(2) 登录信息: 可选,用户名和密码作为从服务器端获取资源时必要的登录信息(身份认证)。注意,这种写法已弃用,用户名和密码信息一般都通过token验证。
(3) 服务器地址:必填,可以是域名,如“www.github.com”,也可以是IP,如127.0.0.1(local host)。
(4) 端口:可选,指定待连接服务器的网络端口,若省略则使用该协议的默认端口(如http协议的默认端口是80,https协议的默认端口是443, ftp协议的默认端口是21)。服务器地址和和端口之间使用“:”作为分隔符。
(5) 文件路径:可选,指定服务器上的路径来定位指定资源。文件路径可细分为两部分:虚拟目录部分和文件名部分。其中虚拟目录部分是指从域名后的第一个“/”开始到最后一个“/”的部分。本例中的虚拟目录是“/news/”。文件名部分是指从域名后的最后一个“/”开始到“?”的部分;如果没有“?”, 则是从域名后的最后一个“/”开始到“#”的部分;如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.html”。
(6) 参数: 可选,从“?”到“#”之间的部分为参数部分,用于给动态网页(如使用CGI、ISAPI、PHP/JSP/ASP/ASP.NET等技术制作的网页)传递参数。多个参数使用“&”符号隔开,每个参数的名和值用“=”符号隔开。本例中的参数部分为“boardID=5&ID=24618&page=1”。
(7) 片段:可选,“#”之后的部分都是片段。片段用于指定网络资源中的片段。html页面中片段则是锚点(Anchor)。本例中的锚点是“uniformresourcelocator”。
URI、URL 和 URN 的区别
在介绍URI、URL 和 URN的区别前,先对URI和URN进行一个简单的介绍。
(1) URI
URI 全称是 Universal Resource Identifier,中文翻译是统一资源标识符。URI 是一个用于标识资源的字符串。用户可通过使用这种标识符对网络中(一般指万维网)的资源通过特定的协议进行交互操作。如超文本,邮件地址,Internet主机,或其他互联网资源。URI的最常见的形式是URL。更罕见的用法是URN。URI范式图示如下:
(2) URN
URN 全称是 Uniform Resource Name,中文翻译是统一资源名称。URN 是一个通过名字来标识资源的字符串。URN 仅命名资源但不指定如何定位资源,比如:只告诉你一个人的姓名,不告诉你这个人在哪。URN 示例如下:
urn:issn:1535-3613 (国际标准期刊编号)
urn:isbn:9787115318893 (国际标准图书编号)
(3) URI、URL、 URN的区别
简单来说,URI 用来标识资源的唯一性,URL 则用来通过一个唯一的地址定位一个资源;URN 则通过一个唯一的名称命名一个资源。注意,URN开头必须使用"urn"这一特殊符号来标识。
URI是URL和URN的超集。URL是URI的子集,除了识别资源外,还通过描述其主要访问机制(例如其网络“位置”)来提供定位资源的手段。URN也是URI的子集,是一个通过名字来标识资源的字符串。对于URN来说,即使资源不再存在或变得不可用,也需要保持全局唯一性和持久性。下面是URI 官方文档给出三者区别的原文:
A URI can be further classified as a locator, a name, or both. The term "Uniform Resource Locator" (URL) refers to the
subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing
its primary access mechanism(e.g., its network "location"). The term "Uniform Resource Name" (URN) has been used
historically to refer to both URIs under the "urn" scheme [RFC2141], which are required to remain globally unique and
persistent even when the resource ceases to exist or becomes unavailable, and to any other URI with the properties of a name.
URI、URL、 URN 三者差异的图示如下:
HTTP Request
HTTP Request(HTTP 请求)是客户端向服务端发送请求动作,告知服务器自己的要求。HTTP请求由状态行、消息头、空行、消息正文四个部分组成。其中,状态行包括请求方式Method、资源路径URL、协议版本Version;消息头包括一些访问的域名、用户代理、Cookie等信息;消息正文就是HTTP请求的数据;空行位于消息头和消息正文之间,用于分隔消息头和消息正文。HTTP 请求结构如下:

(1) 状态行
状态行在 HTTP 请求中也被称为“请求行”,包含请求方法、资源路径URL、协议版本三个部分。其中:
(a) 请求方法(GET、POST、HEAD、OPTIONS、PUT、DELETE、TRACE、CONNECT、PATCH)的说明及使用可参考HTTP请求方法一节;
(b) 资源路径URL就是用来定位资源在Internt的位置,更多URL相关介绍参考HTTP URL一节;
© 协议版本指明当前使用HTTP协议版本,更多HTTP协议介绍参考HTTP协议版本发展一节。
(2) 消息头
消息头在 HTTP 请求中也被称为“请求头”。消息头由一系列键值对组成。包括访问的域名、用户代理、Cookie等信息。这里介绍一些常用键值对。
Host 是请求报头域,用于指定被请求资源的 Internet 主机和端口号,它通常从 HTTP URL 中提取出来。
Connection 表示连接状态,keep-alive 表示该连接是持久连接(persistent connection),即 TCP 连接默认不关闭,可以被多个请求复用,如果客户端和服务器发现对方有一段时间没有活动,就可以主动关闭连接。
User-Agent 用于标识请求者的一些信息,比如浏览器类型和版本,操作系统等。
Accept 用于指定客户端希望接受哪些类型的信息,比如 text/html, image/gif 等。
Cookie 用于维护状态,可做用户认证,服务器检验等,它是浏览器储存在用户电脑上的文本片段。更多Cookie的介绍参考Cookie和Session一节。
Chrome Dev Tool的network捕获的请求头的实例如下:
(3) 消息正文
消息正文,也称“请求正文”,记录请求消息主体。
HTTP Response
HTTP Response(HTTP 响应)是服务器返回给客户端已发送HTTP请求的执行结果。HTTP 响应和HTTP请求一样,由四部分组成:状态行、消息头、空行、消息正文。其中,状态行包括协议版本Version、状态码Status Code、状态消息等内容;消息头包括搭建服务器的软件,发送响应的时间,回应数据的格式等信息;消息正文就是HTTP响应的数据。空行位于消息头和消息正文之间,用于分隔消息头和消息正文。HTTP 响应结构如下:

(1)状态行
状态行在HTTP响应中也被称为“响应行”。响应行由HTTP协议版本号,状态码,状态消息三部分组成。其中:
(a) 协议版本,与HTTP请求行中协议版本作用一致,用来指明当前使用HTTP协议版本,更多HTTP协议介绍参考HTTP协议版本发展一节;
(b) 状态码,用以表示服务器响应状态的三位数字代码,更多信息参考HTTP状态码一节。
(2)消息头
消息头在 HTTP响应中也被称为“响应头”,与HTTP请求的请求头一致,由一系列键值对组成。消息头包括访消息头包括搭建服务器的软件,发送响应的时间,回应数据的格式等信息。这里介绍一些常用键值对。
Connection 表示连接状态,和请求头中该属性作用一致。
Server 记录服务器用来处理请求的软件信息,跟请求报头域 User-Agent 相对应。
Content-Type 用于指定发送给接收者(如浏览器)响应正文的MIME(媒体)类型,比如 text/html, text/css, image/png, image/jpeg, video/mp4, application/pdf, application/json 等,编码类型是UTF-8。(实现超媒体的入口)
Content-Length 指明本次回应的数据长度。
Date 生成响应的日期和时间。
Chrome Dev Tool的network捕获的请求头的实例如下:
(3)消息正文
消息正文,也称“响应正文”,记录响应消息主体。
HTTP协议补充
补充HTTP协议中关联概念,如HTTP协议版本发展,HTTP请求方,Cookie和Session,HTTP状态码等。
HTTP协议版本发展
(1) HTTP/0.9
1991年发布,是HTTP协议的最初版本,功能简单,仅支持请求方式GET,并且仅能请求访问HTML格式的资源。使用这个版本完全可以构建一个简单的静态网站。
(2) HTTP/1.0
1996年发布。在0.9版本基础上进行改进:增加了请求方式POST和HEAD;可根据Content-Type支持多种数据格式,即MIME多用途互联网邮件扩展,如text/html、image/jpeg等;同时也开始支持cache,就是当客户端在规定时间内访问统一网站,直接访问cache即可;请求消息和响应消息也不是单一的,规定了一些元数据字段,例如:字符集、编码、状态码等。 但是1.0版本的工作方式是每次TCP连接只能发送一个请求,当服务器响应后就会关闭这次连接,下一个请求需要再次建立TCP连接,就是不支持keep-alive。(仅支持多连接,不支持长连接)
(3) HTTP/1.1
1997年发布。在1.0 版本发布之后的半年时间发布了1.1版本。该版本在1.0版本的基础上进行完善:解决了1.0版本的keep-alive问题(支持长连接,也成持久连接),加入了管道机制,这样一个TCP连接可以包含多个HTTP请求;增加了PUT、PATCH、OPTIONS、DELETE等命令,丰富了客户端和服务端交互动作;增加了Host字段等。
但是该版本还存在一些问题,服务端是按队列顺序处理请求的,假如一个请求处理时间很长,则会导致后边的请求无法处理,这样就造成了队头阻塞的问题;同时HTTP是无状态的连接,因此每次请求都需要添加重复的字段,降低了带宽的利用率。
当前主流的协议版本还是HTTP/1.1版本。
(4) HTTP/2.0
2005年发布。为了解决1.1版本利用率不高的问题,提出了HTTP/2.0版本:增加双工模式,即不仅客户端能够同时发送多个请求,服务端也能同时处理多个请求,解决了队头堵塞的问题;HTTP请求和响应中,状态行和请求/响应头都是些信息字段,并没有真正的数据,因此在2.0版本中将所有的信息字段建立一张表,为表中的每个字段建立索引,客户端和服务端共同使用这个表,他们之间就以索引号来表示信息字段,这样就避免了1.0旧版本的重复繁琐的字段,并以压缩的方式传输,提高利用率;增加服务器主动推送的功能,即不经请求服务端主动向客户端发送数据。
HTTP请求方法
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP0.9定义了 GET 请求方法。
HTTP1.0定义了 POST 和 HEAD请求方法。
HTTP1.1新增了 OPTIONS, PUT, DELETE, TRACE, CONNECT 和 PATCH请求方法。
GET 获取资源。请求指定的页面信息,并返回实体主体。
HEAD 获取响应消息报头。类似于get请求,只不过返回的响应中没有具体的内容。
POST 传输实体数据。向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
DELETE 删除资源。请求服务器删除指定的页面。
PUT 传输文件。从客户端向服务器传送的数据取代指定文档的内容。
PATCH 局部更新已知资源。对 PUT 方法的补充,用来对已知资源进行局部更新。
CONNECT 更改连接为管道方式的代理服务求。HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
OPTIONS 查询服务器的性能,或者查询与资源相关的选项和需求。
TRACE 回显服务器收到的请求,主要用于测试或诊断。
Cookie和Session
(1) Cookie数据存放在客户的浏览器上,Session数据放在服务器上;
(2) 相比Session,Cookie更不安全,因为他人可以分析存放在本地的COOKIE并进行COOKIE欺骗。考虑到安全,应使用Session或者使用加密技术对Cookie数据进行加密;
(3) Session默认仅在服务器保存一段时间。当访问增多,会比较占用你服务器的性能。考虑到减轻服务器性能方面,应当使用Cookie;
(4) 单个Cookie在客户端的限制是3K(也有说4K),就是说一个站点在客户端存放的COOKIE不能超过3K;且Cookie的数量也有限制;
(5) Cookie和Session都是为了保存客户端和服务端之间的会话,实现机制不同。
(6) 服务端Session的实现依赖客户端Cookie。服务端生成Session ID后,会将这个ID发送给客户端,然后客户端在后续的请求中都会把这个ID值放到HTTP请求的头部发送给服务端,而这个ID在客户端保存的常用容器就是Cookie。如果浏览器不支持Cookie或禁用Cookie,则需要使用其他机制(如URL重写机制,表单隐藏字段)代替Cookie暂存Session ID。
HTTP状态码
状态代码有三位数字组成,并使用第一个数字定义响应的类别,共分五类:
1xx:指示信息–表示请求已接收,请求者继续执行操作
2xx:请求成功–表示请求已被成功接收、理解、接受
3xx:请求重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态码有:文章来源:https://www.toymoban.com/news/detail-691167.html
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
429 Too Many Requests //在一定的时间内用户发送了太多的请求,即超出了“频次限制”
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
参考
https://www.w3.org/Protocols/ HTTP - Hypertext Transfer Protocol
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol Hypertext Transfer Protocol
https://blog.51cto.com/13570193/2108347 HTTP协议详解
https://www.cnblogs.com/ranyonsue/p/5984001.html HTTP协议详解
http://www.javvin.com/protocol/rfc1945.pdf :Hypertext Transfer Protocol – HTTP 1.0
http://www.javvin.com/protocol/rfc2616.pdf :Hypertext Transfer Protocol – HTTP 1.1
https://zhuanlan.zhihu.com/p/466239718 面试必备:计算机网络常问的六十二个问题
https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol Hypertext_Transfer_Protocol
https://www.w3.org/Protocols/ HTTP协议
https://www.infobip.com/glossary/http What is HTTP (Hypertext Transfer Protocol)
https://medium.com/@rcrohitcse/http-protocol-28b0c7295385 HTTP Protocol Overview
https://www.runoob.com/http/http-status-codes.html HTTP状态码
https://tool.oschina.net/commons?type=5 HTTP状态码
https://www.jianshu.com/p/a0509bb02b26 理解HTTP协议
https://www.cnblogs.com/andy-zhou/p/5360107.html 理解Cookie和Session机制
https://www.cnblogs.com/ranyonsue/p/5984001.html HTTP协议简介
https://www.runoob.com/http/http-methods.html HTTP 请求方法
https://www.techopedia.com/definition/3105/hypermedia Hypermedia
https://baike.baidu.com/item/超文本 超文本
https://baike.baidu.com/item/Hypermedia/3177297 超媒体
https://www.jianshu.com/p/8b4d9db3fd02 浏览器的HTMl解析器
https://segmentfault.com/a/1190000016253407 浏览器如何解析html、css、js
https://blog.csdn.net/u014421556/article/details/51671353 http、https 等 常用默认端口号
https://en.wikipedia.org/wiki/URI URI
https://en.wikipedia.org/wiki/Uniform_Resource_Identifier Uniform_Resource_Identifier
https://tools.ietf.org/html/rfc3986 Uniform Resource Identifier (URI): Generic Syntax
https://www.jianshu.com/p/09ac6fc0f8cb URI、 URL 和 URN 的区别
https://danielmiessler.com/study/url-uri/ What’s the Difference Between a URI and a URL?文章来源地址https://www.toymoban.com/news/detail-691167.html
到了这里,关于HTTP协议概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!