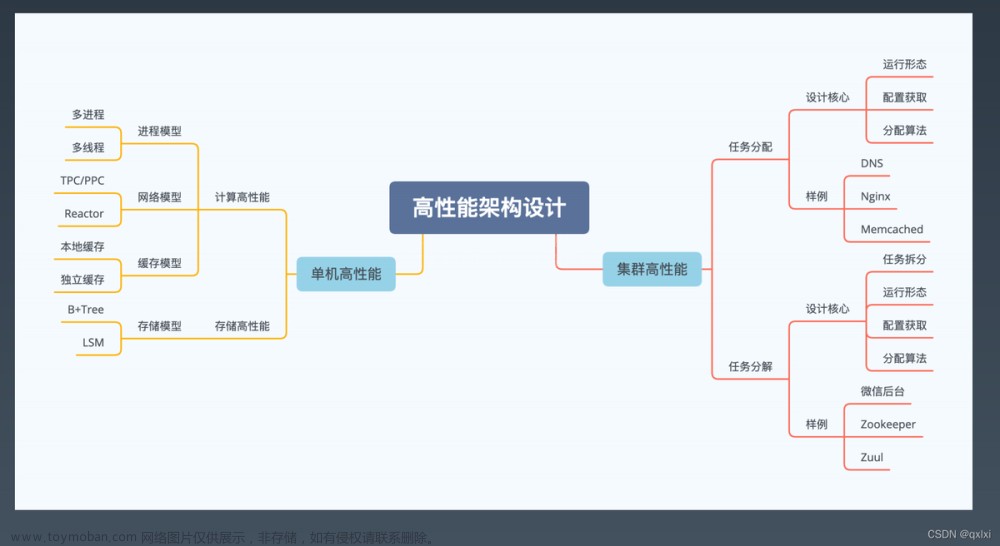
高斯模糊简介
高斯模糊是一种常用的图像处理技术,用于减少图像中的噪点和细节,并实现图像的平滑效果。它是基于高斯函数的卷积操作,通过对每个像素周围的邻域像素进行加权平均来实现模糊效果。
具体而言,高斯模糊通过在图像上滑动一个卷积核,将卷积核与输入图像的对应像素进行一一相乘,并将结果相加,从而产生输出图像的每个像素值。这个卷积核是一个二维高斯函数,它的形状决定了模糊的程度。在高斯函数中,离中心像素越远的像素会被赋予更小的权重,从而降低了离中心像素的贡献,实现模糊的效果。
通过调整高斯核的大小和标准差参数,可以控制模糊的程度。较大的核和较大的标准差会导致更强烈的模糊效果,而较小的核和较小的标准差则会产生更细微的模糊。
主函数:host端
#include <iostream>
#include <fstream>
#include <sstream>
#include <string.h>
#ifdef __APPLE__
#include <OpenCL/cl.h>
#else
#include <CL/cl.h>
#endif
#include <opencv2/opencv.hpp>
//在第一个平台中创建只包括GPU的上下文
cl_context CreateContext()
{
cl_int errNum;
cl_uint numPlatforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
// 选择第一个平台
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlatforms);
if (errNum != CL_SUCCESS || numPlatforms <= 0)
{
std::cerr << "Failed to find any OpenCL platforms." << std::endl;
return NULL;
}
// 接下来尝试通过GPU设备建立上下文
cl_context_properties contextProperties[] =
{
CL_CONTEXT_PLATFORM,
(cl_context_properties)firstPlatformId,
0
};
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_CPU,
NULL, NULL, &errNum);
if (errNum != CL_SUCCESS)
{
std::cout << "Could not create GPU context, trying CPU..." << std::endl;
context = clCreateContextFromType(contextProperties, CL_DEVICE_TYPE_CPU,
NULL, NULL, &errNum);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to create an OpenCL GPU or CPU context." << std::endl;
return NULL;
}
}
return context;
}
//在第一个设备上创建命令队列
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id *device)
{
cl_int errNum;
cl_device_id *devices;
cl_command_queue commandQueue = NULL;
size_t deviceBufferSize = -1;
// 首先获得设备的信息
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, NULL, &deviceBufferSize);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed call to clGetContextInfo(...,GL_CONTEXT_DEVICES,...)";
return NULL;
}
if (deviceBufferSize <= 0)
{
std::cerr << "No devices available.";
return NULL;
}
//为设备分配内存
devices = new cl_device_id[deviceBufferSize / sizeof(cl_device_id)];
errNum = clGetContextInfo(context, CL_CONTEXT_DEVICES, deviceBufferSize, devices, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to get device IDs";
return NULL;
}
// 选择第一个设备并为其创建命令队列
cl_queue_properties properties[] = {0};
commandQueue = clCreateCommandQueueWithProperties(context, devices[0], properties, NULL);
if (commandQueue == NULL)
{
std::cerr << "Failed to create commandQueue for device 0";
return NULL;
}
//释放信息
*device = devices[0];
delete [] devices;
return commandQueue;
}
// 创建OpenCL程序对象
cl_program CreateProgram(cl_context context, cl_device_id device, const char* fileName)
{
cl_int errNum;
cl_program program;
std::ifstream kernelFile(fileName, std::ios::in);
if (!kernelFile.is_open())
{
std::cerr << "Failed to open file for reading: " << fileName << std::endl;
return NULL;
}
std::ostringstream oss;
oss << kernelFile.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
program = clCreateProgramWithSource(context, 1,
(const char**)&srcStr,
NULL, NULL);
if (program == NULL)
{
std::cerr << "Failed to create CL program from source." << std::endl;
return NULL;
}
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (errNum != CL_SUCCESS)
{
// 输出错误信息
char buildLog[16384];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
sizeof(buildLog), buildLog, NULL);
std::cerr << "Error in kernel: " << std::endl;
std::cerr << buildLog;
clReleaseProgram(program);
return NULL;
}
return program;
}
//清除资源
void Cleanup(cl_context context, cl_command_queue commandQueue,
cl_program program, cl_kernel kernel, cl_mem imageObjects[2],
cl_sampler sampler)
{
for (int i = 0; i < 2; i++)
{
if (imageObjects[i] != 0)
clReleaseMemObject(imageObjects[i]);
}
if (commandQueue != 0)
clReleaseCommandQueue(commandQueue);
if (kernel != 0)
clReleaseKernel(kernel);
if (program != 0)
clReleaseProgram(program);
if (sampler != 0)
clReleaseSampler(sampler);
if (context != 0)
clReleaseContext(context);
}
const char* GetOpenCLErrorString(cl_int errorCode)
{
switch (errorCode) {
case CL_SUCCESS:
return "CL_SUCCESS";
case CL_DEVICE_NOT_FOUND:
return "CL_DEVICE_NOT_FOUND";
case CL_INVALID_VALUE:
return "CL_INVALID_VALUE";
// 其他错误码的处理
default:
return "Unknown error code";
}
}
cl_mem LoadImage(cl_context context, char* fileName, int& width, int& height)
{
cv::Mat image = cv::imread(fileName, cv::IMREAD_COLOR);
if (image.empty())
{
std::cerr << "Error loading image" << std::endl;
return 0;
}
/* 修改:将图像数据从 BGR 转换为 RGBA 格式 */
//一般图像算法都为rgba的格式
cv::cvtColor(image, image, cv::COLOR_BGR2RGBA);
width = image.cols;
height = image.rows;
cl_image_format clImageFormat;
clImageFormat.image_channel_order = CL_RGBA;
clImageFormat.image_channel_data_type = CL_UNSIGNED_INT8;
cl_int errNum;
cl_mem clImage;
cl_image_desc clImageDesc;
memset(&clImageDesc, 0, sizeof(cl_image_desc));
clImageDesc.image_type = CL_MEM_OBJECT_IMAGE2D;
clImageDesc.image_width = width;
clImageDesc.image_height = height;
clImageDesc.image_row_pitch = 0;
clImageDesc.image_slice_pitch = 0;
clImageDesc.num_mip_levels = 0;
clImageDesc.num_samples = 0;
clImageDesc.image_depth = 1;
/* 移除:不再需要使用缓冲区 */
clImage = clCreateImage(
context,
CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
&clImageFormat,
&clImageDesc,
image.data,
&errNum
);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error creating CL image object:" << GetOpenCLErrorString(errNum) << std::endl;
return 0;
}
return clImage;
}
void saveRGBAtoJPG(const char* filename, const char* buffer, int width, int height) {
cv::Mat image(height, width, CV_8UC4, (void*)buffer);
// 转换 RGBA 到 BGR 格式
cv::cvtColor(image, image, cv::COLOR_RGBA2BGR);
// 保存图像为 JPG 文件
cv::imwrite(filename, image);
}
//获取最接近的倍数
//任务均分:在并行计算中,经常需要将一个较大的任务或数据集分成多个小任务或数据块,分配给不同的处理单元并行执行。
//使用 RoundUp 函数可以将总任务数 globalSize 向上舍入到 groupSize 的倍数,确保每个处理单元都获得相等的任务数,避免了任务不均衡的情况。
//内存对齐:在一些场景下,为了提高内存访问的效率,需要将数据按照一定的对齐方式存储,即确保数据的起始地址和长度都是某个特定数值的倍数。
//通过使用 RoundUp 函数,可以将数据长度 globalSize 向上舍入到 groupSize 的倍数,以满足对齐的要求,从而获得更好的内存访问性能。
size_t RoundUp(int groupSize, int globalSize)
{
int r = globalSize % groupSize;
if(r == 0)
{
return globalSize;
}
else
{
return globalSize + groupSize - r;
}
}
// 创建输出的图像对象
cl_mem CreateOutputImage(cl_context context, int width, int height)
{
cl_image_format clImageFormat;
clImageFormat.image_channel_order = CL_RGBA;
clImageFormat.image_channel_data_type = CL_UNSIGNED_INT8;
cl_int errNum;
cl_mem clImage;
cl_image_desc clImageDesc;
memset(&clImageDesc, 0, sizeof(cl_image_desc));
clImageDesc.image_type = CL_MEM_OBJECT_IMAGE2D;
clImageDesc.image_width = width;
clImageDesc.image_height = height;
clImageDesc.image_row_pitch = 0;
clImageDesc.image_slice_pitch = 0;
clImageDesc.num_mip_levels = 0;
clImageDesc.num_samples = 0;
clImageDesc.image_depth = 1;
clImage = clCreateImage(
context,
CL_MEM_WRITE_ONLY,
&clImageFormat,
&clImageDesc,
NULL,
&errNum
);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error creating output CL image object: " << GetOpenCLErrorString(errNum) << std::endl;
return 0;
}
return clImage;
}
int main()
{
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
//这段代码定义了一个长度为 2 的 cl_mem 数组 imageObjects,并初始化所有元素为 0。
cl_mem imageObjects[2] = { 0, 0 };
//图像采样器 (cl_sampler) 可以与图像对象 (cl_mem) 一起使用,
//用于在内核函数中从图像中获取特定位置像素的值。它控制着采样的方式,
//以及在读取图像时如何处理越界的、边界问题,以及如何进行插值以获得平滑的结果。
cl_sampler sampler = 0;
cl_int errNum;
// 创建上下文
context = CreateContext();
if (context == NULL)
{
std::cerr << "Failed to create OpenCL context." << std::endl;
return 1;
}
// 创建命令队列
commandQueue = CreateCommandQueue(context, &device);
if (commandQueue == NULL)
{
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 确保设备支持这种图像格式
cl_bool imageSupport = CL_FALSE;
clGetDeviceInfo(device, CL_DEVICE_IMAGE_SUPPORT, sizeof(cl_bool),
&imageSupport, NULL);
if (imageSupport != CL_TRUE)
{
std::cerr << "OpenCL device does not support images." << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 加载图像
int width, height;
char* imagePath = "/work/myopencl/build/test.jpg";
imageObjects[0] = LoadImage(context, imagePath, width, height);
if (imageObjects[0] == 0)
{
std::cerr << "Error loading: " << std::string("123.png") << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 创建输出的图像对象
imageObjects[1] = CreateOutputImage(context, width, height);
if(imageObjects[1] == 0)
{
std::cerr << "Error creating CL output image object." << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 创建采样器对象
//寻址模式(Addressing Mode)是一种定义在像素采样过程中如何处理超出纹理边界的采样坐标的方法。它决定了当采样坐标超过纹理边界时,如何获取纹理中的值。
//CL_FALSE:这是一个布尔值参数,表示使用非规范化的采样坐标。非规范化坐标意味着采样坐标在整数范围内,而不是标准化到 [0, 1] 的范围。
//CL_ADDRESS_CLAMP_TO_EDGE:这个参数指定了图像采样器的地址模式,CL_ADDRESS_CLAMP_TO_EDGE 表示超出图像边界的采样坐标将被截断到最近的边缘像素的颜色值。
//CL_FILTER_NEAREST:这个参数指定了图像采样器的过滤方式,CL_FILTER_NEAREST 表示使用最近邻插值,也就是返回与采样坐标最近的像素值,不进行插值计算。
cl_sampler_properties samplerProps[] = {
CL_SAMPLER_NORMALIZED_COORDS, CL_FALSE, // 非规范化坐标
CL_SAMPLER_ADDRESSING_MODE, CL_ADDRESS_CLAMP_TO_EDGE, // 寻址模式为 CL_ADDRESS_CLAMP_TO_EDGE
CL_SAMPLER_FILTER_MODE, CL_FILTER_NEAREST, // 过滤模式为 CL_FILTER_NEAREST
0 // 列表结束符
};
sampler = clCreateSamplerWithProperties(context, samplerProps, &errNum);
if (errNum != CL_SUCCESS)
{
std::cerr << "Failed to create sampler: " << GetOpenCLErrorString(errNum) << std::endl;
return 0;
}
// 创建OpenCL程序对象
program = CreateProgram(context, device, "/work/myopencl/resource/mywork.cl");
if (program == NULL)
{
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 创建OpenCL核
kernel = clCreateKernel(program, "gaussian_filter", NULL);
if (kernel == NULL)
{
std::cerr << "Failed to create kernel" << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 设定参数
//该操作的目的是将 clSetKernelArg 函数的返回值(错误码)累积到 errNum 变量中
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &imageObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &imageObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_sampler), &sampler);
errNum |= clSetKernelArg(kernel, 3, sizeof(cl_int), &width);
errNum |= clSetKernelArg(kernel, 4, sizeof(cl_int), &height);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error setting kernel arguments." << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
size_t localWorkSize[2] = { 16, 16 };
size_t globalWorkSize[2] = { RoundUp(localWorkSize[0], width),
RoundUp(localWorkSize[1], height) };
// 将内核排队
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error queuing kernel for execution." << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
// 将输出缓冲区读回主机
char *buffer = new char [width * height * 4];
size_t origin[3] = { 0, 0, 0 };
size_t region[3] = { size_t(width), size_t(height), 1};
//在 OpenCL 中,clEnqueueReadImage 函数用于从图像对象中读取数据到主机内存。该函数的 origin 和 region 参数用于指定要读取的区域。
//origin 参数是一个包含三个元素的数组,即 [x, y, z],指定了要读取的起始位置在图像中的坐标。
//origin[0] 表示 x 坐标,origin[1] 表示 y 坐标,origin[2] 表示 z 坐标。对于二维图像,我们通常将 origin[2] 设置为 0。
//region 参数也是一个包含三个元素的数组,即 [width, height, depth],指定了要读取的区域的尺寸。
//region[0] 表示区域的宽度,region[1] 表示区域的高度,region[2] 表示区域的深度。对于二维图像,我们可以将 region[2] 设置为 1
errNum = clEnqueueReadImage(commandQueue, imageObjects[1], CL_TRUE,
origin, region, 0, 0, buffer,
0, NULL, NULL);
if (errNum != CL_SUCCESS)
{
std::cerr << "Error reading result buffer." << std::endl;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 1;
}
std::cout << std::endl;
std::cout << "Executed program succesfully." << std::endl;
//保存输出图像
saveRGBAtoJPG("result.jpg", buffer, width, height);
delete [] buffer;
Cleanup(context, commandQueue, program, kernel, imageObjects, sampler);
return 0;
}
设备端函数:mywork.cl
__kernel void gaussian_filter(__read_only image2d_t srcImg,
__write_only image2d_t dstImg,
sampler_t sampler,
int width, int height)
{
float kernelWeights[9] = { 1.0f, 2.0f, 1.0f,
2.0f, 4.0f, 2.0f,
1.0f, 2.0f, 1.0f };
int2 startImageCoord = (int2) (get_global_id(0) - 1, get_global_id(1) - 1);
int2 endImageCoord = (int2) (get_global_id(0) + 1, get_global_id(1) + 1);
int2 outImageCoord = (int2) (get_global_id(0), get_global_id(1));
if (outImageCoord.x < width && outImageCoord.y < height)
{
int weight = 0;
float4 outColor = (float4)(0.0f, 0.0f, 0.0f, 0.0f);
for( int y = startImageCoord.y; y <= endImageCoord.y; y++)
{
for( int x = startImageCoord.x; x <= endImageCoord.x; x++)
{
outColor += convert_float4(read_imageui(srcImg, sampler, (int2)(x, y)))/255.0f * (kernelWeights[weight] / 16.0f);
weight += 1;
}
}
//写入输出图像
//write_imagef(dstImg, outImageCoord, outColor);//正常的高斯模糊后的图像
//write_imagef(dstImg, outImageCoord, (float4)(1.0f,outColor.yzw));//二次处理
float4 multipliedPixel = outColor * 255.0f;
int4 clampedPixel = convert_int4(clamp(multipliedPixel, 0.0f, 255.0f));
write_imagei(dstImg, outImageCoord, clampedPixel);
}
}
int2 是 OpenCL 中的内建类型之一,用于表示二维整数向量。它由两个 int 类型的组成,分别表示 x 和 y 坐标。
read_imagef(srcImg, sampler, (int2)(x, y)) 是一个 OpenCL 内建函数,用于从图像对象中的某个二维点坐标读取指定位置的4通道像素值。
具体来说,read_imagef() 函数的作用是在给定的图像对象 srcImg 中,使用指定的采样器 sampler,读取位于 (x, y) 坐标位置的像素值。
该函数返回一个 float4 类型的像素值,其中的四个分量分别表示红色、绿色、蓝色和透明度(RGBA)。这是一个浮点型的 RGBA 值,范围通常是从 0.0 到 1.0。
注:image2d_t 是 OpenCL 中用于表示二维图像的类型。它并不是用来表示具体的内存类型,而是用来表示一个图像对象的引用。
在 OpenCL 中,图像对象是存储在设备内存中的二维图像数据。image2d_t 类型的对象实际上是对图像数据的引用,可以用于在内核函数中对图像数据进行读取和写入操作。
图像数据可以存储在不同的设备内存类型中,如全局内存、纹理内存等,具体取决于实际的硬件和内存配置。在创建图像对象时,您需要明确指定图像的内存类型,并在内核函数中使用相应的函数进行图像操作。
在内核函数中,可以使用像 read_imagef 和 write_imagef 这样的函数来读取和写入 image2d_t 类型的图像对象。这些函数可以根据图像的内存类型进行相应的操作,以实现对图像数据的读写。
总结来说,image2d_t 并不是一个具体的内存类型,它是用来表示二维图像数据对象的引用,并提供一组操作函数来访问和修改图像数据。具体的图像数据存储在设备的某种内存类型中,如全局内存或纹理内存。文章来源:https://www.toymoban.com/news/detail-694151.html
效果图对比
模糊后:
模糊前: 文章来源地址https://www.toymoban.com/news/detail-694151.html
文章来源地址https://www.toymoban.com/news/detail-694151.html
到了这里,关于【高性能计算】opencl语法及相关概念(四):结合opencv进行图像高斯模糊处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!