分析&回答
Flink Web UI 自带的反压监控 —— 直接方式
Flink Web UI 的反压监控提供了 Subtask 级别的反压监控。监控的原理是通过Thread.getStackTrace() 采集在 TaskManager 上正在运行的所有线程,收集在缓冲区请求中阻塞的线程数(意味着下游阻塞),并计算缓冲区阻塞线程数与总线程数的比值 rate。其中,rate < 0.1 为 OK,0.1 <= rate <= 0.5 为 LOW,rate > 0.5 为 HIGH。

Web UI 反压监控
以下两种场景可能导致反压:
- 该节点发送速率跟不上它的产生数据速率。该场景一般是单输入多输出的算子,例如FlatMap。定位手段是因为这是从 Source Task 到 Sink Task 的第一个出现反压的节点,所以该节点是反压的根源节点。
- 下游的节点处理数据的速率较慢,通过反压限制了该节点的发送速率。定位手段是从该节点开始继续排查下游节点。
注意事项:
- 因为Flink Web UI 反压面板是监控发送端的,所以反压的根源节点并不一定会在反压面板体现出高反压。如果某个节点是性能瓶颈并不会导致它本身出现高反压,而是导致它的上游出现高反压。总体来看,如果找到第一个出现反压的节点,则反压根源是这个节点或者是它的下游节点。
- 通过反压面板无法区分上述两种状态,需要结合 Metrics 等监控手段来定位。如果作业的节点数很多或者并行度很大,即需要采集所有 Task 的栈信息,反压面板的压力也会很大甚至不可用 。
Flink Task Metrics —— 间接方式
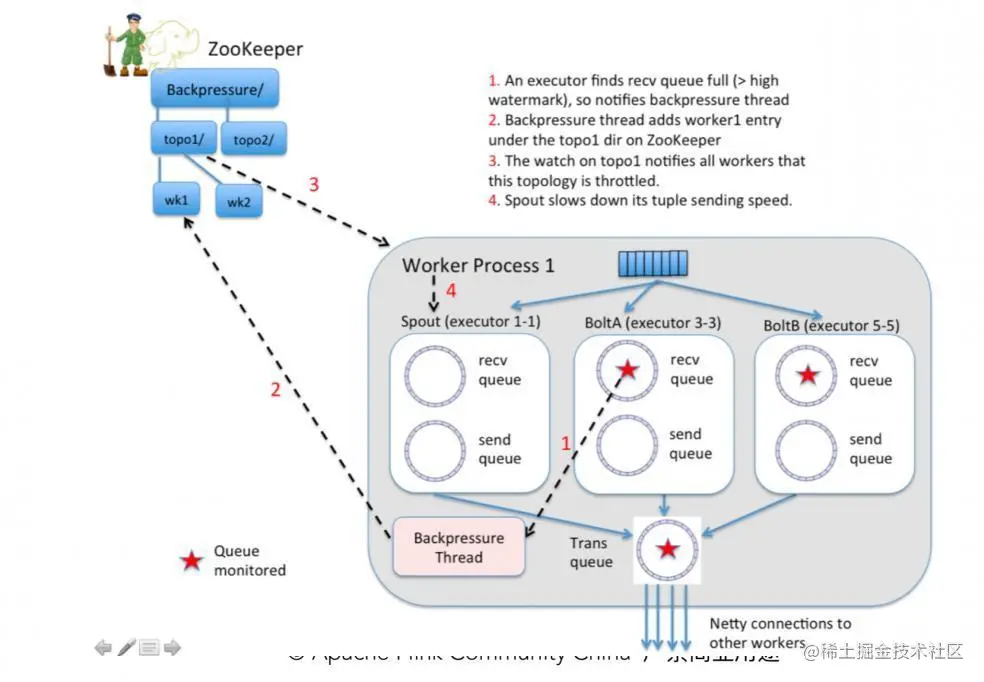
(1)回顾 Flink Credit-based 网络
Flink Credit-Based 网络
① TaskManager 之间的数据传输
不同的 TaskManager 上的两个 Subtask 通常情况下,channel 数量等于分组 key 的数量或者等于算子并发度。这些 channel 会复用同一个 TaskManager 进程的 TCP 请求,并且共享接收端 Subtask 级别的 Buffer Pool。
② 接收端
每个 channel 在初始阶段会被分配固定数量的独享 Exclusive Buffer,用于存储接收到的数据。算子 Operator 使用后再次释放 Exclusive Buffer。说明:channel 接收端空闲的 Buffer 数量称为 Credit,Credit 会被定时同步给发送端,用于决定发送多少个 Buffer 的数据。
③ 流量较大的场景
接收端,channel 写满 Exclusive Buffer 后,Flink 会向 Buffer Pool 申请剩余的 Floating Buffer。发送端,一个 Subtask 所有的 Channel 会共享同一个 Buffer Pool,因此不区分 Exclusive Buffer 和 Floating Buffer。
(2)Flink Task Metrics 监控反压
Network和 task I/Ometrics 是轻量级反压监视器,用于正在持续运行的作业,其中一下几个 metrics 是最有用的反压指标。

metrics反压指标
采用 Metrics 分析反压的思路:如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。

inPoolUsage和outPoolUsage反压分析表
解释:
① outPoolUsage 和 inPoolUsage 同为低表明当前 Subtask 是正常的,同为高分别表明当前 Subtask 被下游反压。
② 如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。
③ 如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高。
注意:反压有时是短暂的且影响不大,比如来自某个 channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下可以不用处理。
下表把 inPoolUsage 分为 floatingBuffersUsage 和 exclusiveBuffersUsage,并且总结上游 Task outPoolUsage 与 floatingBuffersUsage 、 exclusiveBuffersUsage 的关系,进一步的分析一个 Subtask 和其上游 Subtask 的反压情况。

正在上传…重新上传取消
outPoolUsage 与 floatingBuffersUsage 、 exclusiveBuffersUsage 的关系表
- floatingBuffersUsage 为高则表明反压正在传导至上游。
- exclusiveBuffersUsage 则表明了反压可能存在倾斜。如果floatingBuffersUsage 高、exclusiveBuffersUsage 低,则存在倾斜。因为少数 channel 占用了大部分的 floating Buffer(channel 有自己的 exclusive buffer,当 exclusive buffer 消耗完,就会使用floating Buffer)。
3 Flink 如何分析反压
上述主要通过 TaskThread 定位反压,而分析反压原因类似一个普通程序的性能瓶颈。
(1)数据倾斜
通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。解决方式把数据分组的 key 进行本地/预聚合来消除/减少数据倾斜。
(2)用户代码的执行效率
对 TaskManager 进行 CPU profile,分析 TaskThread 是否跑满一个 CPU 核:如果没有跑满,需要分析 CPU 主要花费在哪些函数里面,比如生产环境中偶尔会卡在 Regex 的用户函数(ReDoS);如果没有跑满,需要看 Task Thread 阻塞在哪里,可能是用户函数本身有些同步的调用,可能是 checkpoint 或者 GC 等系统活动。
(3)TaskManager 的内存以及 GC
TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。可以加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。推荐TaskManager 启用 G1 垃圾回收器来优化 GC。文章来源:https://www.toymoban.com/news/detail-691613.html
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!文章来源地址https://www.toymoban.com/news/detail-691613.html
到了这里,关于Flink 如何定位反压节点?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!