本文主要介绍了基于Stable Diffusion技术的虚拟穿搭试衣的研究探索工作。文章展示了使用LoRA、ControlNet、Inpainting、SAM等工具的方法和处理流程,并陈述了部分目前的实践结果。通过阅读这篇文章,读者可以了解到如何运用Stable Diffusion进行实际操作,并提供更优质的服饰虚拟穿搭体验。

业务背景
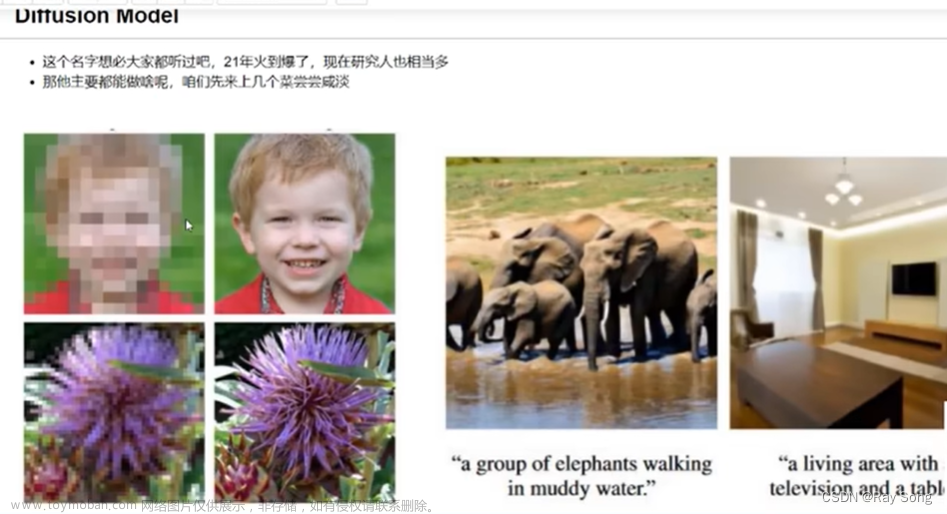
随着AI技术的不断创新,AI创作工具已经逐渐成为艺术家、设计师和创作者们的最佳助手。在AI生图领域,Stable Diffusion以其开源、生出图片质量高等众多优势脱颖而出,展现出强大的综合实力。我们希望利用Stable Diffusion作为工具,在虚拟服饰穿搭领域进行一些创新和探索,期待通过AI技术的应用,在线上提供更多样化、个性化的服装选择和搭配方案,为用户提供更好的服饰虚拟穿搭体验。

现状调研
在虚拟穿搭领域,目前主要有两类主流方法,分别是虚拟试衣VTON和基于Stable Diffusion的AIGC穿搭。
▐ 虚拟试衣VTON
基于图像的虚拟试衣方法的处理流程通常有两个阶段:将试穿的服装扭曲以与目标人物对齐的几何匹配模块(GMM)和将扭曲的服装与目标人物图像混合的Try-On Module (TOM)。

为了训练神经网络,理想的数据集应该是:用户身穿自己衣服的照片,要试穿的衣服产品图,用户身着要试穿衣服的照片,在一般情况下获取到这样大量的理想数据集是非常难的。因此,对于VTON而言,大多数虚拟试衣模型神经网络的训练,都建立在一个上万张女模型数据集的基础上,且这上万张模特数据照片以正面视角为主,缺乏多机位多角度的拍摄。样本图片大小固定为256*192,出图的清晰度已经很难满意目前的用户需求。上述原因都限制了VTON实际应用中的效果。
▐ 基于Stable Diffusion的AIGC穿搭
利用Stable Diffusion的大模型生图能力,辅以LoRA、ControlNet、Inpainting等“外挂”手段,增强穿搭出图的可控性与稳定性。
LoRA
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,是一种参数高效性微调方法。LoRA的基本原理是在冻结预训练好的模型权重参数情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果。

在https://civitai.com/等主流的绘画模型分享网站中,我们可以下载并运用已经finetune好的LoRA模型,用于输出特定风格的人、场景、服饰等。在我们服饰生成的工作中,我们通过对每件服饰准备了十张左右的训练样本图片,经过数据清洗、打标等处理流程后,通过训练生成一个LoRA小模型,这个LoRA模型可以学习到服饰的颜色、纹理等特征,最后应用LoRA模型产出AIGC的服饰穿搭。
ControlNet
在完成上述的LoRA训练后,如果我们希望AI生成的图片更易控制,人物姿态更明确,就可以使用ControlNet插件。ControlNet的核心能力是通过设置各种条件来让AI生成的最终图片结果更加可控。这些条件是通过调整预处理器参数实现的,因此我们需要先了解ControlNet各种预处理器模块的功能。下图展示了一些主要预处理器的功能和对应的模型。

例如,我们可以选择Canny预处理器,再选择对应的模型,对输入的图片进行边缘检测,生成线稿,然后根据Prompt提示词来生成与上传图片同样构图的画面。

Inpainting
Inpainting模式是Stable Diffusion图生图中的一种特殊模式,用户可以通过上传Mask图,使Stable Diffusion根据其余信息(例如Prompt、LoRA、ControlNet)保留Mask内部的全部细节,重绘其余所有部分。

可以通过Mask Mode选择重绘Masked部分或者除Masked外的剩余部分。
Segment Anything
Segment Anything如其名分割一切,是一个由Meta开源的图像分割模型,号称图像分割领域的GPT 4.0。网页demo如下:https://segment-anything.com/demo。在Stable Diffusion的Web UI中,我们也可以通过下载安装Segment Anything插件来实现相同的功能。分割方式非常友好,可以通过左键、右键简单地点击来选择或者提出对应物体,物体就会立即被分割出来,可以绘制成Mask图,直接发送至上节的Inpainting模式中使用。


处理流程
▐ 本地部署
Stable Diffusion Web UI 是一个基于 Stable Diffusion 的基础应用,利用 gradio 模块搭建出交互程序,可以在低代码 GUI 中立即访问 Stable Diffusion,我们在本地部署了Stable Diffusion Web UI ,本地机器显卡配置为RTX3060 12GB。Stable Diffusion Web UI为保持代码整洁和便于管理,逐步将非核心功能解耦并转为插件和拓展脚本形式提供,我们可以根据需要从对应的GitHub仓库中下载插件,并放到Web UI 路径下的extensions文件夹下,启动时Web UI会从中自动加载插件。
Stable Diffusion Web UI 地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
▐ LoRA训练
训练样本背景去除、大小裁剪
在进行LoRA训练前,对于每一件服饰,我们批量处理了约10张样本图片,去除了背景并统一裁剪为512*512的尺寸。
Tag生成
这里,我们使用Tagger插件,Tagger插件可以批量反推样本图片的Tag标签数据,相比于Stable Diffusion图生图中自带的CLIP和DeepBooru插件效果更好。输入样本图片所在的文件夹信息,并在下方填写Additional/Exclude tags选项,即可预设或者屏蔽某些Tag标签的产出。
Tagger 地址:https://github.com/toriato/stable-diffusion-webui-wd14-tagger

Tag编辑
在tag标签生成后,可以通过Dataset Tag Editor插件,对tag进行编辑。目前插件的tag反推精准度依然有限,时常需要人工介入剔除掉一些不相干或者完全错误的Tag词,以保证训练LoRA模型的精准性和还原性。

Dataset Tag Editor 地址:https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
本地训练
在完成上述一系列图片、tag标签的预处理后,就正式进入到了LoRA模型的训练阶段,在本机RTX3060 12GB的机器配置下,完成对示例11张样本图片50批次训练的时间成本在30分钟左右。训练完成后,单个LoRA模型的大小在37MB左右。

▐ ControlNet
在以人物为主的生成图中,最常采用的是openpose系列的预处理器,openpose来对人物全身的骨骼姿态进行检测,使得输出图和上传输入图保留一致的人体骨骼形体,增强输入人物的姿态可控。可以在ControlNet插件中预览人体的骨骼姿态,也可以通过调节Control Weight权重参数来控制骨骼姿态对最终出图结果的影响。


成果展示
▐ 单件试衣
针对于不同类型的服饰采集了训练样本,进行了LoRA的训练,服饰类型包括衬衫、外套、裤子、鞋子等,查看了单一LoRA与模特、虚拟人结合出图的效果。结果发现普通上衣下衣类别的服饰准确率比较高,可以基本还原服饰的颜色、纹理等特征,上身效果也不错。
T恤
输入

输出

外套
输入

输出

夹克
输入

输出

衬衫
输入

输出

长裙
输入

输出

鞋
输入

输出

▐ 季节试衣
在对单一服饰的LoRA训练出图后,我们又对于不同季节的服饰套装进行了风格训练,选取了春秋季、夏季、冬季三个季节的服饰穿搭套装进行了LoRA训练。从产出的图片效果来看,服饰套装的上身效率很不错,搭配比较合理,与季节的关联度比较高。
春秋季

夏季

冬季


总结
我们基于在本地环境搭建的Stable Diffusion,对服饰进行了LoRA小模型微调,学习到服饰自身的特征信息,利用ControlNet插件提升了出图的可靠性与稳定性,初步完成了AIGC的服饰穿搭DEMO实践。从单件服饰的生成穿搭来看,普通类的上下衣主服饰还原度比较高。季节类的套装和人物模特合图效果尚可,上身效果也比较不错。

参考文献
CP-VTON+: Clothing Shape and Texture Preserving Image-Based Virtual Try-On(地址:https://minar09.github.io/cpvtonplus/cvprw20_cpvtonplus.pdf)
Segment Anything(地址:https://segment-anything.com/)
continue-revolution/sd-webui-segment-anything(地址:https://github.com/continue-revolution/sd-webui-segment-anything)
toshiaki1729/stable-diffusion-webui-dataset-tag-editor(地址:https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor)
零基础读懂Stable Diffusion(I):怎么组成(地址:https://zhuanlan.zhihu.com/p/597247221)
Stable Diffusion 常用术语(地址:https://www.bilibili.com/read/cv24001275/?from=search)

团队介绍
我们是大淘宝技术-手猫技术-营销&导购团队,我作为一支专注于手机天猫创新的商业化及导购场景探索的团队,我们团队紧密依托淘天集团强大的互联网背景,致力于为手机天猫带来更高效、更具创新性的技术支持和商业化的导购场景。我们的团队成员来自不同的技术领域和营销导购领域,拥有丰富的技术经验和营销经验。我们不断探索并实践新的技术,创新商业化的导购场景,并将这些创新技术应用于手机天猫业务中,提高了用户体验和平台运营效率。作为一支技术创新和商业化的团队,我们致力于为手机天猫带来更广阔的商业化空间和更高效的技术支持,赢得了用户和客户的高度评价和认可。我们团队一直秉承“技术领先、用户至上”的理念,不断探索创新、提升技术水平,为手机天猫的导购场景和商业化发展做出重要贡献。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术文章来源:https://www.toymoban.com/news/detail-692374.html
服务端技术 | 技术质量 | 数据算法文章来源地址https://www.toymoban.com/news/detail-692374.html
到了这里,关于基于Stable Diffusion的AIGC服饰穿搭实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!