学习目标:三栖合一架构师
本文是《大数据HBase学习圣经》 V1版本,是 《尼恩 大数据 面试宝典》姊妹篇。
这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经汇集了 好几百题,大量的大厂面试干货、正货 。 《尼恩 大数据 面试宝典》面试题集合, 将变成大数据学习和面试的必读书籍。
于是,尼恩架构团队 趁热打铁,推出 《大数据Flink学习圣经》,《大数据HBASE学习圣经》(本文)
《大数据HBase学习圣经》 后面会不断升级,不断 迭代, 变成大数据领域 学习和面试的必读书籍,
最终,帮助大家成长为 三栖合一架构师,进大厂,拿高薪。

《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公号【技术自由圈】获取
“Java+大数据” 双栖架构成功案例
成功案例1:
惊天大逆袭:失业4个月,3年小伙1个月喜提架构Offer,而且是大龄跨行,超级牛
成功案例2:
极速拿offer:阿里P6被裁后极速上岸,1个月内喜提2优质offer(含滴滴)
1. 引言
在当今数字化的时代,数据已经成为了推动商业、科研和社会发展的关键资源。随着互联网、物联网和传感器技术的快速发展,大规模数据的产生呈爆炸式增长,这种数据潮流已经超越了传统关系型数据库的处理能力。在这个新的数据格局下,分布式NoSQL数据库逐渐崭露头角,成为了解决大数据存储和处理难题的利器。
1.1 数据的价值与挑战
数据已经成为当今世界的黄金,企业通过数据分析来洞察市场趋势、预测客户行为,科学家利用数据来研究气候变化、疾病传播等重要议题。然而,这种数据的大量涌现也带来了巨大的挑战。传统的关系型数据库往往无法应对数据规模的快速扩张,其数据模型和架构无法满足大规模数据存储和高性能处理的需求。
1.2 NoSQL数据库的崛起
为了应对这一挑战,分布式NoSQL(Not Only SQL)数据库应运而生。与传统关系型数据库不同,NoSQL数据库采用了更加灵活的数据模型和分布式架构,能够有效地处理海量数据,并且能够水平扩展以满足不断增长的需求。主流的NoSQL数据库如MongoDB、Cassandra和HBase等各自拥有独特的特点,适用于不同的应用场景。
1.3 引入HBase
在众多NoSQL数据库中,HBase以其出色的大数据存储和实时查询能力而备受瞩目。HBase是一款开源的分布式、可扩展、高性能的NoSQL数据库,构建在Hadoop生态系统之上。它以其在处理海量数据和实现随机访问方面的卓越表现而引起广泛关注。通过使用HBase,用户能够轻松地存储、管理和检索海量数据,从而在大数据时代获得更多的商业和科研价值。
1.4 本文的目标
本文旨在为初学者提供关于HBase的基础知识,帮助他们了解HBase的特点、适用场景以及基本操作。从HBase的概述到高级操作,我们将逐步引导大家深入了解这个强大的分布式NoSQL数据库,在大数据领域的探索之旅提供支持和指引。
2. HBase概述
2.1 什么是HBase?
HBase(Hadoop Database的缩写)是一个开源的分布式、可扩展、高性能的NoSQL数据库,它是基于Google的Bigtable论文设计而来,构建在Hadoop生态系统之上。HBase的设计目标是为了处理海量数据,并且在这些数据上实现高效的实时随机访问。相比传统的关系型数据库,HBase提供了更适合大规模数据处理的数据模型和架构。
2.2 HBase的特点
HBase具备许多独特的特点,使其成为处理大规模数据的理想选择:
- 分布式架构: HBase使用分布式架构,数据被分割成多个Region并分布在多个RegionServer上。这使得HBase可以水平扩展,支持海量数据的存储和处理。
- 列式存储: HBase采用列式存储,数据按列存储在磁盘上,这种方式有助于节约存储空间和提高查询效率。
- 稀疏数据: HBase支持稀疏数据,这意味着每一行数据不需要都包含相同的列,这对于处理具有不同属性的数据非常有用。
- 实时随机访问: HBase支持实时的随机读写操作,使其适用于需要低延迟的应用场景,如实时分析和数据查询。
- 强一致性: HBase提供强一致性的数据访问,可以确保数据的准确性和一致性。
2.3 HBase与传统关系型数据库的区别
HBase与传统的关系型数据库在数据模型和架构上存在显著的区别:
- 数据模型: 传统关系型数据库使用表格模型,数据以结构化的行和列的方式存储。而HBase使用了Bigtable模型,将数据按照列族存储,每个列族可以包含多个列。
- 架构: 传统关系型数据库通常以单机为基础,随着数据增长,可能需要进行垂直扩展。而HBase采用分布式架构,支持水平扩展,可以轻松处理大规模数据。
- 查询语言: 传统关系型数据库使用SQL进行查询,而HBase没有提供SQL查询语言。查询HBase数据通常需要编写Java或其他编程语言的代码。
- 灵活性: HBase在数据模型和架构上更加灵活,适用于存储和处理各种类型的数据,包括结构化、半结构化和非结构化数据。
2.4 HBase的应用场景
HBase作为一款分布式、高性能的NoSQL数据库,适用于多种应用场景,特别是在处理大规模数据和需要实时随机访问的情况下,它发挥着重要的作用。
2.4.1 大数据存储与处理
HBase的分布式架构使其非常适合存储和处理大规模数据。在大数据应用中,数据量可能达到甚至超过PB级,传统的关系型数据库很难胜任。HBase的分布式存储和自动水平扩展能力,使得它能够轻松应对这种大规模数据的存储和查询需求。
2.4.2 实时数据分析
对于需要实时数据分析的场景,HBase也具备优势。实时数据分析要求系统能够迅速地查询和获取数据,而HBase支持实时的随机读写操作,使其能够在数据到达时即时分析,并得出有价值的结论。
2.4.3 日志数据存储
很多应用产生大量的日志数据,这些数据在很大程度上是非结构化的,而且需要长期保留以便后续分析。HBase的稀疏数据模型和高效的存储能力使得它成为了存储这些日志数据的理想选择。通过HBase,您可以方便地存储、检索和分析海量的日志数据。
2.4.4 时序数据存储
时序数据是时间序列的数据,如传感器数据、股票价格、气象数据等。HBase的分布式架构和实时查询能力,使其非常适合存储和处理时序数据。您可以根据时间戳进行快速查询,支持快速的历史数据回溯和实时监控。
2.4.5 高并发随机访问
一些应用需要支持高并发的随机访问,传统关系型数据库往往无法满足这种需求。HBase的设计目标之一就是实现高性能的实时随机访问,它的分布式架构和列式存储使得它能够轻松应对高并发的读写请求。
2.4.6 全文搜索
虽然HBase不是一款专门的全文搜索引擎,但在某些情况下,它也可以用于存储全文索引数据。通过将索引数据存储在HBase中,您可以实现基于关键词的快速检索。
总之,HBase的应用场景广泛,尤其在处理大规模数据、实时性要求高和随机访问频繁的场景下,它能够发挥出其强大的特点。从存储日志数据到实时数据分析,从时序数据存储到高并发随机访问,HBase都能够为您提供可靠的解决方案。接下来,我们将深入探讨如何安装和配置HBase,为您搭建一个高效的数据存储和处理环境。
3. 安装与配置
参考 Apache HBase 配置_Hbase 中文文档
HBase的安装是您开始使用这个强大数据库的第一步。在本节中,我们将为您介绍HBase的安装方式,并详细说明如何在不同模式下进行安装和配置。
3.1 HBase安装方式概述
HBase的安装可以分为以下几种方式:
- 本地模式(Standalone Mode): 本地模式是最简单的安装方式,适用于在本地单机上进行开发和测试。在本地模式下,HBase将运行在单一的Java进程中,数据存储在本地文件系统。
- 完全分布式模式(Fully-Distributed Mode): 完全分布式模式是在真实的分布式环境中部署HBase的方式。在完全分布式模式下,HBase的各个组件分布在多台计算机上,以实现高可用性、容错性和性能扩展。
在接下来的小节中,我们将详细说明每种安装方式的步骤和配置方法,帮助您根据实际需求选择合适的安装方式。
3.2 本地模式安装与配置
本地模式安装非常适合初学者,它可以让您在不投入太多配置的情况下迅速体验HBase的基本功能。在本地模式下,HBase将运行在单一的Java进程中,数据存储在本地文件系统。
Hbase单节点配置是在没有多台计算机节点的情况下,对Hbase的分布式存储和计算进行模拟安装和配置。通过在一台计算机节点上解压Hbase安装压缩包后,然后进行Hbase相关文件进行配置,让Hbase运行在一台机器上并实现对数据存储和计算的测试支持。默认情况下,Hbase运行在单机模式下。在单机模式中,Hbase使用本地文件系统,而不是HDFS。
步骤:
-
准备环境:
确保您的系统上已经安装了Java Development Kit(JDK)。HBase需要Java运行环境。 -
下载HBase:
Index of /dist/hbase/2.5.5 (apache.org) -
解压缩HBase压缩包:
在您选择的目录中解压缩下载的HBase压缩包。您可以使用以下命令(假设您的压缩包是hbase-x.x.x.tar.gz):
tar -xzvf hbase-2.5.5-bin.tar.gz
-
配置HBase:
进入解压缩后的HBase目录,编辑conf/hbase-site.xml文件以进行配置。以下是一个示例配置:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/docker/hbase/data</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/docker/hbase/zookeeper</value>
</property>
</configuration>
请替换上述示例中的路径为您实际希望存储数据的路径。
-
启动HBase:
打开终端,导航到HBase目录,然后运行以下命令来启动HBase:
./bin/start-hbase.sh
-
访问HBase Shell:
您可以使用HBase Shell与本地模式下的HBase进行交互。在终端中,运行以下命令:
./bin/hbase shell
这将打开HBase Shell,您可以在其中执行HBase命令。
-
停止HBase:
要停止HBase,回到终端,导航到HBase目录,然后运行以下命令:
./bin/stop-hbase.sh
这些步骤将在本地模式下安装和运行HBase。请注意,本地模式下的HBase不适用于生产环境,但可以用于学习和开发目的。如果您要在分布式环境中使用HBase,需要进行更详细的配置和设置。
3.3 完全分布式模式安装与配置
完全分布式模式是在真实的分布式环境中部署HBase的方式,它适用于需要处理大规模数据和实现高可用性的场景。在完全分布式模式下,HBase的各个组件分布在多台计算机上,通过配置实现高可用性、容错性和性能扩展。
- 部署 docker
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 建议使用阿里云yum源:(推荐)
#yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动并开机启动
systemctl enable --now docker
docker --version
- 部署 docker-compose
curl -SL https://github.com/docker/compose/releases/download/v2.16.0/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
docker-compose --version
- 创建网络
# 创建,注意不能使用hadoop_network,要不然启动hs2服务的时候会有问题!!!
docker network create hadoop-network
# 查看
docker network ls
- 部署zookeeper
创建目录和文件
[root@cdh1 zookeeper]# tree
.
├── docker-compose.yml
├── zk1
├── zk2
└── zk3
3 directories, 1 file
docker-compose.yml
version: '3.7'
# 给zk集群配置一个网络,网络名为hadoop-network
networks:
hadoop-network:
external: true
# 配置zk集群的
# container services下的每一个子配置都对应一个zk节点的docker container
services:
zk1:
# docker container所使用的docker image
image: zookeeper
hostname: zk1
container_name: zk1
restart: always
# 配置docker container和宿主机的端口映射
ports:
- 2181:2181
- 28081:8080
# 配置docker container的环境变量
environment:
# 当前zk实例的id
ZOO_MY_ID: 1
# 整个zk集群的机器、端口列表
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
# 将docker container上的路径挂载到宿主机上 实现宿主机和docker container的数据共享
volumes:
- ./zk1/data:/data
- ./zk1/datalog:/datalog
# 当前docker container加入名为zk-net的隔离网络
networks:
- hadoop-network
zk2:
image: zookeeper
hostname: zk2
container_name: zk2
restart: always
ports:
- 2182:2181
- 28082:8080
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zk3:2888:3888;2181
volumes:
- ./zk2/data:/data
- ./zk2/datalog:/datalog
networks:
- hadoop-network
zk3:
image: zookeeper
hostname: zk3
container_name: zk3
restart: always
ports:
- 2183:2181
- 28083:8080
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
volumes:
- ./zk3/data:/data
- ./zk3/datalog:/datalog
networks:
- hadoop-network
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.8.2/apache-zookeeper-3.8.2-bin.tar.gz --no-check-certificate
启动
[root@cdh1 zookeeper]# docker-compose up -d
Creating zk3 ... done
Creating zk2 ... done
Creating zk1 ... done
- 下载Hadoop部署包
git clone https://gitee.com/hadoop-bigdata/docker-compose-hadoop.git
-
安装部署 mysql5.7
这里mysql主要是供hive存储元数据
cd docker-compose-hadoop/mysql
docker-compose -f mysql-compose.yaml up -d
docker-compose -f mysql-compose.yaml ps
#root 密码:123456,以下是登录命令,注意一般在公司不能直接在命令行明文输入密码,要不然容易被安全抓,切记,切记!!!
docker exec -it mysql mysql -uroot -p123456
- 安装hadoop和hive
cd docker-compose-hadoop/hadoop_hive
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
# hive
docker exec -it hive-hiveserver2 hive -shoe "show databases";
# hiveserver2
docker exec -it hive-hiveserver2 beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop -e "show databases;"
启动后,如果发现hadoop historyserver容器未健康启动,可以执行以下命令:
docker exec -it hadoop-hdfs-nn hdfs dfs -chmod 777 /tmp
docker restart hadoop-mr-historyserver
hdfs格式化可以执行以下命令:
[root@cdh1 ~]# docker exec -it hadoop-hdfs-nn hdfs dfsadmin -refreshNodes
Refresh nodes successful
[root@cdh1 ~]# docker exec -it hadoop-hdfs-dn-0 hdfs dfsadmin -fs hdfs://hadoop-hdfs-nn:9000 -refreshNodes
Refresh nodes successful
[root@cdh1 ~]# docker exec -it hadoop-hdfs-dn-1 hdfs dfsadmin -fs hdfs://hadoop-hdfs-nn:9000 -refreshNodes
Refresh nodes successful
[root@cdh1 ~]# docker exec -it hadoop-hdfs-dn-2 hdfs dfsadmin -fs hdfs://hadoop-hdfs-nn:9000 -refreshNodes
Refresh nodes successful
可以通过 cdh1:30070 查看HDFS分布情况

以及访问http://cdh1:30888/cluster 查看yarn资源情况

- 配置Hbase参数
mkdir conf
conf/hbase-env.sh
export JAVA_HOME=/opt/apache/jdk
export HBASE_CLASSPATH=/opt/apache/hbase/conf
export HBASE_MANAGES_ZK=false
conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-hdfs-nn:9000/hbase</value>
<!-- hdfs://ns1/hbase 对应hdfs-site.xml的dfs.nameservices属性值 -->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.master</name>
<value>60000</value>
<description>单机版需要配主机名/IP和端口,HA方式只需要配端口</description>
</property>
<property>
<name>hbase.master.info.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>16020</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value> <!--也可以用multiwal-->
</property>
</configuration>
conf/backup-masters
hbase-master-2
conf/regionservers
hbase-regionserver-1
hbase-regionserver-2
hbase-regionserver-3
conf/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--配置namenode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-hdfs-nn:9000</value>
</property>
<!-- 文件的缓冲区大小(128KB),默认值是4KB -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- 配置hadoop临时目录,存储元数据用的,请确保该目录(/opt/apache/hadoop/data/hdfs/)已被手动创建,tmp目录会自动创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apache/hadoop/data/hdfs/tmp</value>
</property>
<!--配置HDFS网页登录使用的静态用户为root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--配置root(超级用户)允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--配置root(超级用户)允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!--配置root(超级用户)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.root.user</name>
<value>*</value>
</property>
<!--配置hive允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>*</value>
</property>
<!--配置hive允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.hive.groups</name>
<value>*</value>
</property>
<!--配置hive允许通过代理访问的主机节点-->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!--配置hive允许通过代理用户所属组-->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
conf/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- namenode web访问配置 -->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<!-- 必须将dfs.webhdfs.enabled属性设置为true,否则就不能使用webhdfs的LISTSTATUS、LISTFILESTATUS等需要列出文件、文件夹状态的命令,因为这些信息都是由namenode来保存的。 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/apache/hadoop/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/apache/hadoop/data/hdfs/datanode/data1,/opt/apache/hadoop/data/hdfs/datanode/data2,/opt/apache/hadoop/data/hdfs/datanode/data3</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-hdfs-nn2:9868</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/opt/apache/hadoop/etc/hadoop/dfs.hosts</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/apache/hadoop/etc/hadoop/dfs.hosts.exclude</value>
</property>
</configuration>
完成conf配置后,需要设置读写权限
chmod -R 777 conf/
- 编写环境.env文件
HBASE_MASTER_PORT=16000
HBASE_MASTER_INFO_PORT=16010
HBASE_HOME=/opt/apache/hbase
HBASE_REGIONSERVER_PORT=16020
- 编排docker-compose.yaml
version: '3'
services:
hbase-master-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hbase:2.5.4
user: "hadoop:hadoop"
container_name: hbase-master-1
hostname: hbase-master-1
restart: always
privileged: true
env_file:
- .env
volumes:
- ./conf/hbase-env.sh:${HBASE_HOME}/conf/hbase-env.sh
- ./conf/hbase-site.xml:${HBASE_HOME}/conf/hbase-site.xml
- ./conf/backup-masters:${HBASE_HOME}/conf/backup-masters
- ./conf/regionservers:${HBASE_HOME}/conf/regionservers
- ./conf/hadoop/core-site.xml:${HBASE_HOME}/conf/core-site.xml
- ./conf/hadoop/hdfs-site.xml:${HBASE_HOME}/conf/hdfs-site.xml
ports:
- "36010:${HBASE_MASTER_PORT}"
- "36020:${HBASE_MASTER_INFO_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hbase-master"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HBASE_MASTER_PORT} || exit 1"]
interval: 10s
timeout: 20s
retries: 3
hbase-master-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hbase:2.5.4
user: "hadoop:hadoop"
container_name: hbase-master-2
hostname: hbase-master-2
restart: always
privileged: true
env_file:
- .env
volumes:
- ./conf/hbase-env.sh:${HBASE_HOME}/conf/hbase-env.sh
- ./conf/hbase-site.xml:${HBASE_HOME}/conf/hbase-site.xml
- ./conf/backup-masters:${HBASE_HOME}/conf/backup-masters
- ./conf/regionservers:${HBASE_HOME}/conf/regionservers
- ./conf/hadoop/core-site.xml:${HBASE_HOME}/conf/core-site.xml
- ./conf/hadoop/hdfs-site.xml:${HBASE_HOME}/conf/hdfs-site.xml
ports:
- "36011:${HBASE_MASTER_PORT}"
- "36021:${HBASE_MASTER_INFO_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hbase-master hbase-master-1 ${HBASE_MASTER_PORT}"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HBASE_MASTER_PORT} || exit 1"]
interval: 10s
timeout: 20s
retries: 3
hbase-regionserver-1:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hbase:2.5.4
user: "hadoop:hadoop"
container_name: hbase-regionserver-1
hostname: hbase-regionserver-1
restart: always
privileged: true
env_file:
- .env
volumes:
- ./conf/hbase-env.sh:${HBASE_HOME}/conf/hbase-env.sh
- ./conf/hbase-site.xml:${HBASE_HOME}/conf/hbase-site.xml
- ./conf/backup-masters:${HBASE_HOME}/conf/backup-masters
- ./conf/regionservers:${HBASE_HOME}/conf/regionservers
- ./conf/hadoop/core-site.xml:${HBASE_HOME}/conf/core-site.xml
- ./conf/hadoop/hdfs-site.xml:${HBASE_HOME}/conf/hdfs-site.xml
ports:
- "36030:${HBASE_REGIONSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hbase-regionserver hbase-master-1 ${HBASE_MASTER_PORT}"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HBASE_REGIONSERVER_PORT} || exit 1"]
interval: 10s
timeout: 10s
retries: 3
hbase-regionserver-2:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hbase:2.5.4
user: "hadoop:hadoop"
container_name: hbase-regionserver-2
hostname: hbase-regionserver-2
restart: always
privileged: true
env_file:
- .env
volumes:
- ./conf/hbase-env.sh:${HBASE_HOME}/conf/hbase-env.sh
- ./conf/hbase-site.xml:${HBASE_HOME}/conf/hbase-site.xml
- ./conf/backup-masters:${HBASE_HOME}/conf/backup-masters
- ./conf/regionservers:${HBASE_HOME}/conf/regionservers
- ./conf/hadoop/core-site.xml:${HBASE_HOME}/conf/core-site.xml
- ./conf/hadoop/hdfs-site.xml:${HBASE_HOME}/conf/hdfs-site.xml
ports:
- "36031:${HBASE_REGIONSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hbase-regionserver hbase-master-1 ${HBASE_MASTER_PORT}"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HBASE_REGIONSERVER_PORT} || exit 1"]
interval: 10s
timeout: 10s
retries: 3
hbase-regionserver-3:
image: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hbase:2.5.4
user: "hadoop:hadoop"
container_name: hbase-regionserver-3
hostname: hbase-regionserver-3
restart: always
privileged: true
env_file:
- .env
volumes:
- ./conf/hbase-env.sh:${HBASE_HOME}/conf/hbase-env.sh
- ./conf/hbase-site.xml:${HBASE_HOME}/conf/hbase-site.xml
- ./conf/backup-masters:${HBASE_HOME}/conf/backup-masters
- ./conf/regionservers:${HBASE_HOME}/conf/regionservers
- ./conf/hadoop/core-site.xml:${HBASE_HOME}/conf/core-site.xml
- ./conf/hadoop/hdfs-site.xml:${HBASE_HOME}/conf/hdfs-site.xml
ports:
- "36032:${HBASE_REGIONSERVER_PORT}"
command: ["sh","-c","/opt/apache/bootstrap.sh hbase-regionserver hbase-master-1 ${HBASE_MASTER_PORT}"]
networks:
- hadoop-network
healthcheck:
test: ["CMD-SHELL", "netstat -tnlp|grep :${HBASE_REGIONSERVER_PORT} || exit 1"]
interval: 10s
timeout: 10s
retries: 3
# 连接外部网络
networks:
hadoop-network:
external: true
- 开始部署
当前目录结构如下:
[root@cdh1 hbase]# tree
.
├── .env
├── conf
│ ├── backup-masters
│ ├── hadoop
│ │ ├── core-site.xml
│ │ └── hdfs-site.xml
│ ├── hbase-env.sh
│ ├── hbase-site.xml
│ └── regionservers
├── docker-compose.yaml
启动:
docker-compose -f docker-compose.yaml up -d
# 查看
docker-compose -f docker-compose.yaml ps
[root@cdh1 hbase]# docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
hbase-master-1 sh -c /opt/apache/bootstra ... Up (healthy) 0.0.0.0:36010->16000/tcp,:::36010->16000/tcp, 0.0.0.0:36020->16010/tcp,:::36020->16010/tcp
hbase-master-2 sh -c /opt/apache/bootstra ... Up (healthy) 0.0.0.0:36011->16000/tcp,:::36011->16000/tcp, 0.0.0.0:36021->16010/tcp,:::36021->16010/tcp
hbase-regionserver-1 sh -c /opt/apache/bootstra ... Up (healthy) 0.0.0.0:36030->16020/tcp,:::36030->16020/tcp
hbase-regionserver-2 sh -c /opt/apache/bootstra ... Up (healthy) 0.0.0.0:36031->16020/tcp,:::36031->16020/tcp
hbase-regionserver-3 sh -c /opt/apache/bootstra ... Up (healthy) 0.0.0.0:36032->16020/tcp,:::36032->16020/tcp
通过Master: hbase-master-1 访问集群信息

- shell测试
### 进入容器内部
[root@cdh1 hbase]# docker exec -it hbase-master-1 bash
### 进入shell环境
[hadoop@hbase-master-1 hbase-2.5.4]$ hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.5.4, r2e426ab69d126e683577b6e94f890800c5122910, Thu Apr 6 09:11:53 PDT 2023
Took 0.0012 seconds
### 简单建表
hbase:001:0> create 'user1', 'info', 'data'
Created table user1
Took 1.6409 seconds
=> Hbase::Table - user1
### 查看表信息
hbase:002:0> desc 'user1'
Table user1 is ENABLED
user1, {TABLE_ATTRIBUTES => {METADATA => {'hbase.store.file-tracker.impl' => 'DEFAULT'}}}
COLUMN FAMILIES DESCRIPTION
{NAME => 'data', INDEX_BLOCK_ENCODING => 'NONE', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '
0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536 B (64KB)'}
{NAME => 'info', INDEX_BLOCK_ENCODING => 'NONE', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '
0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536 B (64KB)'}
2 row(s)
Quota is disabled
Took 0.2303 seconds
### 查看状态
hbase:003:0> status
1 active master, 1 backup masters, 3 servers, 0 dead, 1.0000 average load
Took 0.0853 seconds
注意,如果hbase容器启动失败或有异常,可以执行以下命令
- 停止hbase相关容器
docker-compose down
- 删除zookeeper 中 hbase 节点
- 删除hdfs中hbase目录
docker exec -it hadoop-hdfs-nn hdfs dfs -rm -r /hbase
- 重启hbase容器
4. 数据操作
HBase作为一个分布式NoSQL数据库,提供了丰富的数据操作方法,可通过Shell交互或Java API来执行。在本节中,我们将详细介绍如何在HBase中进行表的操作、数据的增删改查以及如何使用计数器来满足高并发环境下的计数需求。
4.1 表操作
在HBase中,我们可以通过Shell交互或Java API执行多种表操作。以下是每种操作的详细示例:
-
创建表:使用
create命令创建新表,指定表名和列族等信息。
create 'my_table', 'cf1', 'cf2'
这将创建一个名为my_table的表,包含两个列族cf1和cf2。
-
删除表:先使用
disable命令禁用表,然后使用delete命令删除表。
disable 'my_table'
delete 'my_table'
这将先禁用名为my_table的表,然后删除它。
-
修改表结构:通过
alter命令修改表结构,如添加列族、修改配置等。
alter 'my_table', NAME => 'cf3'
这将向表my_table中添加一个新的列族cf3。
-
禁用和启用表:使用
disable命令禁用表,使用enable命令启用表。
disable 'my_table'
这将禁用表my_table,阻止对其进行操作。
enable 'my_table'
这将启用之前被禁用的表my_table,使其再次可用。
-
列出表:使用
list命令列出所有表格。
list
这将显示当前HBase集群中存在的所有表的列表。
4.2 数据操作
HBase提供多种数据操作方法,涵盖数据的插入、获取、扫描、更新和删除等操作。以下是这些操作的详细说明和示例:
-
插入数据:使用
put命令或Java API将数据插入到表中,指定行键、列族、列限定符和值。
put 'my_table', 'row1', 'cf1:column1', 'value1'
这将在my_table表的cf1列族的column1列中插入值为value1的数据。
-
获取数据:使用
get命令或Java API通过行键获取指定单元格的数据。
get 'my_table', 'row1'
这将获取my_table表中row1行的所有数据。
-
扫描数据:使用
scan命令或Java API执行范围扫描,可以按行、列族、列限定符进行过滤。
scan 'my_table', {COLUMNS => 'cf1'}
这将对my_table表进行扫描,只显示cf1列族的数据。
-
更新数据:使用
put命令或Java API更新已有数据的值。
put 'my_table', 'row1', 'cf1:column1', 'new_value'
这将更新my_table表中row1行的cf1列族的column1列的值为new_value。
-
删除数据:使用
delete命令或Java API删除指定单元格或行的数据。
delete 'my_table', 'row1', 'cf1:column1'
这将删除my_table表中row1行的cf1列族的column1列数据。
4.3 计数器
计数器是HBase中用于高并发环境下计数需求的一种特殊数据类型。在许多应用中,需要对某些数据进行实时的增减操作,如用户积分、库存数量、点击次数等。在这些场景下,计数器能够提供一种高效且原子的方式来管理这些计数值。
在HBase中,计数器是通过incrementColumnValue方法来实现的,它允许您原子地对指定单元格中的值进行增加或减少操作。通过指定行键、列族、列限定符以及要增加或减少的值,HBase能够确保计数操作的原子性和数据一致性,即使在高并发的情况下也能保持正确性。
以下是一个具体的计数器操作示例:
假设我们有一个HBase表名为user_scores,其中包含了用户的积分信息。表结构如下:
- 表名:user_scores
- 列族:cf
- 列限定符:score
现在,我们想要为特定用户增加积分。可以使用以下命令来执行计数器操作:
# 假设已经连接到HBase并选择了相应的表
# 定义行键和列族、列限定符
row_key = 'user123'
column_family = 'cf'
column_qualifier = 'score'
# 执行计数器操作,增加1个计数单位
incr 'user_scores', row_key, column_family:column_qualifier, 1
相应java代码如下:
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Increment;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
// 假设已经建立了HBase连接和获取了Table实例
Table table = connection.getTable(TableName.valueOf("user_scores"));
// 定义计数器操作
Increment increment = new Increment(Bytes.toBytes("user123")); // 指定行键
increment.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("score"), 1L); // 列族、列限定符、增加的值
// 执行计数器操作
table.increment(increment);
// 关闭连接等操作
table.close();
在这个示例中,我们针对行键为user123的用户,在user_scores表的cf列族下的score列执行了一个增加操作,增加了1个计数单位。无论何时调用这个操作,HBase都会确保原子性,从而避免了并发计数问题。
这个示例演示了如何使用计数器来管理分布式环境下的高并发计数需求,保证了数据的准确性和一致性。
通过上述数据操作方法,我们可以轻松地在HBase中进行表的管理、数据的操作,并满足高并发计数需求。
5. 数据模型与架构
数据模型_Hbase 中文文档
HBase架构上分为HMaster和多个RegionServer。HMaster负责监控RegionServer,处理DDL操作。RegionServer用于实际存储数据,负责处理DML操作。此外还有Zookeeper用于状态维护。
HBase中核心概念包括:Table 表,Row Key行键,Column Family列族,Column Qualifier列限定词,Timestamp时间戳,Cell单元格。行键和列组成唯一索引,按行键的字典序存储。列族在表定义时确定,列限定词可以动态增删。时间戳用于版本控制。
5.1 HBase系统架构

注意:请点击图像以查看清晰的架构图!
HBase的系统架构是分布式数据库的核心,它由多个组件协同工作以实现高性能的数据存储和查询。在这一节中,我们将深入探讨HBase的系统架构,介绍关键组件的作用和相互关系。
5.1.1 HBase组件概览

注意:请点击图像以查看清晰的视图!
HBase的系统架构主要由以下几个核心组件组成:
HMaster:
HMaster是HBase集群的“大脑”,负责管理和协调整个集群的元数据信息,如表的结构和Region分布。
- 接收客户端的DDL操作(如创建表、修改表结构)并将其转化为对应的RegionServer操作。
- 维护集群的元数据信息
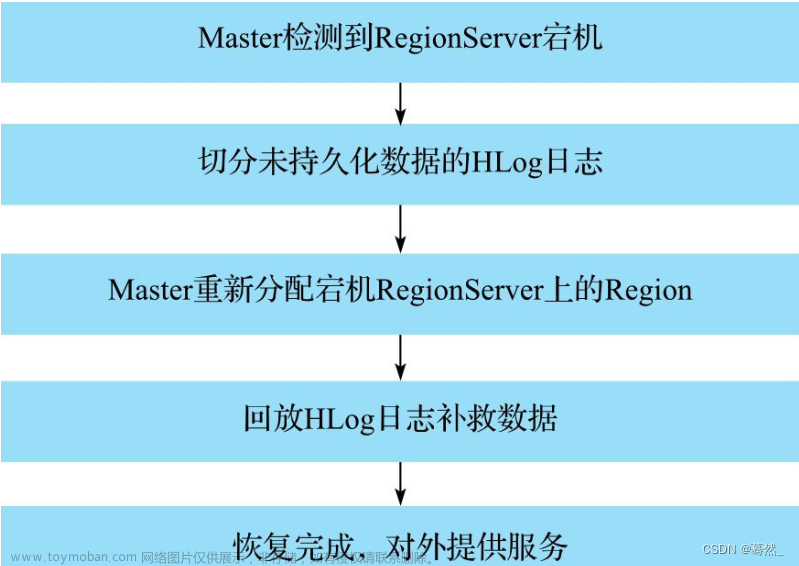
- 发现失效的Region,并将失效的Region分配到正常的HRegionServer上
RegionServer:
RegionServer是HBase集群的工作节点,负责实际的数据存储和查询操作。
每个RegionServer负责管理多个Region,每个Region又代表了表中的一部分数据。
RegionServer负责处理客户端的DML操作(如增删改查)以及Region的负载均衡和自动分裂。
Zookeeper:
Zookeeper是分布式协调服务,HBase使用它来管理集群中各个组件的状态信息和配置信息。HBase通过Zookeeper来协调HMaster的选举、RegionServer的注册和元数据的分布。
HDFS:
HDFS(Hadoop分布式文件系统)是HBase的底层存储层,它用于持久化存储表数据和元数据。HBase的数据以HDFS文件的形式存储在数据节点上,通过HBase提供的读写接口进行访问。
5.1.2 组件关系与协作

注意:请点击图像以查看清晰的视图!
HBase的组件之间通过复杂的协作实现数据的存储和查询。以下是这些组件的关系和协作过程的简要描述:
- 客户端向HMaster发送DDL操作(如创建表),HMaster将元数据信息存储在Zookeeper中,同时通知RegionServer更新元数据。
- 客户端向RegionServer发送DML操作,RegionServer根据操作类型执行相应的操作。对于写入操作,RegionServer将数据写入内存(MemStore),并定期刷新到磁盘。
- 当一个Region的MemStore大小达到阈值时,RegionServer将MemStore中的数据写入HDFS中的StoreFile,并创建新的MemStore。如果Region的StoreFile数量达到一定数量,Region会被自动分裂成两个Region,以保证数据的均衡和高效查询。
- 客户端发送查询请求到RegionServer,RegionServer从StoreFile和MemStore中检索数据,并返回结果给客户端。
- 当RegionServer发生故障或新增Region时,Zookeeper将通知其他组件,并进行相应的处理,如选举新的HMaster。
通过这些组件的协作,HBase实现了高可用性、分布式存储和实时随机访问等特性。深入理解HBase的系统架构,有助于您更好地优化配置和调优性能,以满足各种应用场景的需求。接下来,我们将深入解释HBase的核心概念,为您打下更坚实的基础。
5.2 核心概念解析
在HBase中,有一些核心概念是您必须理解的,它们构成了数据存储和访问的基础。在这一节中,我们将详细解释这些核心概念,帮助您更好地理解HBase的工作原理。


5.2.1 Table
在HBase中,数据被组织成一系列的表。每个表包含多行数据,每行数据通过一个唯一的RowKey进行标识。表在HBase中的结构是动态的,您可以在任何时候添加列族或列,而无需事先定义表的结构。表通常用于存储具有相同结构的数据。
5.2.2 RowKey
RowKey是唯一标识表中一行数据的关键字。它是一个字节数组,可以是任何数据类型。RowKey的设计非常重要,因为它直接影响了数据的分布和查询性能。较好的RowKey设计可以实现数据的均衡存储和高效的查询。
5.2.3 Column Family
Column Family(列族)是表中的一组相关列的集合。每个列族都有一个名称,列族内部的列可以动态地添加。在HBase中,列族是数据的物理存储单元,所有属于同一列族的数据存储在一起,以实现更高的存储和查询效率。
5.2.4 Column Qualifier
Column Qualifier(列限定符)是指定列族中的具体列的名称。它是一个字节数组,用于标识列族内的不同列。通过组合Column Family和Column Qualifier,您可以唯一确定表中的一个单元格(Cell)。
5.2.5 Cell
Cell是HBase中最小的数据单元,存储着实际的数据值和对应的时间戳。每个Cell由RowKey、Column Family、Column Qualifier和Timestamp组成。在表中,每个单元格的唯一标识是由RowKey、Column Family和Column Qualifier组合而成的。
5.2.6 Timestamp
Timestamp是Cell的一个重要属性,用于标识数据的版本。HBase支持多版本数据存储,每个Cell可以有多个不同时间戳的版本。通过Timestamp,您可以查询和获取不同时间点的数据版本。
5.2.7 Region
Region是HBase中数据的分布单元。每个表可以被划分成多个Region,每个Region由一系列的连续行组成。Region是HBase实现分布式存储和负载均衡的关键。
通过理解这些核心概念,您将能够更好地设计表结构、优化数据访问和查询,并为后续的数据操作打下坚实的基础。接下来,我们将深入探讨HBase的数据操作,帮助您了解如何在HBase中进行数据的增删改查。
5.3 内部实现原理
HBase的内部实现原理是其高性能和可扩展性的关键。在这一节中,我们将揭示HBase的数据存储格式、压缩算法、缓存机制等内部实现原理,帮助您深入理解其工作机制。
5.3.1 HBase读数据流程

注意:请点击图像以查看清晰的视图!
HBase是一个分布式、面向列的NoSQL数据库系统,针对海量数据的随机读取提供了高性能。以下是HBase读取数据的详细流程:
-
数据定位和访问:
当客户端需要读取数据时,首先根据数据的行键进行哈希计算,以确定数据位于哪个Region。然后,客户端通过HBase的Master节点获取表的元数据,包括表的分区信息和RegionServer的位置。 -
与RegionServer通信:
客户端会根据元数据信息,与负责该数据区域的RegionServer建立连接。这个连接将用于请求数据以及接收响应。 -
MemStore和StoreFile查询:
在RegionServer上,数据首先会被查询MemStore。如果要查找的数据在MemStore中,就直接从内存中读取。如果数据不在MemStore中,HBase会按照时间顺序查询StoreFile,找到合适的StoreFile进行读取。 -
Block Cache利用:
如果数据在StoreFile中,HBase会将StoreFile按照块(Block)进行读取。在读取的过程中,HBase会首先检查Block Cache,这是一个位于内存中的缓存,用于存储最常用的数据块,以提高读取性能。如果所需数据块在Block Cache中存在,就可以直接从缓存中读取,而不需要去磁盘上读取StoreFile。 -
数据过滤和组装:
一旦数据块被读取,HBase会根据请求中指定的列族和列限定符,对数据进行过滤,只返回需要的部分数据。然后,数据会被组装成适当的格式,通常是键值对的形式。 -
返回数据给客户端:
最后,RegionServer会将请求的数据返回给客户端。客户端可以使用这些数据进行进一步的处理和分析。
HBase的读取流程在访问内存中的MemStore、利用Block Cache、查询StoreFile和数据过滤等环节中充分利用了缓存和索引,以提供高效的随机读取性能。这种架构使得HBase适用于大规模数据集的实时查询需求。
5.3.2 HBase写数据流程

注意:请点击图像以查看清晰的视图!
HBase是一个基于Hadoop分布式文件系统(HDFS)的列式存储系统,专为处理大规模的稀疏数据集而设计。它提供了高效的随机读写能力,并且在写入数据时有一套独特的内部原理和流程。
以下是HBase写入数据的内部原理和流程:
-
写入流程初始化:
当客户端想要写入数据时,首先要与HBase的Master节点通信以获取表的元数据,包括表的结构、分区信息等。然后,客户端会与HBase的RegionServer建立连接,准备进行写入操作。 -
写前准备:
在写入之前,HBase会对要写入的数据进行预处理,如生成写入操作的日志(Write Ahead Log,WAL)以确保数据的持久性和恢复能力。 -
数据分布和定位:
HBase的表会被水平分割为多个Region,每个Region负责管理一定范围的行键数据。在写入数据时,HBase会根据行键的哈希值来定位数据所在的Region。 -
写入MemStore:
当确定了要写入的Region后,数据首先会被写入到该Region的内存存储区域,称为MemStore。MemStore以排序的方式保存数据,新的数据会被插入到适当的位置,以便后续的读取和写入操作更高效。 -
持久化到HLog:
写入MemStore后,数据同时会被写入到HLog中,作为持久化的写入日志。这样可以确保即使RegionServer发生故障,数据也可以从HLog中进行恢复。 -
MemStore刷写:
当MemStore中的数据达到一定的大小阈值时,HBase会触发MemStore的刷写操作。这将会将MemStore中的数据写入到HDFS中的一个临时存储文件,称为StoreFile。 -
Compaction:
随着时间的推移,多个StoreFile会不断产生。为了维护数据的连续性和提高查询性能,HBase会定期进行Compaction操作,将多个StoreFile合并为一个较大的文件,同时删除过期或重复的数据。 -
数据持久化:
在Compaction操作完成后,生成的新的StoreFile会被重命名并移动到最终的存储位置。这样,数据就持久化到了HDFS中。 -
Acknowledgment:
一旦数据写入成功并持久化,RegionServer会向客户端发送确认消息,表示数据已成功写入。
总的来说,HBase的写入过程涉及了内存中的MemStore、持久化的HLog、StoreFile的生成和Compaction等步骤,保证了数据的持久性和高效性能。这个过程充分利用了分布式存储和列式存储的优势,使得HBase在大规模数据处理中具有出色的表现。
5.3.3 HBase的flush(刷写)及compact(合并)机制
HBase的Flush(刷写)和Compaction(合并)是维护数据一致性、减少存储空间占用以及提高读取性能的重要机制。以下是对HBase的Flush和Compaction机制的详细介绍:
Flush(刷写)机制:
Flush是指将内存中的数据写入到持久化存储(HDFS)的过程。在HBase中,数据首先被写入MemStore,这是位于RegionServer内存中的排序数据结构,用于提高写入性能。然而,MemStore的数据在写入过程中并不直接写入HDFS,而是在达到一定条件后进行刷写(Flush)操作,将数据持久化到磁盘上的StoreFile中。
Flush机制的过程如下:
- MemStore刷写触发:当MemStore中的数据达到一定的大小阈值(通过配置参数指定),或者在指定的时间间隔内,HBase会触发Flush操作。
- 生成StoreFile:在Flush时,MemStore中的数据会被写入一个新的StoreFile中,而不是直接写入HDFS。这个StoreFile是一个持久化的数据文件,按照键的顺序排序。
- StoreFile写入HDFS:生成的StoreFile会首先写入HBase的HLog(Write Ahead Log),以保证数据的持久性。然后,StoreFile会被移动到HDFS中的对应Region的数据目录下,变为持久化存储。
Flush触发配置:
当memstore的大小超过这个值的时候,会flush到磁盘,默认为128M
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
当memstore中的数据时间超过1小时,会flush到磁盘
<property>
<name>hbase.regionserver.optionalcacheflushinterval</name>
<value>3600000</value>
</property>
HregionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
手动flush
flush tableName
Compaction(合并)机制:
Compaction是指合并StoreFile以优化数据存储、提高查询性能和删除过期数据的过程。由于HBase的写入操作会产生多个StoreFile,而且数据可能存在多个版本,为了维护数据的连续性和删除过期数据,HBase会定期进行Compaction。
HBase支持两种类型的Compaction:小规模的Min Compaction和大规模的Major Compaction。
- Min Compaction:也称为较小规模的Compaction,它会合并几个相邻的StoreFile,但不会合并所有的StoreFile。这有助于减少数据碎片,提高查询性能。
- Major Compaction:也称为较大规模的Compaction,它会合并一个Region内的所有StoreFile,删除已删除的数据、删除过期数据以及合并相同行键的不同版本。Major Compaction可以彻底优化数据存储,减少存储空间占用,并提高读取性能。
Compaction机制的过程如下:
- 选择合并的StoreFile:HBase会选择一些StoreFile来合并,通常是相邻的或有重叠行键范围的文件。
- 合并过程:在Compaction过程中,HBase会合并选定的StoreFile,并生成一个新的StoreFile。在这个过程中,重复的数据会被合并,过期数据会被删除,不同版本的数据会被合并。
- 生成新StoreFile:合并后生成的新StoreFile会被写入HDFS,并取代旧的StoreFile。
- 删除旧StoreFile:合并后的新StoreFile生成后,原来的旧StoreFile会被删除,释放存储空间。
Flush和Compaction机制的配合使用,确保了HBase数据的一致性、可靠性以及读取性能。
5.3.4 缓存机制
HBase的缓存机制是为了提高读取性能和降低对底层存储的访问频率而设计的。HBase使用了两种主要的缓存机制:Block Cache(块缓存)和MemStore Heap Cache(MemStore堆缓存)。以下是对这两种缓存机制的详细介绍:
1. Block Cache(块缓存):
Block Cache是HBase的主要缓存机制之一,用于缓存存储在HDFS上的StoreFile中的数据块。StoreFile通常被分成固定大小的数据块,也称为块(Block),每个块的大小通常为64KB。
Block Cache工作的基本原理如下:
- 缓存策略:Block Cache使用LRU(Least Recently Used)策略来管理缓存中的数据块。最近被访问过的块会被保留在缓存中,而较早被访问的块则可能被替换出缓存。
- 块粒度:Block Cache以块为单位进行缓存,这样在读取数据时,可以在块级别上进行缓存命中,从而提高读取性能。
- 缓存位置:Block Cache位于每个RegionServer的内存中,用于缓存该RegionServer负责的所有Region的数据块。
- 缓存适用性:Block Cache适用于频繁被查询的数据,如热点数据。由于数据在内存中缓存,读取性能显著提高。
2. MemStore Heap Cache(MemStore堆缓存):
MemStore Heap Cache是用于缓存处于内存中的MemStore数据的机制。当数据被写入HBase时,首先被写入MemStore,然后会在Flush之前被缓存在MemStore Heap Cache中。
-
缓存目的:MemStore Heap Cache的主要目的是为了提高写入性能。由于写入到磁盘的Flush操作是相对较慢的,数据在Flush前可以在Heap Cache中缓存,这样可以减少实际写入磁盘的频率,提高写入性能。
-
Flush触发:当MemStore Heap Cache达到一定大小阈值或者定时间隔到达时,会触发Flush操作,将Heap Cache中的数据刷写到HDFS中的StoreFile中。
HBase的缓存机制在读取和写入方面都起到了关键作用。Block Cache提供了高效的读取缓存,而MemStore Heap Cache则有助于提高写入性能。综合使用这些缓存机制,HBase能够在大规模数据处理中取得出色的性能表现。
5.3.5 垃圾回收
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
综上所述,HBase的数据垃圾回收机制主要通过删除标记、版本删除、Minor Compaction和Major Compaction等方式来清理无效数据,减少存储空间的占用,并保持数据的一致性和可靠性。
通过了解这些内部实现原理,您将能够更好地理解HBase的性能特点和工作机制。这对于优化配置、调优性能以及处理各种应用场景的需求都非常有帮助。接下来,我们将深入介绍HBase的数据操作,为您提供丰富的操作示例和指导。
6. HBase进阶操作
在本章中,我们将深入探讨HBase的进阶操作,包括使用过滤器进行读取控制、数据的高效导入方式,以及如何结合MapReduce进行复杂的分布式计算。
当涉及HBase的进阶操作时,包括了一些更高级和复杂的用例。以下是一些进阶操作的详细说明和具体操作示例:
6.1 高级用例
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
6.2 过滤器的使用
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
6.3 数据导入方式
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
在下一章节中,我们将介绍如何通过Java客户端API进行HBase应用开发,以及一些优化和最佳实践。这将帮助您更好地利用HBase构建应用程序。
7. 客户端开发
在本章中,我们将详细介绍如何使用HBase的Java客户端API进行应用开发。您需要设置依赖配置,并提供完整可运行的Java代码示例。
7.1 依赖配置
首先,您需要在项目中添加HBase的Java客户端API依赖。如果使用Maven作为项目构建工具,在pom.xml文件中添加以下依赖配置:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.7</version> <!-- 请根据您的HBase版本进行调整 -->
</dependency>
7.2 用户信息示例
下面是一个完整的可运行的Java代码示例,演示了如何使用HBase的Java客户端API连接HBase集群、创建用户信息表、插入用户数据、查询用户数据以及异常处理。在这个示例中,我们提供了配置信息。
- 初始化客户端
public class HbaseClientDemo {
Configuration conf=null;
Connection conn=null;
HBaseAdmin admin =null;
@Before
public void init () throws IOException {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","linux121,linux122");
conf.set("hbase.zookeeper.property.clientPort","2181");
conn = ConnectionFactory.createConnection(conf);
}
public void destroy(){
if(admin!=null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(conn !=null){
try {
conn.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
- 创建表
@Test
public void createTable() throws IOException {
admin = (HBaseAdmin) conn.getAdmin();
//创建表描述器
HTableDescriptor teacher = new HTableDescriptor(TableName.valueOf("teacher"));
//设置列族描述器
teacher.addFamily(new HColumnDescriptor("info"));
//执行创建操作
admin.createTable(teacher);
System.out.println("teacher表创建成功!!");
}
- 插入数据
//插入一条数据
@Test
public void putData() throws IOException {
//获取一个表对象
Table t = conn.getTable(TableName.valueOf("teacher"));
//设定rowkey
Put put = new Put(Bytes.toBytes("110"));
//列族,列,value
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("addr"), Bytes.toBytes("beijing"));
//执行插入
t.put(put);
// t.put();//可以传入list批量插入数据
//关闭table对象
t.close();
System.out.println("插入成功!!");
}
- 删除数据:
//删除一条数据
@Test
public void deleteData() throws IOException {
//需要获取一个table对象
final Table worker = conn.getTable(TableName.valueOf("worker"));
//准备delete对象
final Delete delete = new Delete(Bytes.toBytes("110"));
//执行删除
worker.delete(delete);
//关闭table对象
worker.close();
System.out.println("删除数据成功!!");
}
- 查询某个列族数据
//查询某个列族数据
@Test
public void getDataByCF() throws IOException {
//获取表对象
HTable teacher = (HTable) conn.getTable(TableName.valueOf("teacher"));
//创建查询的get对象
Get get = new Get(Bytes.toBytes("110"));
//指定列族信息
// get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("sex"));
get.addFamily(Bytes.toBytes("info"));
//执行查询
Result res = teacher.get(get);
Cell[] cells = res.rawCells();//获取改行的所有cell对象
for (Cell cell : cells) {
//通过cell获取rowkey,cf,column,value
String cf = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
String rowkey = Bytes.toString(CellUtil.cloneRow(cell));
System.out.println(rowkey + "----" + cf + "---" + column + "---" + value);
}
teacher.close();//关闭表对象资源
}
- 通过Scan全表扫描
/**
* 全表扫描
*/
@Test
public void scanAllData() throws IOException {
HTable teacher = (HTable) conn.getTable(TableName.valueOf("teacher"));
Scan scan = new Scan();
ResultScanner resultScanner = teacher.getScanner(scan);
for (Result result : resultScanner) {
Cell[] cells = result.rawCells();//获取改行的所有cell对象
for (Cell cell : cells) {
//通过cell获取rowkey,cf,column,value
String cf = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
String rowkey = Bytes.toString(CellUtil.cloneRow(cell));
System.out.println(rowkey + "----" + cf + "--" + column + "---" + value);
}
}
teacher.close();
}
- 通过startRowKey和endRowKey进行扫描
/**
* 通过startRowKey和endRowKey进行扫描查询
*/
@Test
public void scanRowKey() throws IOException {
HTable teacher = (HTable) conn.getTable(TableName.valueOf("teacher"));
Scan scan = new Scan();
scan.setStartRow("0001".getBytes());
scan.setStopRow("2".getBytes());
ResultScanner resultScanner = teacher.getScanner(scan);
for (Result result : resultScanner) {
Cell[] cells = result.rawCells();//获取改行的所有cell对象
for (Cell cell : cells) {
//通过cell获取rowkey,cf,column,value
String cf = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
String rowkey = Bytes.toString(CellUtil.cloneRow(cell));
System.out.println(rowkey + "----" + cf + "--" + column + "---" + value);
}
}
teacher.close();
}
7.3 SpringBoot整合HBase
在Spring Boot中整合HBase,您可以使用Spring Data Hadoop项目提供的HBase支持。以下是演示如何在Spring Boot中整合HBase的步骤:
1. 创建Spring Boot项目:
首先,创建一个新的Spring Boot项目。您可以使用Spring Initializr(https://start.spring.io/)来快速生成一个基本的Spring Boot项目,确保选择所需的依赖项,例如Web、HBase、和Lombok(可选)。
2. 配置application.properties:
在src/main/resources目录下的application.properties文件中,添加HBase和ZooKeeper的配置信息:
# HBase configuration
spring.data.hbase.quorum=zkHost1,zkHost2,zkHost3 # 替换为您的ZooKeeper主机名
spring.data.hbase.zk-port=2181
spring.data.hbase.zk-znode-parent=/hbase
spring.data.hbase.rootdir=hdfs://localhost:9000/hbase
# HBase auto start
spring.data.hbase.auto-startup=true
3. 创建HBase实体类:
创建一个Java类表示HBase表的实体。使用@Table注解指定表的名称,使用@Row注解表示行键,使用@Column注解表示列。
import org.springframework.data.annotation.Id;
import org.springframework.data.hadoop.hbase.RowKey;
import org.springframework.data.hadoop.hbase.Table;
@Table("users")
public class User {
@Id
@RowKey
private String id;
@Column("userInfo:name")
private String name;
@Column("userInfo:age")
private String age;
// Getters and setters
}
4. 创建HBase Repository:
创建一个HBase的Repository接口,继承自org.springframework.data.repository.CrudRepository。您可以使用继承的方法来实现基本的CRUD操作。
import org.springframework.data.repository.CrudRepository;
public interface UserRepository extends CrudRepository<User, String> {
}
5. 创建服务层:
创建一个服务层,可以将Repository注入,然后在应用程序中使用它来访问HBase数据。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserService {
private final UserRepository userRepository;
@Autowired
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public void saveUser(User user) {
userRepository.save(user);
}
public User getUserById(String id) {
return userRepository.findById(id).orElse(null);
}
// 其他业务逻辑...
}
6. 创建控制器:
创建一个控制器类,处理HTTP请求。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/users")
public class UserController {
private final UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
@PostMapping
public void addUser(@RequestBody User user) {
userService.saveUser(user);
}
@GetMapping("/{id}")
public User getUser(@PathVariable String id) {
return userService.getUserById(id);
}
// 其他请求处理...
}
7. 运行应用程序:
运行Spring Boot应用程序,您可以使用内置的Tomcat容器。然后,通过HTTP请求访问控制器中定义的端点。
综上所述,您现在已经在Spring Boot中整合了HBase。通过使用Spring Data Hadoop的HBase支持,您可以更轻松地在Spring Boot应用程序中进行HBase操作,而无需处理底层的连接和配置细节。
接下来,在下一章中,我们将深入讨论如何优化HBase的性能,以及一些常见的应用案例。
8. HBase优化
在本章中,我们将深入探讨如何优化HBase的性能,以确保您的应用在处理大规模数据时能够保持高效。HBase优化可以从多个方面着手,让我们逐个进行介绍。
8.1 Rowkey设计
在HBase中,RowKey的设计非常重要,因为它直接影响了数据的存储、访问和性能。一个好的RowKey设计可以提高查询效率、降低数据倾斜问题,并且有助于优化HBase的性能。以下是一些设计RowKey的原则和优化建议:
1. 唯一性: RowKey必须是唯一的,以确保每个行都能被正确标识。通常可以使用时间戳、UUID、业务相关的唯一标识等作为RowKey的一部分。
2. 散列分布: 良好的RowKey设计应该在HBase表中实现均匀的分布。这有助于避免热点数据,提高负载均衡,以及降低数据倾斜问题。一种常见的方法是使用散列函数对RowKey进行哈希,以确保数据分布更加均匀。
3. 数据局部性: 将相关的数据存储在相邻的行中,以便在扫描范围查询时能够最大程度地减少磁盘访问。这可以通过将相似的数据存储在RowKey的相同前缀下来实现。例如,对于存储用户交易记录的表,可以使用用户ID作为前缀,将相同用户的交易记录存储在相邻的行中。
4. 最小化字节长度: 较短的RowKey可以减少存储空间和IO开销。但是,不要过度追求短长度而导致RowKey不可读,应该在可读性和长度之间做出权衡。
5. 避免频繁变更: RowKey设计后,尽量避免频繁地修改,因为修改RowKey会导致数据在HBase内部的重新分布。频繁变更可能会影响性能和数据局部性。
6. 考虑查询模式: 根据您的查询需求,设计RowKey以便支持常见的查询模式。如果经常需要根据时间范围查询数据,可以将时间戳作为RowKey的一部分。
7. 避免顺序写热点: 如果RowKey的设计使得新数据总是写入到相同区域,可能会导致顺序写热点,影响性能。这可以通过添加随机性到RowKey中,或者使用散列分布来缓解。
8. 使用字节编码: 如果RowKey包含数字或日期等数据,可以考虑使用适当的字节编码,以便保持排序和比较的正确性。
9. 行分区: 对于大型表,可以考虑将表按行分区,将数据分散到不同的RegionServer上。这可以通过在RowKey中添加分区标识来实现。
10. 测试和优化: 设计好的RowKey应该经过测试,以确保它在实际场景中表现良好。在设计之后,可以通过性能测试来验证并进行优化。
当设计HBase表的RowKey时,可以根据上述原则和建议来制定策略。
以下是一些示例,展示如何基于不同的情境来设计RowKey,并说明如何在Java中实现。
1. 唯一性和散列分布示例:
在这个示例中,我们使用UUID作为RowKey的一部分,以确保唯一性。同时,我们将RowKey哈希,以实现更均匀的数据分布。
import org.apache.hadoop.hbase.util.Bytes;
import java.util.UUID;
public class RowKeyExample {
public static byte[] generateRowKey() {
UUID uuid = UUID.randomUUID();
int hash = uuid.hashCode();
return Bytes.toBytes(hash + "-" + uuid.toString());
}
public static void main(String[] args) {
byte[] rowKey = generateRowKey();
System.out.println("Generated RowKey: " + Bytes.toString(rowKey));
}
}
2. 数据局部性示例:
在这个示例中,我们使用用户ID作为RowKey的前缀,将相同用户的数据存储在相邻的行中。
import org.apache.hadoop.hbase.util.Bytes;
public class UserRowKeyExample {
public static byte[] generateRowKey(String userId) {
return Bytes.toBytes(userId + "-" + System.currentTimeMillis());
}
public static void main(String[] args) {
String userId = "user123";
byte[] rowKey = generateRowKey(userId);
System.out.println("Generated RowKey: " + Bytes.toString(rowKey));
}
}
3. 避免顺序写热点示例:
在这个示例中,我们将时间戳添加到RowKey中,以避免顺序写热点问题。
import org.apache.hadoop.hbase.util.Bytes;
public class AvoidHotspotRowKeyExample {
public static byte[] generateRowKey() {
long timestamp = System.currentTimeMillis();
int randomValue = (int) (Math.random() * 1000); // 添加随机值
return Bytes.toBytes(timestamp + "-" + randomValue);
}
public static void main(String[] args) {
byte[] rowKey = generateRowKey();
System.out.println("Generated RowKey: " + Bytes.toString(rowKey));
}
}
在实际应用中,RowKey的设计取决于您的业务需求和查询模式。上述示例只是为了演示如何基于不同情境来设计RowKey,并不是绝对的最佳实践。您应该根据具体的情况进行定制化设计,进行测试和优化,以获得最佳的性能和数据分布效果。
总之,HBase的RowKey设计是一个需要仔细考虑的重要决策,它直接影响了数据的存储和查询效率。根据具体的业务需求、查询模式和性能要求,您可以选择合适的RowKey设计策略。
8.2 内存优化
合理配置内存参数是优化HBase性能的重要步骤。以下是关于内存优化方面的扩展说明,主要集中在MemStore优化和块缓存优化。
1. MemStore优化:
MemStore是HBase用于缓存写入数据的内存区域,过多的数据积累可能导致写入性能下降。以下是一些优化建议:
-
控制刷新频率:
hbase.hregion.memstore.flush.size参数决定了当MemStore中的数据大小达到一定阈值时,会触发数据的刷新到HFile。通过适当调整这个阈值,可以控制刷新的频率,以避免过于频繁的刷新操作。 -
合理设置阻塞系数:
hbase.hregion.memstore.block.multiplier参数控制了MemStore的大小,它会根据内存分配来计算MemStore的阻塞大小。根据系统的可用内存,您可以适当调整这个参数,以更好地利用可用内存。如果系统内存充足,可以增加阻塞系数,提高MemStore的大小。
2. 块缓存优化:
块缓存用于缓存HFile中的数据块,从而加速读取操作。以下是一些块缓存优化的建议:
-
根据表的读取模式进行配置:
hbase.regionserver.global.memstore.size参数控制了块缓存和MemStore的总内存使用。根据您的表的读取模式,可以调整这个参数来更好地分配内存资源。如果表的读取频率高,可以增加块缓存的比例,减少MemStore的占用。 -
使用
hbase.regionserver.global.memstore.size.lower.limit: 这个参数可以设置一个下限,确保至少有一定数量的内存分配给块缓存。这有助于避免当MemStore数据较少时,块缓存占用过多的内存资源。
在进行内存优化时,建议进行实验和性能测试,以便根据实际情况找到最佳的内存配置。同时,还要考虑系统的其他资源使用情况,以避免因为过多的内存分配而影响其他服务的正常运行。
8.3 压缩算法选择
在HBase中,选择适合的压缩算法可以显著降低存储成本、提高数据传输效率,并且影响整体的性能。以下是关于压缩算法选择的扩展说明:
1. Snappy压缩算法:
- 优点: Snappy是一种快速的压缩算法,能够在保持较高的解压速度的同时,有效地减少数据的存储空间。它特别适用于高吞吐量和低延迟的应用场景。
- 适用场景: 如果您的主要关注点是压缩速度和低延迟,可以考虑使用Snappy。它适用于对读写性能要求较高的场景,如实时分析和快速查询。
2. LZO压缩算法:
- 优点: LZO是一种高效的压缩算法,具有较快的解压速度和高压缩比。它在大数据分析场景中表现良好,尤其适用于MapReduce和Hive等作业。
- 适用场景: 如果您在大数据分析中使用HBase,可以考虑使用LZO压缩算法。它能够减少磁盘IO和网络传输,加速作业执行。
3. Gzip压缩算法:
- 优点: Gzip是一种通用的压缩算法,在压缩比方面表现良好。它可以在较小的存储空间中存储更多的数据。
- 适用场景: 如果您的主要关注点是压缩比率,可以考虑使用Gzip。然而,需要注意的是,Gzip的压缩和解压缩速度相对较慢,可能会影响读写性能。
在选择压缩算法时,需要综合考虑数据的特点、访问模式和硬件条件。您还可以根据不同的列族或表来选择不同的压缩算法,以满足不同的需求。在配置压缩算法时,您可以使用HBase的列族级别的参数设置,例如:
<property>
<name>hbase.columnfamily.familyName.COMPRESSION</name>
<value>SNAPPY</value>
</property>
在实际应用中,建议进行性能测试,观察不同压缩算法在您的特定场景中的表现,并根据测试结果做出最佳选择。
8.4 使用Bloom Filter
Bloom Filter是一种基于哈希的数据结构,用于快速判断一个元素是否存在于一个集合中。在HBase中,Bloom Filter可以用于提高读取效率,减少不必要的磁盘IO。通过在某些列族上启用Bloom Filter,可以在查询时减少不必要的磁盘寻址,从而提升性能。
Bloom Filter的工作原理:
Bloom Filter使用一系列哈希函数将元素映射到一个位数组中。当要判断一个元素是否存在时,会对该元素进行相同的哈希计算,并检查位数组中对应的位是否都为1。如果有任何一个位为0,则元素肯定不存在;如果所有位都为1,则元素可能存在,但也有可能是误判。

在HBase中使用Bloom Filter:
在HBase中,可以在列族级别配置是否启用Bloom Filter。通过启用Bloom Filter,可以在查询时快速确定某行是否可能存在于HFile中,从而避免了不必要的磁盘IO。以下是配置Bloom Filter的示例:
<property>
<name>hbase.columnfamily.familyName.BLOOMFILTER</name>
<value>ROW</value>
</property>
在上述示例中,将familyName替换为实际的列族名称,将ROW替换为所需的Bloom Filter类型。在HBase中,Bloom Filter支持的类型包括ROW、ROWCOL和NONE。
适用场景:
使用Bloom Filter可以在某些列族上实现更快速的读取操作,特别是在随机读取的场景下。适用场景包括:
- 大型表中的快速查询: 当在大型表中进行查询操作时,Bloom Filter可以帮助排除掉不符合条件的行,减少磁盘IO,提高查询性能。
- 缓存查询结果: 如果您使用了查询缓存,Bloom Filter可以帮助在缓存中快速判断是否存在某行的数据,从而决定是否使用缓存结果。
注意事项:
- Bloom Filter是概率性数据结构,可能会出现误判(假阳性)。因此,它适用于那些可以接受一定误差的场景。
- 启用Bloom Filter会占用一定的内存资源,因此需要根据实际情况来权衡内存的使用。
总之,通过在HBase中启用Bloom Filter,您可以在查询操作中降低不必要的磁盘IO,提高读取效率。根据您的查询模式和性能需求,可以选择在适当的列族上启用Bloom Filter。
8.5 索引优化
在HBase中,虽然没有传统意义上的数据库索引,但您可以采用一些方法来实现类似索引的功能,以提高查询效率。以下是关于索引优化的扩展说明:
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
通过以上优化措施,您可以大幅提升HBase的性能和效率,使其更适用于处理大规模数据和高并发的应用场景。
在下一章中,我们将通过实际的应用案例,进一步展示HBase在不同领域的应用。
9. HBase应用案例
9.1 场景一:存储日志数据
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
通过以上优化策略,我们可以构建一个高效的分布式日志存储和分析平台。该平台不仅能够存储海量的访问日志数据,还能够实现实时分析和查询,为用户行为调优提供支持。同时,利用HBase的高扩展性,我们可以轻松应对不断增长的数据量。
9.2 场景二:时序数据存储
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
通过以上优化策略,HBase可以支持高吞吐的时序数据写入,同时能够进行复杂的实时分析,满足电信计费、监控数据分析等需要。HBase的分布式特性和扩展性,使其成为时序数据存储和分析的有力工具。
10. 与生态系统集成
HBase作为一个强大的分布式NoSQL数据库,可以与大数据生态系统中的其他框架进行紧密集成,构建完整的大数据处理方案。在本章中,我们将介绍如何将HBase与Hadoop、Hive和Spark等框架进行集成,发挥它们的优势,实现更强大的数据处理能力。
10.1 HBase与MapReduce集成
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
综上所述,通过HBase与MapReduce的结合,可以实现强大的分布式计算能力,用于数据聚合、连接操作、数据清洗等复杂的分布式计算任务。
10.2 HBase与Hive集成
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
通过执行这些查询,您可以在Hive中分析和处理HBase中的数据,无需编写复杂的Java代码。
通过HBase与Hive的集成,您可以充分发挥Hive的强大分析能力,同时利用HBase的高性能存储,为数据分析和报告生成提供了更加灵活和便捷的方式。
10.3 HBase与Spark集成
…
由于字数限制,此处省略
完整内容,请参见《大数据HBase学习圣经》,pdf 找尼恩获取
通过以上集成示例,您可以充分发挥HBase与大数据生态系统的协同作用,构建出更强大的数据处理和分析方案。
在最后一章中,我们将对整个教程进行回顾,并为您提供进一步深入学习和实践的建议。
11. 总结
通过本教程,相信大家已经对HBase的基本概念、架构、安装配置、数据模型、操作API以及优化等方面有了一定的了解。HBase作为一个强大的分布式、可扩展的NoSQL数据库,为处理大规模数据提供了重要的支持。
当然,要深入掌握HBase,还需要在实际项目中不断实践和优化。如果您希望继续学习更多高级主题,可以参考本教程中提供的参考资料,并在实际项目中不断积累经验。
12. 参考资料
[1] HBase中文官方文档:http://hbase.org.cn/
[2] HBase权威指南:https://book.douban.com/subject/26560706/
[3] HBase技术内幕:https://book.douban.com/subject/26649202/
说在后面
本文是《大数据Flink学习圣经》 V1版本, 是 《尼恩 大数据 面试宝典》 姊妹篇。
这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经收集了 好几百题,大量的大厂面试干货、正货 。 《尼恩 大数据 面试宝典》面试题集合, 已经变成大数据学习和面试的必读书籍。
于是,尼恩架构团队 趁热打铁,推出 《大数据Flink学习圣经》,《大数据HBASE学习圣经》(本文)
完整的pdf,可以关注尼恩的 公号【技术自由圈】取。
并且,《大数据HBASE学习圣经》、《大数据Flink学习圣经》、《尼恩 大数据 面试宝典》 都会持续迭代、不断更新,以 吸纳最新的面试题,最新版本,具体请参见 文末公号【技术自由圈】
作者介绍
一作:Andy,资深架构师, 《Java 高并发核心编程 加强版》作者之1 。
二作:尼恩,41岁资深老架构师, IT领域资深作家、著名博主。《Java 高并发核心编程 加强版 卷1、卷2、卷3》创世作者。 《K8S学习圣经》《Docker学习圣经》《Go学习圣经》等11个PDF 圣经的作者。 也是一个 资深架构导师、架构转化 导师, 成功指导了多个中级Java、高级Java转型架构师岗位, 最高的学员年薪拿到近100W。
推荐阅读
《消息推送 架构设计》
《阿里2面:你们部署多少节点?1000W并发,当如何部署?》
《美团2面:5个9高可用99.999%,如何实现?》
《网易一面:单节点2000Wtps,Kafka怎么做的?》
《字节一面:事务补偿和事务重试,关系是什么?》
《网易一面:25Wqps高吞吐写Mysql,100W数据4秒写完,如何实现?》
《亿级短视频,如何架构?》
《炸裂,靠“吹牛”过京东一面,月薪40K》
《太猛了,靠“吹牛”过顺丰一面,月薪30K》
《炸裂了…京东一面索命40问,过了就50W+》
《问麻了…阿里一面索命27问,过了就60W+》
《百度狂问3小时,大厂offer到手,小伙真狠!》
《饿了么太狠:面个高级Java,抖这多硬活、狠活》
《字节狂问一小时,小伙offer到手,太狠了!》
《收个滴滴Offer:从小伙三面经历,看看需要学点啥?》文章来源:https://www.toymoban.com/news/detail-691251.html
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓文章来源地址https://www.toymoban.com/news/detail-691251.html
到了这里,关于大数据HBase学习圣经:一本书实现HBase学习自由的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!