在kafka中有三个经典的问题:
- 如何保证数据有序性
- 如何解决数据丢失问题
- 如何处理数据重复消费
这些不光是面试常客,更是日常使用过程中会遇到的几个问题,下面分别记录一下产生的原因以及如何解决。
1. 消息有序#
kafka 的数据,在同一个partition下是默认有序的,但在多个partition中并不一定能够保证其顺序性。kafka因为其自身的性质,适合高吞吐的流式大数据,对数据有序性要求不严格的场景比较适用。
1.1. 为什么只保证单partition有序?
如果Kafka要保证多个partition有序,不仅broker保存的数据要保持顺序,消费时也要按序消费。假设partition1堵了,为了有序,那partition2以及后续的分区也不能被消费,这种情况下,Kafka 就退化成了单一队列,毫无并发性可言,极大降低系统性能。因此Kafka使用多partition的概念,并且只保证单partition有序。这样不同partiiton之间不会干扰对方。
1.2. 解决方式
kafka自身没有提供整个topic级别的消息顺序性,但我们可以在业务层面来处理。
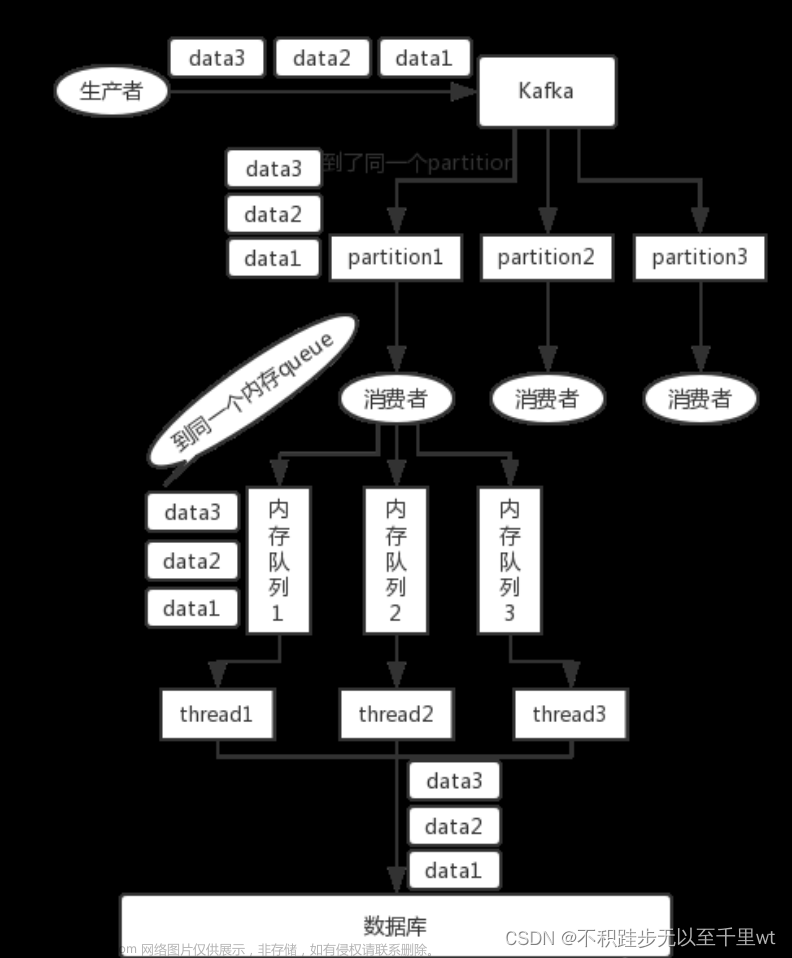
可以通过message key来保证你需要保持顺序性的数据发送到同一个partition,即send方法,可以指定三个参数(topic, partition, key), partition和key是可选的,如果指定了同一个partition的话,那么数据就是有序的。
同时在消费端,只创建一个消费者来消费topic,但后续的话这个消费者可以写入N个内存队列,保证具有相同key的数据写入同一个内存队列即可。引入内存队列是为了解决业务处理单线程处理太慢的问题,多个内存队列可以起多个线程进行消费,同时具有相同key的数据在同一个内存队列中,这样就能保证顺序性。

2. 数据丢失#
丢失数据一般分为两种情况:mq自己弄丢了,业务处理弄丢了。
2.1. kafka弄丢了数据
kafka的某个broker宕机,重新选举partition的leader时,如果其他的follower还没有完成数据同步,此时leader挂了,那么就有可能造成数据丢失的问题。
kafka提供了几个参数来保证数据不丢失:
-
replication.factor:分区副本数,最低设置为2,即要求每个Partition至少拥有两个副本; -
min.insync.replicas:要求一个leader感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower; -
acks:在producer发送数据成功后,kafka会给生产者返回一个ack信息,这个称为kafka的ack机制;ack有3个可选值,-1、0、1;
-
ack=1:producer只要收到一个分区副本写入成功的通知就认为推送消息成功,这个分区副本特指leader副本;
-
ack=0:producer发送一次就不再发送了,不管是否发送成功;
-
ack=-1:producer只有收到分区内所有副本的成功写入通知才算推送消息成功;
-
-
retries:重试次数,如果写入失败就会进行重试,直到超过retries设置的值;
2.2. 消费端弄丢了数据
例如消费者已经获取到这个数据,并且提交了offset,但后续在对数据进行业务操作的时候挂掉了,导致数据没有成功处理,这时候kafka认为你已经成功获取了,但实际没有,就造成了数据丢失的问题。
一般情况下用手动提交的方式来解决,当数据处理成功后再提交offset。
3. 重复消费#
在ack=1的情况下,是有可能存在消息丢失的情况的,因为producer收到leader写入成功的通知就认为推送成功,但实际上leader副本在把消息同步到follower副本的时候失败了,这时候消息就丢失了。
为了处理这种推送失败的情况,kakfa引入了回调机制来处理,实际上就是一种重试的方式,这时候会出现因为重试机制导致消息乱序的情况。
3.1. 解决重试机制引起的消息乱序
生产者Producer
为了实现producer的幂等性,kafka引入了Producer ID和Sequence Number两个参数,对于每个生产者,该Producer发送的消息都对应一个单调增的Sequence Number。同样的Broker端也会为每个生产者的每条消息维护一个序号,并且每commit一条数据时就会将其序号递增。
对于接收到的数据,如果其序号比Borker维护的序号大一(即表示是下一条数据),Broker会接收它,否则将其丢弃。
如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
Sender发送失败后会重试,这样可以保证每个消息都被发送到broker
消费者Consumer文章来源:https://www.toymoban.com/news/detail-692363.html
同样的也是利用幂等性的原理来解决,可以给每条数据加上一个唯一标识,进行数据处理的时候校验这个标识是否存在,如果存在即为重复数据,丢弃。文章来源地址https://www.toymoban.com/news/detail-692363.html
到了这里,关于Kafka经典三大问:数据有序丢失重复的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!