关于AIGC的问题跳转
- 什么是AIGC?
- AIGC基于什么技术实现?
- 什么是向量库?
- 什么是数据集?
- 各领域成熟的AIGC产品?
本篇文章内容80%来自一个名为AIGC领域专家的GPT,由我进行整理和优化其输出的内容。
他的Prompt设置为你拥有多年的AIGC领域经验,请以AIGC领域专家的角度尽可能全面的回答我的相关问题。
本文的文章名称也是根据它的提议。


什么是AIGC?
AIGC是人工智能生成内容(Artificial Intelligence Generated Content)的缩写。它指的是使用人工智能技术生成各种形式的内容,如文章、音乐、图像等。AIGC利用机器学习和自然语言处理等技术,通过模型训练和大规模数据分析来创造新的内容。
在过去几年中,随着深度学习和强化学习算法的发展,AIGC已经取得了重要进展。例如,OpenAI公司开发的GPT(Generative Pre-trained Transformer)系列模型就是一个著名的AIGC应用之一,在文本生成领域表现出色。
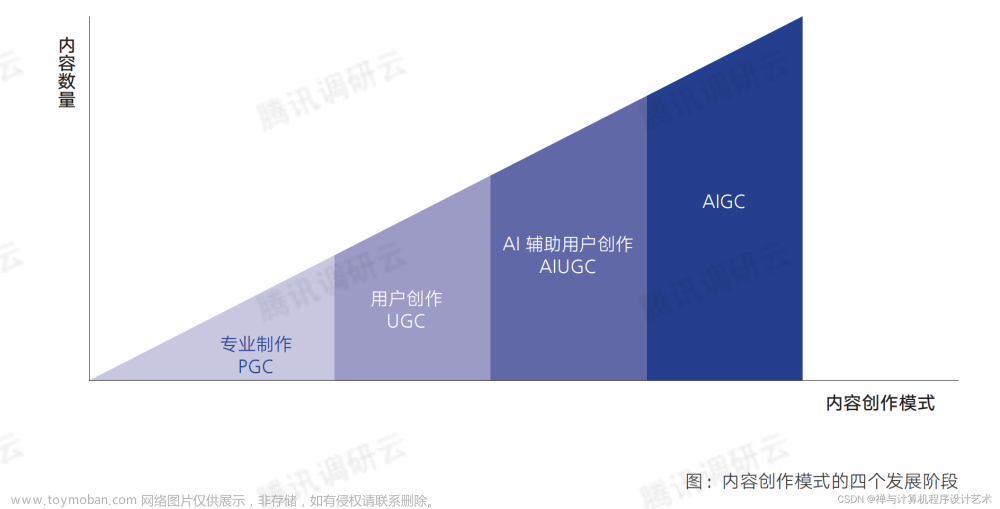
AIGC之前,还有UGC和PGC
| Generated Content Type | PGC(Professional Generated Content) | UGC(User Generated Content) | AIGC(Artificial Intelligence Generated Content) |
|---|---|---|---|
| 名称 | 专家生成内容 | 用户生成内容 | 人工智能生成内容 |
| 代表产物 | 专业机构、专业人士 | 社交、视频平台(如微博、b站) | GPT |
| 显著特点 | 权威性、专业性、高质量 | 广泛性、多样性 | 较高的准确性、结合PGC、UGC的部分特点 |
不得不承认,AIGC的出现,将会对PGC和UGC进行不同程度的冲击。
AIGC基于什么技术实现?
- 机器学习(Machine Learning):机器学习是让计算机通过数据和经验不断改进性能的一种方法。在AIGC中,通过使用大量的训练数据来建立模型,并利用这些模型对新数据进行预测或生成内容。
- 自然语言处理(Natural Language Processing,NLP):自然语言处理是研究计算机如何理解、分析和生成人类语言的领域。在AIGC中,NLP技术被用于文本理解、情感分析、语义推理以及生成具有上下文逻辑和流畅度的自然语言内容。
- 深度学习(Deep Learning):深度学习是一种基于神经网络结构的机器学习方法。它可以从大规模数据中提取复杂特征,并进行高级抽象和决策。在AIGC中,深度学习技术被广泛应用于图像识别、音频合成以及自然语言处理等任务。
- 图像识别与处理技术:图像识别与处理技术包括物体检测、图像分类、风格迁移等能力,在AIGC中可以用于从图片库或其他媒体中提取信息,并生成新的图像内容。
- 生成对抗网络(Generative Adversarial Networks,GANs):GANs是一种通过训练两个相互竞争的神经网络来生成新数据的技术。在AIGC中,GANs可以用于生成逼真的图像、音频或视频等媒体内容。
向量库
什么是向量库?
向量库是一种将离散符号化数据(例如单词、句子或实体)转换为连续向量表示形式的技术。这些向量具有语义信息和上下文相关性,能够捕捉到许多潜在特征。它们通常是通过使用词嵌入、句子嵌入等方法,在高维空间中表示数据。
离散符号化数据:是指由离散的符号或标记组成的数据。这些符号可以代表各种类型的信息,例如单词、字母、数字、标签等。
| 离散符号化数据 | 描述 |
|---|---|
| 文字文档 | 包括电子书、新闻文章、评论等。每个文档由单词或字符组成,可以将每个单词或字符视为一个独立的离散符号。 |
| DNA序列 | 在生物学中,DNA序列是由四种碱基(腺嘌呤、胸腺嘧啶、鸟嘌呤和胞嘧啶)组成的字符串。每个碱基可以作为一个离散符号来表示。 |
| 音乐符谱 | 音乐通常用音符和节奏表示。每个音符被认为是一个离散的符号,并且它们按照特定时间顺序排列以形成旋律。 |
| 图像像素值 | 音乐通常用音符和节奏表示。每个音符被认为是一个离散的符号,并且它们按照特定时间顺序排列以形成旋律对于灰度图像而言,每个像素点都代表了不同强度级别的亮度值,在0到255之间取值。这些亮度值可以被看作是一系列离散的数字符号。 |
| 推荐系统中用户评分 | 当用户对商品提供评分时,评分可以被视为一个离散数值(如1-5星),并且可用于构建推荐系统模型。 |
向量库在GPT中的运用:
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的预训练模型,广泛应用于自然语言处理任务。
以下是GPT如何利用向量库进行建模的过程:
- 输入编码:对于每个输入文本序列,如一个句子或段落,在GPT中会将其分割成标记,并为每个标记创建一个唯一的整数ID。
- 词嵌入层:接下来,在输入序列经过一个词嵌入层之前,将每个标记ID映射为对应的词嵌入向量。这些词嵌入代表了不同单词在语义空间中的位置。
- Transformer编码器:GPT利用多层Transformer编码器来对输入序列进行建模。每个Transformer编码器包含自注意力机制(self-attention)和前馈神经网络层。
- 上下文感知嵌入:在GPT中,为了更好地捕捉上下文信息,除了词嵌入之外还引入了位置嵌入。这样可以使得同一个单词在不同上下文环境中具有不同的表示。
- 输出预测:通过训练GPT模型,在最后一个Transformer编码器后面添加一个线性分类层以生成预测结果。该分类层将向量表示映射到特定的任务领域。
向量库在GPT中起着关键作用,它们帮助模型理解语义、推断联系,并且提供一种有效的方式来处理和表示自然语言数据。通过对大规模数据进行无监督学习,向量库能够从海量文本数据中学习并获取丰富的语义信息,并将其应用于各种NLP任务,如问答系统、摘要生成等。
数据集
什么是数据集?

在AIGC(人工智能生成内容)领域,数据集是指用于训练和评估AI模型的大规模样本集合。这些数据集可以包含文本、图像、音频或其他形式的数据。
数据集在GPT中的运用:
在GPT中,数据集扮演了至关重要的角色。它们是用来训练GPT模型的输入源,通过提供大量且多样化的文本语料库,帮助模型学习语言结构、上下文和常见表达方式。通过对这些数据进行预处理并将其输入到GPT中进行训练,模型能够学会预测下一个单词或句子,并生成连贯且合理的输出。
在GPT(生成式预训练模型)中使用数据集的原理如下:
- 数据收集:首先,需要收集与任务相关的大规模文本数据集。这些数据可以包括书籍、文章、网页内容等。
- 预处理:接下来,对收集到的文本数据进行预处理。这可能包括分词、去除停用词、标记化等操作,以便将文本转换为适合输入GPT模型的格式。
- 训练过程:使用预处理后的文本数据对GPT模型进行训练。在训练过程中,GPT会学习到语言结构和上下文之间的关系,并尝试根据给定输入生成连贯且合理的输出。
- 微调:经过初始训练后,可以通过微调进一步优化模型性能。微调是指在特定任务上使用更小规模或更专业领域的数据集重新训练已有的GPT模型。
- 应用阶段:一旦完成了训练和微调,就可以将该已经具备语言生成能力并针对特定任务进行优化的GPT应用于实际情境中。例如,在聊天机器人、自动摘要或翻译等自然语言处理任务中使用。
各领域成熟的AIGC产品
 文章来源:https://www.toymoban.com/news/detail-691416.html
文章来源:https://www.toymoban.com/news/detail-691416.html
- 医疗诊断与辅助:IBM的Watson用于医学图像分析、疾病预测和个性化治疗等方面,在医学领域有广泛应用。
- 音乐生成与创作:Magenta项目由Google Brain团队开发,利用深度学习技术进行音乐生成、作曲以及艺术创作方面取得了显著进展。
- 强化学习(Reinforcement Learning):DeepMind开发了基于强化学习算法DQN和A3C实现玩Atari游戏和围棋超越人类水平,并应用在推荐系统、交通控制等领域中。
- 语音合成与识别(Speech Synthesis and Recognition):Amazon Polly提供高质量自然语音合成服务;Google Assistant以及Apple Siri等智能助理使用了先进的语音识别技术。
- 计算机视觉(Computer Vision):Facebook的Detectron2,用于目标检测和图像分割;Google的DeepMind团队开发的AlphaGo和AlphaZero,在围棋和其他棋类游戏上取得了重大突破。
- 自然语言处理(NLP):Google的BERT(Bidirectional Encoder Representations from Transformers)、OpenAI的GPT系列模型(如GPT-3、GPT-4),用于文本生成、机器翻译、对话系统等。
结语
AIGC领域仍面临着一些挑战。例如数据隐私保护、模型可解释性以及伦理道德问题等需要持续探索和解决。同时,在不断追求技术突破与创新的过程中,也需要平衡好风险管理与社会影响之间的关系。文章来源地址https://www.toymoban.com/news/detail-691416.html
到了这里,关于<AIGC>揭秘人工智能生成内容的核心概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!