本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例
八、线搜索最速下降法
1、最速梯度下降法简介
梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
最速梯度下降法利用函数的一阶信息局部的去找一个让函数下降最快的方向,然后沿着这个方向不断的逼近局部极小值
对于有梯度的函数而言,最速下降的方向一定是其梯度的反方向(如下图中的蓝色箭头所示)

如果梯度存在,沿着梯度的反方向去更新一个x,一定会更接近于局部极小值,迭代格式如下式所示,其中τ是步长, ∇ f ( x k ) \nabla\text{}f\left(x^k\right)\quad\text{} ∇f(xk)是梯度或最小范数次梯度(次梯度集合里面模长最小的那个向量取反方向)
x k + 1 = x k − τ ∇ f ( x k ) x^{k+1}=x^{k}-τ\nabla\text{}f\left(x^k\right)\quad\text{} xk+1=xk−τ∇f(xk)

2、最速梯度下降法流程

3、步长τ的选取
① 策略1:τ取固定常量,如1、0.1、0.01等
② 策略2:τ取递减量,随着搜索的次数增加而减小
③ 策略3:精确线搜索,理想的方式,每次搜索的步长都沿着搜索方向让多元函数的截面到达最低点,称为最佳步长,沿着搜索方向下降最多的步长。然而找最佳步长本身就是一个优化的问题。
④ 策略4:非精确线搜索,将策略3的条件进行弱化,使得搜索步长不需要解决子优化问题,也可以快速的搜索

内容补充:一阶方向导数表示函数在该点处沿着方向d的函数值的变化率,可表示成如下的形式
∂ f ( x ) ∂ d = 1 ∥ d ∥ ∇ f ( x ) T d ; \frac{\partial f\left(x\right)}{\partial d}=\frac{1}{\left\|d\right\|}\nabla f(x)^{T}d; ∂d∂f(x)=∥d∥1∇f(x)Td;
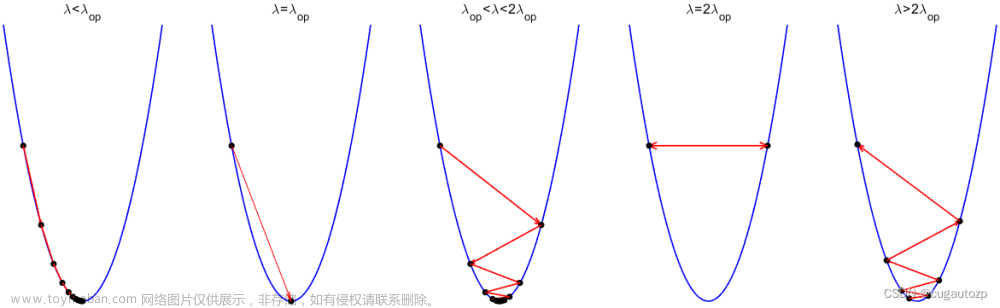
(1)策略①, τ取固定常量时,若步长太大,可能振荡发散;步长太小,可能收敛过慢,当步长恰当时,快速收敛。因此固定步长策略需要依靠经验设定合适的步长,如下图所示:

(2) 策略②的稳定性较强,但收敛速度较慢,一般用于对函数的条件很差的时候,并且对于求解速率和时间没什么要求的时候。
(3) 策略④,我们可以沿着搜索方向d,把周围的函数 f ( x k ) f(x^{k}) f(xk)解出一个一维的函数,这个函数的意思就是,当步长取α时,对应函数的高度就是图中曲线,φ(0)值是 f f f在 f ( x k ) f(x^{k}) f(xk)处的初始值

如果仅是让函数下降的话,跟初始值φ(0)齐平以下的所有区域都可以选,如下图所示的0~α2区域,但是为了更快的下降,需要更严苛的条件,这个条件是跟梯度有关的,比如若局部极小值为1,而当前解为1.001,无论如何不能让函数的下降大于0.001,因此,我们要根据函数当前的梯度或者斜域来定充分下降的斜对数,它的斜率就是φ(0)的斜率,即搜索方向d与 x k x^{k} xk处梯度的点积 d T ∇ f ( x k ) d^{\mathrm{T}}\nabla f(x^{k}) dT∇f(xk),再乘以一个0~1的系数c对其进行放松,得到一个更小的区间0 ~ α1,一般来说,我们需要找一个不接近于0的步长,在这个Armijo condition 区域内搜索一个较靠右的步长,即我们想要的步长。

对于非凸函数的可接受区域如下图所示:

4、最速下降法流程及策略③和④的比较
给定一个x0,首先求他的梯度,取负梯度为它的搜索方向,然后利用二分法不断的二分α区间去找一个满足Armijo condition的步长α,然后接受他,去更新下一个x的位置,不断的循环,当f在xk处的梯度的模长足够小时,结束循环。(当不可微时,梯度改为次微分检验,即含零向量时,即可结束循环)

策略③只有找到上图中的最低点时,才进行更新,而策略④只要找到的步长位于Armijo condition 区域内即可进行更新。这样会节省一些时间,而且更简单一些,在工程中策略④更常用
从下图中可以看出,若采用精确线搜索(策略③),只需要寥寥几步更新就可以收敛较理想的状态,若采用充分下降线搜索(策略④)可能需要迭代多次更新,但是精确线搜索每次迭代花费算力较多,时间较长,而充分下降搜索耗时较少,所以总的花费时间≈单次耗时x迭代次数。两种策略的总耗时是近似的。

在下图所示的这样一个100维的凸函数的例子中,当精度要求比较高时,如0.0001,两种策略的迭代次数近似,而策略③的每次迭代耗时多于策略④

5、最速下降法的收敛速度
u在G度量意义下的范数 ∥ u ∥ G 2 \|u\|_G^2 ∥u∥G2定义为:(其中G为Hesse矩阵)
∥ u ∥ G 2 = u T G u . \|u\|_G^2={u}^\mathrm{T}Gu. ∥u∥G2=uTGu.
对正定二次函数,最速下降方法的收敛速度为
∥ x k + 1 − x ∗ ∥ G 2 ∥ x k − x ∗ ∥ G ⩽ ( λ max − λ min λ max + λ min ) 2 . \frac{\|x_{k+1}-x^*\|_G^2}{\|x_k-x^*\|_G}\leqslant\left(\frac{\lambda_{\text{max}}-\lambda_{\text{min}}}{\lambda_{\text{max}}+\lambda_{\text{min}}}\right)^2. ∥xk−x∗∥G∥xk+1−x∗∥G2⩽(λmax+λminλmax−λmin)2.
上式中有 :(其中 cond ( G ) = ∥ G ∥ ∥ G − 1 ∥ \operatorname{cond}(G)=\|G\|\|G^{-1}\| cond(G)=∥G∥∥G−1∥称为矩阵G的条件数)
λ max − λ min λ max + λ min = c o n d ( G ) − 1 c o n d ( G ) + 1 ≜ μ \frac{\lambda_{\max}-\lambda_{\min}}{\lambda_{\max}+\lambda_{\min}}=\frac{\mathrm{cond}(G)-1}{\mathrm{cond}(G)+1}\triangleq\mu λmax+λminλmax−λmin=cond(G)+1cond(G)−1≜μ.
由上式可以看出,最速下降方法的收敛速度依赖于G的条件数.当G的条件数接近于1时, u接近于零,最速下降方法的收敛速度接近于超线性收敛速度;而G的条件数越大,u越接近于1,该方法的收敛速度越慢.
Hesse矩阵G的条件数的差异造成了最速下降方法对如下图所示的两个问题收敛速度的差异.在下图可以看出,最速下降方法相邻两步的迭代方向互相垂直,Hesse矩阵的条件数越大,二次函数一族椭圆的等高线越扁.可以想象,当目标函数的等高线为一族很扁的椭圆时,迭代在两个相互垂直的方向上交替进行.如果这两个方向没有一个指向极小点,迭代会相当缓慢,甚至收敛不到极小点.

6、最速下降法的优缺点
(1)缺点
当一个凸函数的条件数等于2时,等高线是一系列的椭圆,他的梯度是垂直于椭圆的边界的,如果条件数很大,椭圆就很扁,用最速下降法来迭代就会产生一些震荡。

当条件数更大,如100时,椭圆会更扁,由于梯度方向与等高线垂直,导致梯度方向近似于平行,需要震荡很久才能收敛到局部极小值。所以当函数的曲率很大,或者条件数很大的时候,采用梯度下降法可能需要很多的迭代次数。

下图是一个二维的二次函数的例子,从图中可以看出,随着条件数的增大,收敛所需的迭代次数也随之增加

(2)优点
最速下降方法的优点是:算法每次迭代的计算量少,存储量亦少; 即使从一个不太好的初始点出发,算法产生的迭代点也可能接近极小点.
参考资料:
1、机器人中的数值优化
2、梯度下降文章来源:https://www.toymoban.com/news/detail-691828.html
3、数值最优化方法(高立 编著)文章来源地址https://www.toymoban.com/news/detail-691828.html
到了这里,关于机器人中的数值优化(六)—— 线搜索最速下降法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!