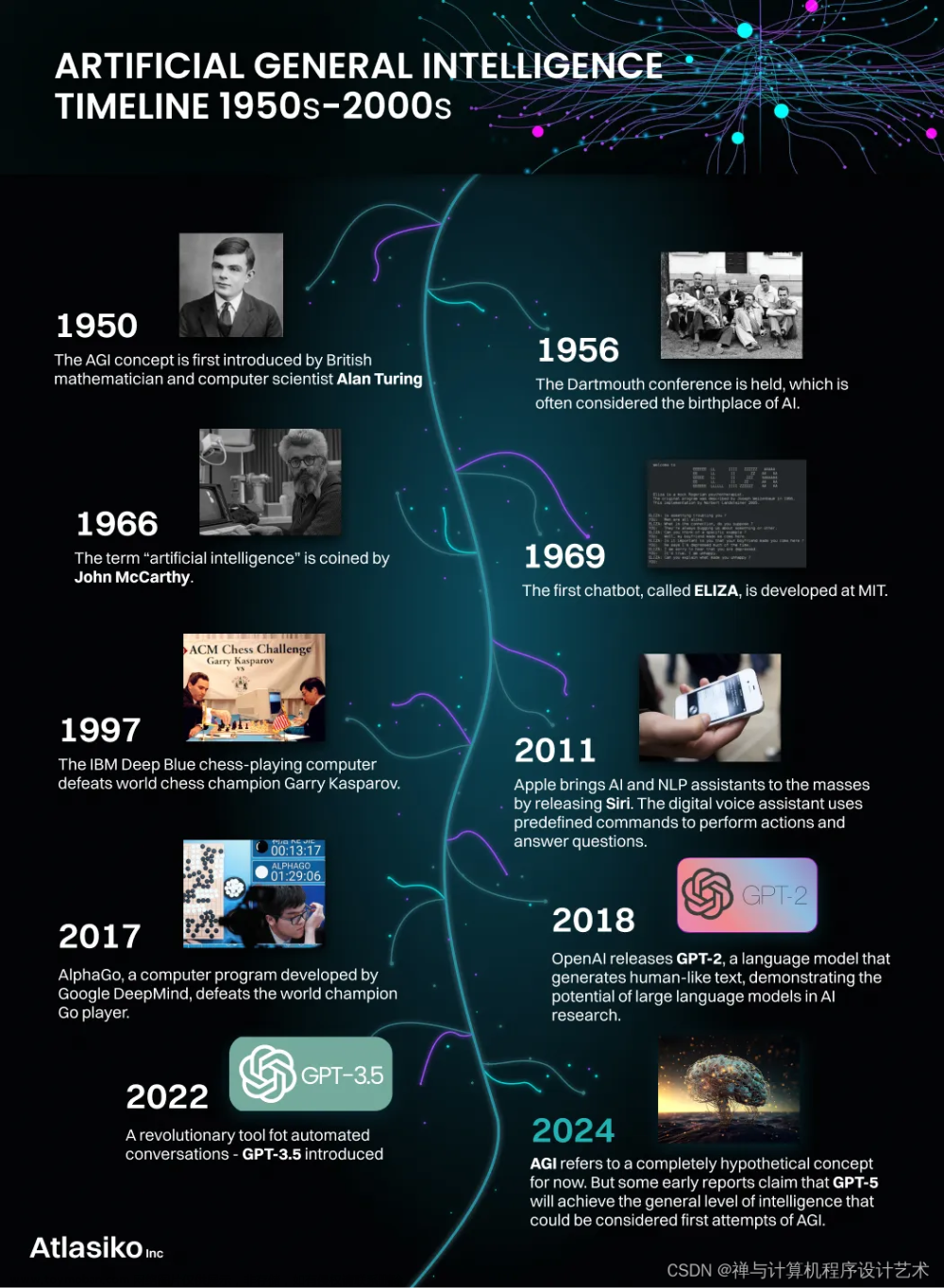
当学习GPT技术时,我们会思考GPT发展的最终目标是什么?答案是“具身智能”,它是一种通用人工智能,可以像人一样能够和环境交互感知、自主规划、决策、行动。
GPT的诞生要归功于NLP技术的快速发展,从2018年到2021年,是第一代大语言模型的“技术爆炸”期,人们逐渐适应了通过海量的无标签数据来训练这些“涌现”智能的大模型,之后OpenAI采用强化学习技术,点亮了LLM的只能,由此产生了ChatGPT。
智能体的自治
我们可以想一下,当我们面临一个任务时,一般的处理步骤是怎样的?通常会有以下几步:
- 思考任务的主要步骤有哪些
- 调取相关资料,形成可行方案
- 通过分工去执行具体的事项
- 汇总完成任务
上面的过程是不是很熟悉,对于智能体来说,我们要做的就是将上面的步骤交给大语言模型(LLM)来完成。
我们如果想让智能体具有“自治”的能力,需要把以下三部分结合起来:
- 计划
- 记忆
- 工具
计划
教LLM思考的过程,一个最佳实践是通过提问来引导LLM思考,经典的方法是ReAct,它包含三部分:
- Thought:让大语言思考,目前需要做哪些行为,行为的对象是谁,它要采取的行为是不是合理的。
- Act:针对目标对象,执行具体的操作,比如调用API,然后收集环境反馈的信息。
- Obs:把外界观察的反馈信息,同步给LLM,协助它做出进一步的分析或者决策。
在这个过程中,思维链技术变得非常重要,它可以让LLM将任务分解为可解释的步骤。
记忆唤醒
无论在定制计划、使用工具或执行任务的过程中,LLM都需要外部信息的帮助来辅助进行思考。
我们可以将人和LLM进行对比,将记忆分为三类:
- 感觉记忆,人体接收到外部信号以后,瞬间保留的视觉、听觉、触觉的记忆片段,在LLM中就是Embedding。
- 短期记忆,当前意识中的信息,在LLM中类似于提示词。
- 长期记忆,人能回忆的所有信息,在LLM中类似于外部向量存储。
LLM能消化的只有提示词中的短时记忆,所以我们需要在长期记忆中选择最重要的内容放入提示词。这个过程描述如下:
- LLM在得到任务后,会帮忙制定记忆唤醒方案
- AI系统执行该方案,生成相关的查询指令,从外部数据中查询数据
- 我们将这些数据交给LLM来判断是否已经获得足够完成任务的数据,如果没有,LLM会生成新的唤醒方案,并循环这个过程
使用工具
要想LLM学会使用工具,首先需要它认识工具。文章来源:https://www.toymoban.com/news/detail-693369.html
我们以Gorilla为例,来描述它教会LLM使用API的全过程:文章来源地址https://www.toymoban.com/news/detail-693369.html
- 我们使用大量API调用代码和文档作为语料,训练一个可以理解API的LLM
- AI系统还将对这些API进行向量化操作,将它们存储在向量数据库中作为外部记忆
- 当用户发起请求时,AI系统会从外部记忆中,获取跟请求相关的API交给LLM
- LLM组合串联这些API形成代码,并执行代码,完成API调用,生成执行结果
到了这里,关于聊聊具身智能怎么实现?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!