Elasticsearch 使用文档
简介
Elasticsearch 是一个开源的分布式搜索引擎,它可以快速地存储、搜索和分析大量数据。它使用 Lucene 作为底层搜索引擎,提供了 RESTful API 接口,支持多种数据格式和查询语言。
本文档将介绍 Elasticsearch 的基本概念、安装和配置、数据索引和查询、集群管理等方面的内容。
基本概念
索引
Elasticsearch 中的索引类似于关系型数据库中的表,它是一个包含多个文档的逻辑容器。每个索引都有一个唯一的名称,可以包含多个类型。
类型
类型是索引中的一个逻辑分组,它定义了文档的结构和字段。每个类型都有一个唯一的名称,可以包含多个文档。
文档
文档是 Elasticsearch 中的基本单位,它是一个 JSON 格式的数据对象。每个文档都有一个唯一的 ID,它属于一个类型,并存储在一个索引中。
分片
为了支持大规模数据存储和查询,Elasticsearch 将索引分成多个分片,每个分片可以存储一部分数据。分片可以分布在不同的节点上,从而实现分布式存储和查询。
副本
为了提高数据的可用性和容错性,Elasticsearch 支持将分片复制到多个节点上,这些复制分片称为副本。副本可以提高查询的并发性和响应速度,同时也可以在节点故障时提供数据的备份和恢复。
安装和配置
安装 Elasticsearch
Elasticsearch 可以在 Windows、Linux、Mac OS X 等操作系统上运行,它的安装非常简单,只需要下载对应版本的压缩包,解压后即可使用。
下载地址:https://www.elastic.co/downloads/elasticsearch
配置 Elasticsearch
Elasticsearch 的配置文件位于 config/elasticsearch.yml,可以通过修改该文件来配置 Elasticsearch 的参数。
以下是一些常用的配置参数:
-
cluster.name:集群名称,默认为elasticsearch。 -
node.name:节点名称,默认为随机生成的名称。 -
network.host:节点绑定的 IP 地址,默认为localhost。 -
http.port:HTTP 服务监听的端口号,默认为9200。 -
discovery.zen.ping.unicast.hosts:集群中其他节点的 IP 地址列表。
数据索引和查询
索引数据
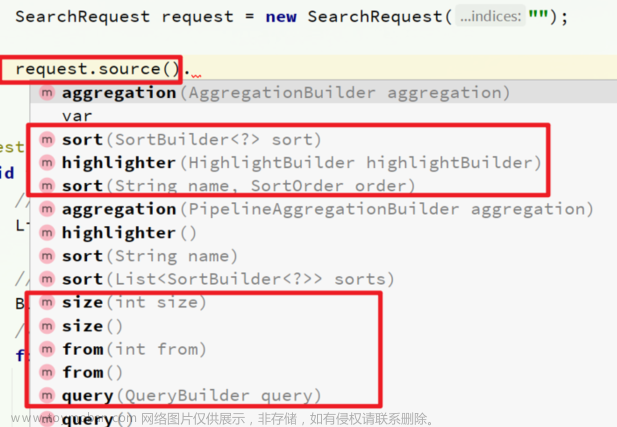
要索引数据,首先需要创建一个索引,然后定义一个类型,最后将文档添加到该类型中。
以下是一个示例:
# 创建索引
PUT /my_index
# 定义类型
PUT /my_index/my_type/_mapping
{
"properties": {
"title": {
"type": "text"
},
"content": {
"type": "text"
},
"timestamp": {
"type": "date"
}
}
}
# 添加文档
PUT /my_index/my_type/1
{
"title": "Hello World",
"content": "This is my first Elasticsearch document",
"timestamp": "2022-01-01T00:00:00"
}
查询数据
要查询数据,可以使用 Elasticsearch 提供的 RESTful API 接口,支持多种查询语言和查询方式。
以下是一些常用的查询语句:
-
GET /my_index/my_type/_search:查询所有文档。 -
GET /my_index/my_type/_search?q=title:hello:查询标题包含 “hello” 的文档。 -
GET /my_index/my_type/_search?q=content:elasticsearch:查询内容包含 “elasticsearch” 的文档。 -
GET /my_index/my_type/_search?q=timestamp:>2022-01-01:查询时间戳大于 “2022-01-01” 的文档。 -
GET /my_index/my_type/_search?q=title:hello AND content:elasticsearch:查询标题包含 “hello” 并且内容包含 “elasticsearch” 的文档。
集群管理
集群健康状态
要查看集群的健康状态,可以使用以下命令:
GET /_cluster/health
该命令将返回一个 JSON 格式的响应,包含集群的健康状态、节点数量、分片数量等信息。
节点信息
要查看节点的信息,可以使用以下命令:
GET /_cat/nodes?v
该命令将返回一个表格格式的响应,包含节点的名称、IP 地址、状态等信息。
分片信息
要查看分片的信息,可以使用以下命令:
GET /_cat/shards?v
该命令将返回一个表格格式的响应,包含分片的索引名称、分片编号、状态等信息。
节点加入和退出
要将节点加入集群,可以在节点的配置文件中设置 discovery.zen.ping.unicast.hosts
要将一个新节点加入到Elasticsearch集群中,需要做以下步骤:
- 在新节点上安装Elasticsearch软件。
- 配置新节点的elasticsearch.yml文件,指定集群名称和节点名称。
- 启动新节点的Elasticsearch服务。
新节点启动后,它会自动加入到集群中,并开始接收和处理请求。
节点退出集群:
要将一个节点从Elasticsearch集群中移除,需要做以下步骤:
- 停止节点上的Elasticsearch服务。
- 在集群中的其他节点上运行_cluster/nodes/stats API,以查看节点的状态和信息。
- 在集群中的其他节点上运行_cluster/nodes/_shutdown API,以关闭要移除的节点。
节点关闭后,它会自动从集群中移除,并停止处理请求。
需要注意的是,节点的加入和退出可能会对集群的性能和可用性产生影响,因此应该在非高峰期进行操作,并确保在操作前备份数据。
Elasticsearch 提供的 RESTful API 接口 Java 的使用方法和案例
Elasticsearch 是一个开源的分布式搜索引擎,提供了 RESTful API 接口,可用于实现搜索、聚合、索引等功能。在 Java 中,我们可以使用 Elasticsearch 的 Java API 或者直接调用 RESTful API 接口来操作 Elasticsearch。
本文将介绍 Elasticsearch RESTful API 接口的使用方法和一个简单的案例。
使用 Elasticsearch RESTful API 接口
Elasticsearch 的 RESTful API 接口可以通过 HTTP 请求来访问,常用的请求方法包括 GET、POST、PUT、DELETE 等。下面是一个使用 Elasticsearch RESTful API 接口的简单示例:
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpDelete;
import org.apache.http.client.methods.HttpPut;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class ElasticsearchRestClient {
private static CloseableHttpClient httpClient =
HttpClients.createDefault();
private static final String INDEX_NAME = "test_index";
private static final String BASE_URL = "http://localhost:9200/" + INDEX_NAME + "/_doc/";
public static void main(String[] args) {
try {
// 创建文档
createDocument();
// 获取文档
getDocument();
// 更新文档
updateDocument();
// 删除文档
deleteDocument();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void createDocument() throws IOException {
String json = "{ \"name\" : \"John\", \"age\" : 30 }";
HttpPost httpPost = new HttpPost(BASE_URL + "1");
httpPost.setEntity(new StringEntity(json, ContentType.APPLICATION_JSON));
CloseableHttpResponse response = httpClient.execute(httpPost);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
System.out.println("Create document result: " + result);
response.close();
}
public static void getDocument() throws IOException {
HttpGet httpGet = new HttpGet(BASE_URL + "1");
CloseableHttpResponse response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
System.out.println("Get document result: " + result);
response.close();
}
public static void updateDocument() throws IOException {
String json = "{ \"name\" : \"John Doe\", \"age\" : 35 }";
HttpPut httpPut = new HttpPut(BASE_URL + "1");
httpPut.setEntity(new StringEntity(json, ContentType.APPLICATION_JSON));
CloseableHttpResponse response = httpClient.execute(httpPut);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
System.out.println("Update document result: " + result);
response.close();
}
public static void deleteDocument() throws IOException {
HttpDelete httpDelete = new HttpDelete(BASE_URL + "1");
CloseableHttpResponse response = httpClient.execute(httpDelete);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
System.out.println("Delete document result: " + result);
response.close();
}
}
在上面的示例中,我们使用了 Apache HttpComponents 来发送 HTTP 请求。其中,创建文档使用了 POST 请求,获取文档使用了 GET 请求,更新文档使用了 PUT 请求,删除文档使用了 DELETE 请求。
示例:在 Elasticsearch 中搜索文档
下面是一个简单的示例,演示了如何在 Elasticsearch 中搜索文档。
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class ElasticsearchSearchClient {
private static CloseableHttpClient httpClient =
HttpClients.createDefault();
private static final String INDEX_NAME = "test_index";
private static final String SEARCH_URL = "http://localhost:9200/" + INDEX_NAME + "/_search";
public static void main(String[] args) {
try {
searchDocument();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void searchDocument() throws IOException {
String json = "{ \"query\": { \"match\": { \"name\": \"John\" } } }";
HttpGet httpGet = new HttpGet(SEARCH_URL);
httpGet.setEntity(new StringEntity(json, ContentType.APPLICATION_JSON));
CloseableHttpResponse response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
System.out.println("Search document result: " + result);
response.close();
}
}
在上面的示例中,我们使用了 Elasticsearch 的查询语法,通过 match 查询来搜索名字为 John 的文档。文章来源:https://www.toymoban.com/news/detail-691225.html
结论
在本文中,我们介绍了 Elasticsearch RESTful API 接口的使用方法和一个简单的案例。使用 Elasticsearch RESTful API 接口,我们可以在 Java 中方便地操作 Elasticsearch,实现搜索、聚合、索引等功能。文章来源地址https://www.toymoban.com/news/detail-691225.html
到了这里,关于Elasticsearch 详细使用文档及java案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!