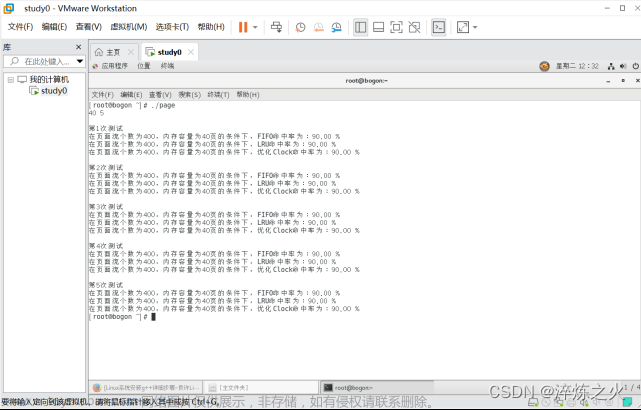
一、算法介绍
最近最久未使用(Least Recently Used LRU)算法是⼀种缓存淘汰策略,它是大部分操作系统为最大化页面命中率而广泛采用的一种页面置换算法。该算法的思路是,发生缺页中断时,将最近一段时间内最久未使用的页面置换出去。 从程序运行的原理来看,最近最久未使用算法是比较接近理想的一种页面置换算法,这种算法既充分利用了内存中页面调用的历史信息,又正确反映了程序的局部问题。
虚拟页式存储管理,则是将进程所需空间划分为多个页面,内存中只存放当前所需页面,其余页面放入外存的管理方式。
有利就有弊,虚拟页式存储管理减少了进程所需的内存空间,却也带来了运行时间变长这一缺点:进程运行过程中,不可避免地要把在外存中存放的一些信息和内存中已有的进行交换,由于外存的低速,这一步骤所花费的时间不可忽略。因而,采取尽量好的交换算法以减少读取外存的次数,也是相当有意义的事情。
二、基本原理
假设 序列为 4 3 4 2 3 1 4 2
物理块有3个 则
4调入内存 4
3调入内存 3 4
4调入内存 4 3
2调入内存 2 4 3
3调入内存 3 2 4
1调入内存 1 3 2(因为最少使用的是4,所以丢弃4)
4调入内存 4 1 3(原理同上)
2调入内存 2 4 1
规律就是,如果新存入或者访问一个值,则将这个值放在队列开头。如果存储容量超过上限cap,那么删除队尾元素,再存入新的值。
我们下面通过一个简单的存储int的方式来实现LRU cache,实现put和get功能。
三、数据结构
⾸先要接收⼀个参数作为缓存的最⼤容量, 然后实现两个 API, ⼀个是 put(key, val) ⽅法存⼊键值对,get(key) ⽅法获取 key 对应的 val, 如果 key 不存在则返回null,get 和 put ⽅法必须都是 O(1) 的时间复杂度。
因此LRU cache 的数据结构的必要的条件: 查找快, 插⼊快, 删除快, 有顺序之分。那么, 什么数据结构同时符合上述条件呢? 哈希表查找快, 但是数据⽆固定顺序; 链表有顺序之分, 插⼊删除快, 但是查找慢。 所以结合⼀下, 形成⼀种新的数据结构: 哈希链表。如下图所示:

四、算法细节
新插入的元素或者最新查询的元素要放到链表的头部,对于长时间未访问的元素要放到链表尾部,所以每次插入或者查询都需要维护链表中元素的顺序。
使用哈希表的原因是查询时间复杂度为O(1),使用双向链表的原因是对于删除和插入操作时间复杂度为O(1)。
其中哈希表中存储的 key 为 K,value 为 Node<K,V> 的引用,双向链表存储的元素为Node<K,V>的引用.
put 方法是线程安全方法,定义如下所示:
public synchronized void put(K key,V value)对于put操作:
①首先判断缓存中 元素 K 是否存在,如果存在,则把链表中的元素Node<K, V>删除,map中的数据<K, Node<K, V> >不用删除,再在链表头部插入元素,并更新map,直接返回即可 ;
②缓存不存在,并且缓存没有满的话,直接把元素插入链表的表头,缓存满了的话移除表尾元素(最旧未访问元素),将元素K插入表头,增加map中的<K, Node<K, V>>, 更新map。
get 方法是线程安全方法,定义如下所示:
public synchronized V get(K key)对于get操作:文章来源:https://www.toymoban.com/news/detail-693752.html
首先要判断 缓存中(map)是否存在,如果存在则把该节点删除并在链表头部插入该元素并更新map 返回当前元素即可,如果map不存在 则直接返回null;文章来源地址https://www.toymoban.com/news/detail-693752.html
五、算法实现
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}六、总结
到了这里,关于LRU算法(JAVA实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!