缓存的数据一致性
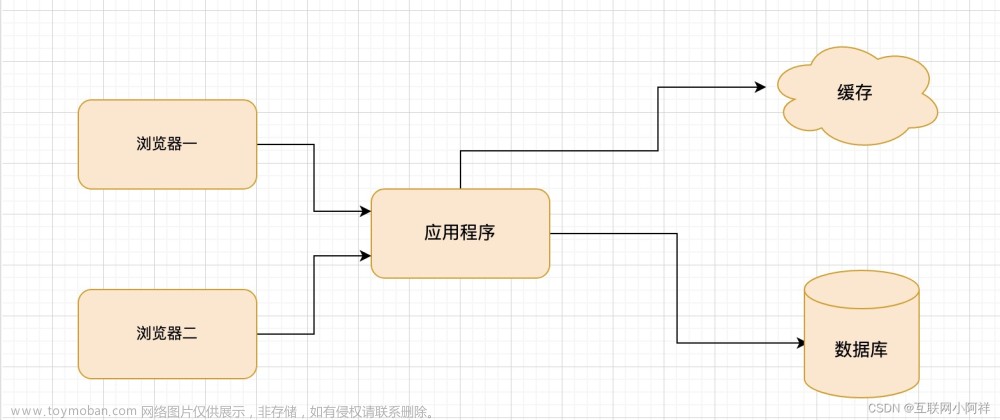
只要使用到缓存,无论是本地内存做缓存还是使用 redis 做缓存,那么就会存在数据同步的问题。
先读缓存数据,缓存数据有,则立即返回结果;如果没有数据,则从数据库读数据,并且把读到的数据同步到缓存里,提供下次读请求返回数据。
这样能有效减轻数据库压力,但是如果修改删除数据,因为缓存无法感知到数据在数据库的修改。这样就会造成数据库中的数据与缓存中数据不一致的问题
更新缓存类
1、先更新缓存,再更新 DB
这个方案我们一般不考虑。原因是更新缓存成功,更新数据库出现异常了,导致缓存数据与数据库数据完全不一致,而且很难察觉,因为缓存中的数据一直都存在。
2. 先更新 DB,再更新缓存
这个方案也我们一般不考虑,原因跟第一个一样,数据库更新成功了,缓存更新失败,同样会出现数据不一致问题。
删除缓存类
3、先删除缓存,后更新 DB。该方案会读取到脏数据同时会 有击穿风险
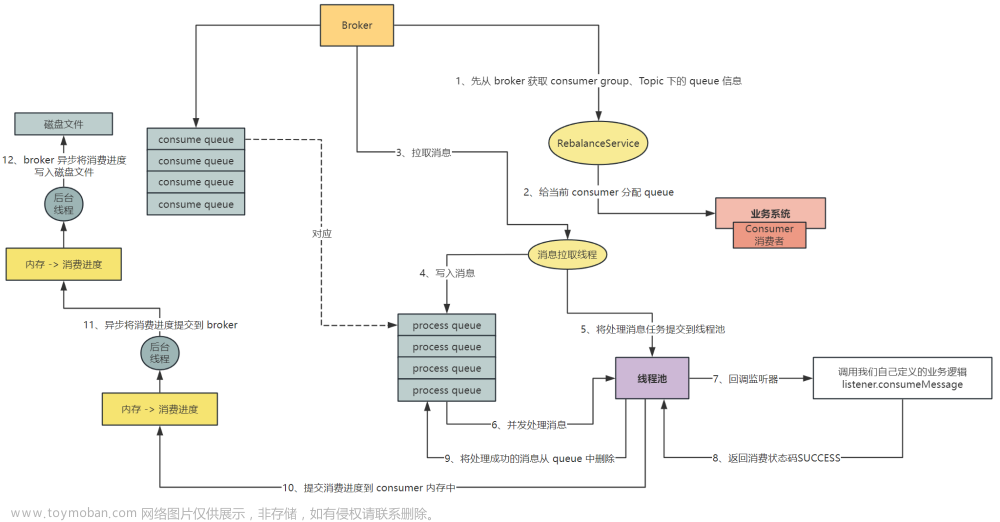
4、先更新 DB,后删除缓存
读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。这种情况不存在并发问题么?(脏数据问题)
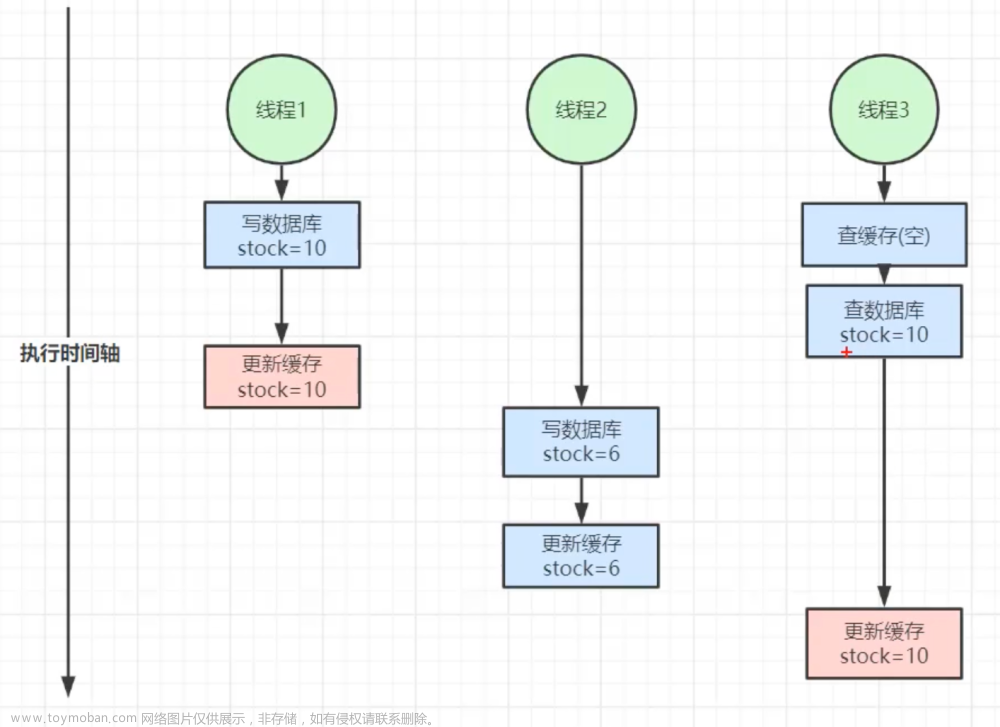
假设这会有两个请求,一个请求 A 做查询操作,一个请求 B 做
更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求 A 查询数据库,得一个旧值
(3)请求 B 将新值写入数据库
(4)请求 B 删除缓存
(5)请求 A 将查到的旧值写入缓存
如果发生上述情况,确实是会发生脏数据。然而,发生这种情况的概率不高(写操作比读操作执行效率要快)
这一情形很难出现。但一定要解决这种并发问题怎么办?
首先,给缓存设有效时间是一种方案。
其次,采用异步延时删除策略。
但是,更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功怎么办?这个问题,在删除缓存类的方案都是存在的,那么此时再读取缓存的时候每次都是错误的数据了。
此时解决方案有两个,一是就是利用消息队列进行删除的补偿。具体的业务逻辑用语言描述如下:
(更新成功后删除失败,向mq队列中发送一条消息,消费者进行删除redis的key)
1、请求 A 先对数据库进行更新操作
2、在对 Redis 进行删除操作的时候发现报错,删除失败
3、此时将 Redis 的 key 作为消息体发送到消息队列中
4、系统接收到消息队列发送的消息后
5、再次对 Redis 进行删除操作
但是这个方案会有一个缺点就是会对业务代码造成大量的侵入,深深的耦合在一起,所以这时会有一个更好的优化方案,对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。
说到底就是通过数据库的 binlog 来异步淘汰 key,利用工具(canal)将 binlog日志采集发送到 MQ 中,然后通过 ACK 机制确认处理删除缓存。
先更新 DB,后删除缓存,这种方式,被称为 Cache Aside Pattern,属于缓存更新的设计模式之一。文章来源:https://www.toymoban.com/news/detail-691216.html
缓存一致性如果追求强一致,要么串行化,要么使用分布式读写锁,要么通过 2PC 或是 Paxos 协议保证一致性,要么就是拼命的降低并发时脏数据的概率文章来源地址https://www.toymoban.com/news/detail-691216.html
到了这里,关于电商项目part10 高并发缓存实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!