系列文章目录
本文专门开一节写SD原理相关的内容,在看之前,可以同步关注:
stable diffusion实践操作
前言
(后期补充)
一、原理说明
1.1、出图原理
<img src+“” width=600>
1.1.1 AI画画不是和人一样,从0开始,而是一个去噪点的过程:

<img src+“” width=600>
1.1.2 逆向去噪
所有的人图片都是从一张噪点图开始的。根据目标生成一张猫的图片,将噪点一步步转化为猫
<img src+“” width=600>
1.1.3 AI如何学会去噪点的
AI首先将图片一步步加入噪点。
<img src+“” width=600>
所以任何一张图都可以逆向这个过程
<img src+“” width=600>
<img src+“” width=600>
<img src+“” width=600>
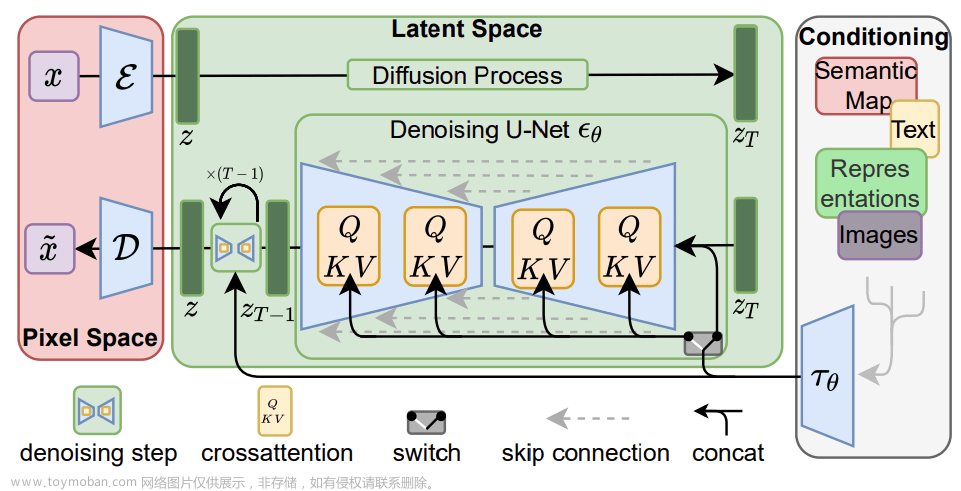
1.2、文生出图机制
生成图片,我们需要两个主要输入,提示词prompt和随机种子
- 将输入的文字进行编码传入潜空间。
- 在潜空间根据文字的描述,进行图片的绘制
- 将图片从潜空间的压缩态进行放大,补充细节,提升分辨率


本文知乎链接:
入口
clip模型
在 Stable Diffusion 模型中,prompt 是通过引导向量(guidance vector)来控制 U-Net 的。具体来说,prompt 会被编码成一个文本嵌入向量(text embeddings),然后与其他输入一起传递给 U-Net。这个过程可以分为以下几个步骤:
- 首先,将 prompt 输入到一个预训练的语言模型(例如 GPT)中,以获得对应的文本嵌入向量(text_embeddings)。
- 接下来,将 text_embeddings 与其他输入(如隐变量 latent_model_input 和时间戳 timestamp)拼接在一起,形成 U-Net 的输入。
- 将这个输入传递给 U-Net,并计算出有条件的噪声预测(noise_pred_text)。同时,也会计算出无条件的噪声预测(noise_pred_uncond)。
- 使用一个指导比例因子(guidance_scale)来调整有条件和无条件噪声预测之间的权重。这个因子可以根据实际需求进行调整,以控制 prompt 对生成结果的影响程度。
- 最后,将加权后的噪声预测传递给扩散调度器(scheduler),并更新隐变量(latents)。
通过这种方式,prompt 能够影响 U-Net 的输出,从而在生成过程中引导模型产生符合预期的结果,即通过 prompt 产生我们想要的图。
解开Clip Skip值的秘密
1.2.1 文字编码 CLIP
计算机不能直接理解文本和图片
而是通过特征向量来标记
而这一项工作是通过CLIP模型来完成的

clip模型包括文字编码器和图片编码器,将文字和图片都编码成向量
所以CLIP设置的层数越高,图片和文字相关度越低,一般设置为2就可以了。
1.2.2 图片绘制
SD绘制图片内容的时候,并不是直接绘制512512的图片,而是绘制核心内容,6464,然后再将图片放大还原。
所以绘图的实际过程就是去噪
1.2.2.1 随机种子和采样器
SD会根据随机种子生成一张正态分布的噪点图,然后根据传入的文字,加入是狗,去向量数据库中搜索,生成狗的去噪方式。去噪方式又是采样器进行调用的
采样器会调用Unet模型,对图片中的噪点预测,生成噪点预测图
让噪点图减去预测出的全部噪点,生成最终的模型图片
1.2.2.2 迭代步数
Unet模型在噪点多的时候,预测并不理想,所以我们并不一次性全部采纳其预测的噪点,而是每次只采用一部分噪点,循环多次

这个过程就是下面的迭代步数
设置过小,图片与文本匹配度较低,过大,则会画蛇添足,一般我们设置为20-40步即可
1.2.2.3 采样方法
采样所采用的算法,不同算法消耗的时间不同。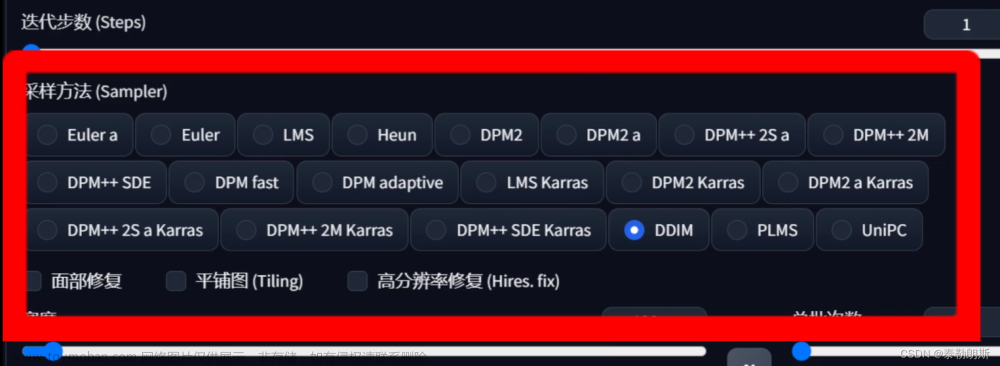
采样器时间对比
一般推荐大家 使用DPM++ SDE Karas/DPM2++ SDE Karas
对比:


1.2.3放大图片
在潜空间产生的图片比较小,我们需要VAE将其放大,优化细节。
这就是整个过程 文章来源:https://www.toymoban.com/news/detail-691477.html
文章来源:https://www.toymoban.com/news/detail-691477.html
总结
例如:以上就是今天要讲的内容。文章来源地址https://www.toymoban.com/news/detail-691477.html
到了这里,关于stable diffusion实践操作-SD原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!