摘要
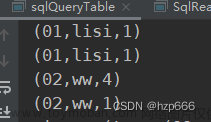
很多时候flink消费上游kafka的数据是有重复的,因此有时候我们想数据在落盘之前进行去重,这在实际开发中具有广泛的应用场景,此处不说详细代码,只粘贴相应的flinksql文章来源地址https://www.toymoban.com/news/detail-691233.html
代码
--********************************************************************--
-- 创建临时表(只在当前sessoin生效的表称为临时表) DDL
CREATE TEMPORARY TABLE UserAttrSource (
`data` string,
`kafkaMetaTimestamp` TIMESTAMP(3) METADATA FROM 'timestamp', -- kafka record携带的源数据时间戳,参考官网kafka connector
proctime as PROCTIME() -- 获取数据处理时间,这是flink内置支持的关键字
) WITH (
'connector' = 'kafka',
'topic' = 'user_attri_ad_dirty_data',
'properties.bootstrap.servers' = 'kafka地址',
'scan.startup.mode' = 'timestamp', -- kafka扫描数据模式,参考官网kafka connector
'scan.startup.timestamp-millis' ='1687305600000' , -- 2023-06-21 08:00:00
'format' = 'raw' -- 意思是将kafka数据格式化为string
);
-- 创建SINK 表
CREATE TEMPORARY TABLE ADB (
log_date DATE,
`errorType` int,
appId string,
`errorCode` int,
`errorReason` string,
`deserialization` string,
`originalData` string,
kafkaMetaTimestamp TIMESTAMP,
data_hash string,
PRIMARY KEY (`data_hash`) NOT ENFORCED
)
WITH (
'connector' = 'adb3.0',
'url' = 'jdbc:mysql://xxxx:3306/flink_data?rewriteBatchedStatements=true',
'tableName' = 'usr_attr_dirty',
'userName'='username',
'password'='password'
);
-- 去重视图, 这是关键(json_value是flink的内置函数,data_hash是数据本身的primary key)
-- 下述语句含义是:根据data_hash字段分组,按照处理时间排序,取出最新的一条数据,其他的重复数据将被抛弃
CREATE TEMPORARY VIEW quchong AS
SELECT
data,
kafkaMetaTimestamp FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY json_value(data,'$.data_hash') ORDER BY proctime DESC) as row_num
FROM UserAttrSource
)
WHERE row_num = 1;
-- 插入目标表
insert into ADB
select
TO_DATE(DATE_FORMAT(kafkaMetaTimestamp,'yyyy-MM-dd') )AS log_date,
json_value(data,'$.errorType' RETURNING INT) errorType,
json_value(data,'$.appId' NULL ON EMPTY) appId,
json_value(data,'$.errorCode' RETURNING INT) errorCode,
json_value(data,'$.errorReason' NULL ON EMPTY) errorReason,
json_value(data,'$.deserialization' NULL ON EMPTY) deserialization,
json_value(data,'$.originalData') originalData,
kafkaMetaTimestamp,
json_value(data,'$.data_hash') data_hash
from quchong;
文章来源:https://www.toymoban.com/news/detail-691233.html
到了这里,关于FlinkSql 如何实现数据去重?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!