-
文献阅读:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- 1. 文章简介
- 2. 具体方法
-
3. 实验结果
-
1. 数学推理
- 1. 实验设计
- 2. 实验结果
- 3. 消解实验
- 4. 鲁棒性考察
-
2. 常识推理
- 1. 实验设计
- 2. 实验结果
-
3. 符号推理
- 1. 实验设计
- 2. 实验结果
-
1. 数学推理
- 4. 结论 & 思考
- 文献链接:https://arxiv.org/abs/2201.11903
1. 文章简介
这篇文章还是一篇关于大模型的prompt调优的文章。
这里,主体的思路是使用Chain of Thought,也就是说把CoT的思路加入到prompt调优当中。和finetune当中使用的CoT方式相似,前者是将答案推导的推理链给出然后交给模型进行finetune,而这里,不在用于finetune,而是将其给出到few-shot learning当中,作为例子来指导模型进行生成推理,从而优化推理过程。
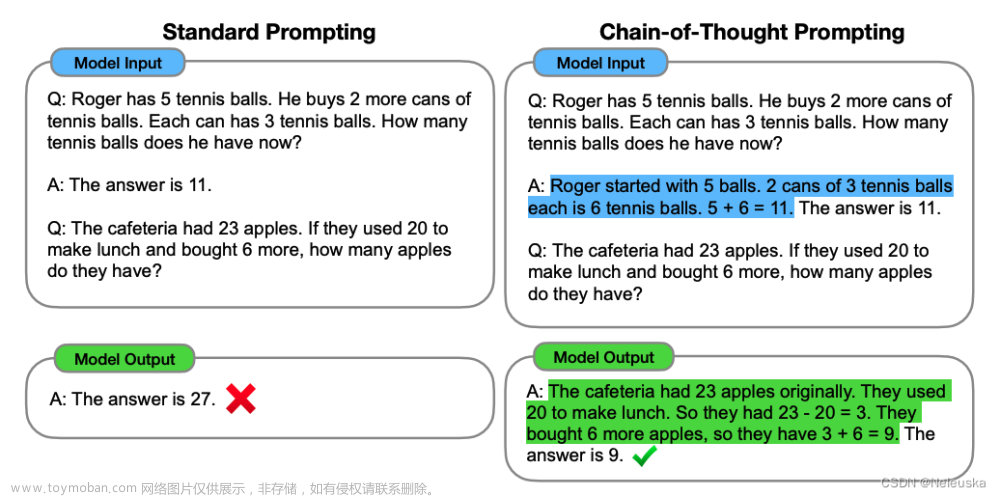
下面是一个具体的CoT prompt的例子:

而CoT Prompting效果的话,我们可以从下述GSM8K上的效果上一窥大概:

可以看到,在GSM8K测试集上,CoT Prompting的效果给LLM带来了显著的效果提升,且超过了当前的SOTA结果。
下面,我们就来看一下CoT Prompting的设计以及文中的实验考察。
2. 具体方法
关于CoT Prompting的具体方法设计,其实在上述的样例图中已经展示的比较清晰了,主旨来说,其实就是通过带有CoT的推理链的few shot例子的方式教给LLM推理的思路链,从而使得模型可以模仿其将问题进行拆分从而获得更加合理的回答。
更具体的,文中给出了CoT Prompting的4个主要的优点如下:
- CoT Prompting将问题进行了解构,从而将多步的问题拆分为了多个中间子问题,从而使得模型在推理过程中可以获得更多的计算,从而优化推理准确率;
- CoT由于解构了问题,从而在回答过程中存在了更多的可解释性,便于调试以及模型的自纠正;
- 可拓展性,CoT Prompting的方式可以广泛地用于数学问题,常识推理以及符号推理等问题当中;
- 使用上的便捷性,只需要通过几个简单的few shot的case,就能引导模型进行CoT的推理方式;
我们给出一些常见问题当中CoT Prompting使用的case如下:

下面,我们来看一下文中给出的一些具体的实验考察。
3. 实验结果
文中从数学推理,常识推理以及符号推理三个方面对CoT Prompting的效果进行了具体的考察。
下面,我们来看一下其各自的实验结果。
1. 数学推理
1. 实验设计
对于数学推理的问题,文中使用的测试数据主要包括:
- GSM8K
- SVAMP
- ASDiv
- AQuA
- MAWPS
而关于Prompt的设计,作为control,文中使用Brown et al.(2020)给出prompt,具体可以参考图一左侧的样例。而作为treatment,则是通过few-shot给出了CoT的样例,同样可以参考图一当中右侧的样例。
最后,关于实验中使用的LLM模型,具体包括以下一些:
- GPT-3
- LaMDA
- PaLM
- UL2 20B
- Codex
2. 实验结果
给出文中具体的实验结果如下:

可以看到:
- 和早期的CoT实验效果相仿,对于小模型,CoT Prompting不一定能够带来提升,但是对于大模型,CoT Prompting可以带来显著的效果提升。
3. 消解实验
对于数学推理问题,中文还给出了CoT Prompting的一些消解实验,具体考察了以下几方面的影响:
- 用公式替换文本描述
- 依然只给出公式,不过公式中用变量名替换掉纯数字
- 将CoT的解释放置到给出答案之后,而不是之前
得到的实验结果如下:

可以看到,普遍效果都不太好,而这些也都比较好理解:
- LLM显然对于语义的理解方面做的比公式的理解能力会强很多;
- 前置解释可以辅助语言模型对于后续答案概率的生成优化。
4. 鲁棒性考察
而除了上述实验之外,文中还对CoT Prompting的鲁棒性进行了考察,具体而言,通过:
- 给出不同的人写作的CoT Prompting进行考察
- 用不同的样例作为few-shot的case
得到的结果如下:

可以看到:
- 虽然存在一定的效果波动,不过整体而言CoT Prompting依然可以稳定地带来效果上的提升。
2. 常识推理
文中除了对于数学推理之外,还对常识推理进行了一些实验考察。
1. 实验设计
我们首先来看一下常识推理的一些实验设计。
在数据集选择方面,文中使用了如下一些测试数据集:
- CSQA
- StrategyQA
- Date
- Sports
- SayCan
而关于prompt以及模型的设计,则保持和前述数学推理相一致。
2. 实验结果
给出文中的实验结果如下:

可以看到:
- 除了在CSQA数据集上没有获得较大的提升之外,在其他数据集上,CoT Prompting都带来了很大的性能提升,甚至在Sports数据集上超出了人类的水平。
3. 符号推理
最后,我们来看一下文中对于符号推理的实验结果。
1. 实验设计
首先,在实验设计方面,其他方面同样和之前的两个实验保持一致,只有在数据集上存在区别。
具体而言,这里使用如下两个数据集:
- Last letter concatenation
- Coin flip
2. 实验结果
给出文中的实验结果如下:

同样可以看到:
- CoT可以稳定地带来效果提升。
4. 结论 & 思考
综上,我们基本可以得出结论:
- 通过在few-shot learning当中加入CoT的方式,可以使得模型在生成过程中模仿CoT的方式,从而优化生成的结果。
这个结论本身倒是还挺好理解的,易用且有效,在这个以优化prompt为王的时代里,倒是可以在工作当中帮上大忙了。文章来源:https://www.toymoban.com/news/detail-693697.html
不过这里我个人觉得,更本质的特征还是如何诱导模型进行CoT推理,诚然,这里是使用了一个最直接的方式,就是在few-shot当中直接加入样例,但是对于一些context非常长的case,这不一定可行,但是核心思路依然是可以借鉴的,在后续的prompt调优当中,个人觉得不失为一种优化的思路。文章来源地址https://www.toymoban.com/news/detail-693697.html
到了这里,关于文献阅读:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations](https://imgs.yssmx.com/Uploads/2024/02/608289-1.png)




