大语言模型
大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。来自百度百科
-
发展历史
2020年9月,OpenAI授权微软使用GPT-3模型,微软成为全球首个享用GPT-3能力的公司。2022年,Open AI发布ChatGPT模型用于生成自然语言文本。2023年3月15日,Open AI发布了多模态预训练大模型GPT4.0。
2023年2月,谷歌发布会公布了聊天机器人Bard,它由谷歌的大语言模型LaMDA驱动。2023年3月22日,谷歌开放Bard的公测,首先面向美国和英国地区启动,未来逐步在其它地区上线。
2023年2月7日,百度正式宣布将推出文心一言,3月16日正式上线。文心一言的底层技术基础为文心大模型,底层逻辑是通过百度智能云提供服务,吸引企业和机构客户使用API和基础设施,共同搭建AI模型、开发应用,实现产业AI普惠。
大语言模型有多强?
下面实例展示LLM的能力,以cahtGLM-6B来展示示例:
通过合适的 prompt 就能实现很多传统 NLP 的功能。
github:cahtGLM-6B
官网:cahtGLM
分词
输入:
按照下面的示例输出结果:
输入:今天天气太差了
输出:今天,天气,太,差,了
输入:明天要出去玩
输出:
输出:
- 示例2:不同的 prompt 输出的结果有所不同
prompt1: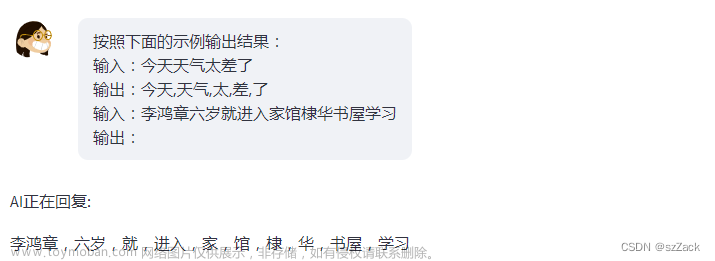
prompt2: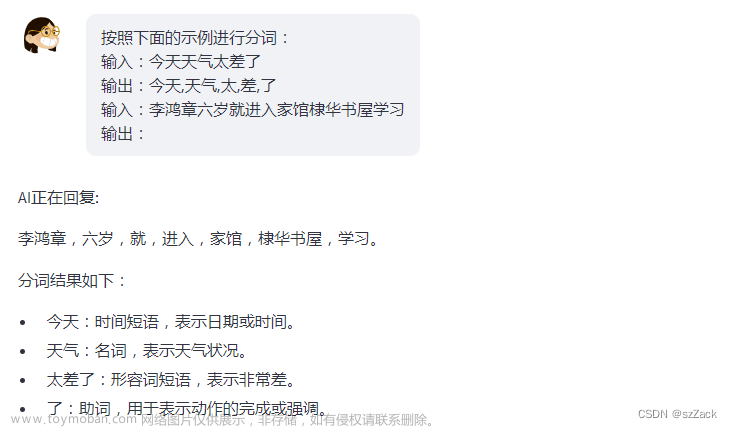
词性标注
输入:
词性标注:
今天
天气
差
输出:
NER
- NER示例1: LLM 可以根据示例直接输出json结果
输入:
按照下面的示例输出结果:
输入:糖尿病是一种慢病
输出:{"disease":"糖尿病"}
输入:糖尿病的一种症状是多尿,还有容易饿
输出:{"disease":"糖尿病","symptom":"多尿,容易饿"}
输入:高血压的症状包括血压偏高、头晕等
输出:
输出: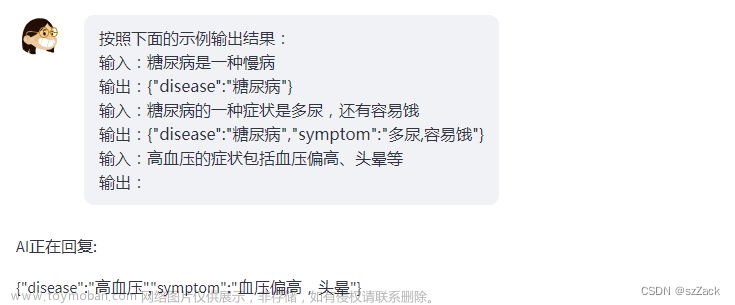
- NER示例2
输入:
按照下面的示例输出结果:
输入:曾国藩是道光进士,曾任内阁学士,道光末年官至侍郎。
输出:{"person":"曾国藩"}
输入:李鸿章为道光二十七年(1847年)进士,早年随业师曾国藩镇压太平天国运动与捻军起义,并受命组建淮军,因战功擢升至直隶总督,兼北洋通商大臣,累加至文华殿大学士,封一等肃毅伯。
输出:
输出: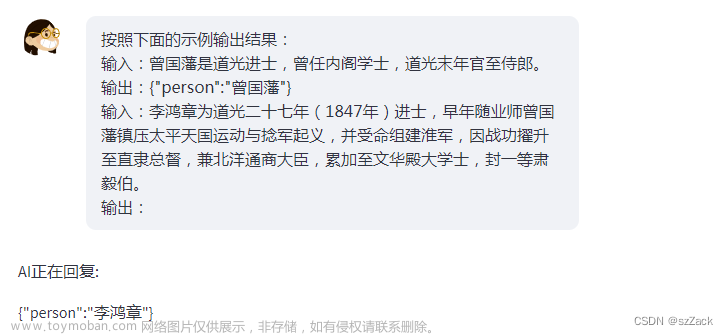
情感分类
- 示例
输入:
按照下面的示例输出结果:
输入:今天天气太差了,不舒服
输出:{"情感":"负面"}
输入:明天要出去玩,太好了
输出:
输出:
多伦对话管理
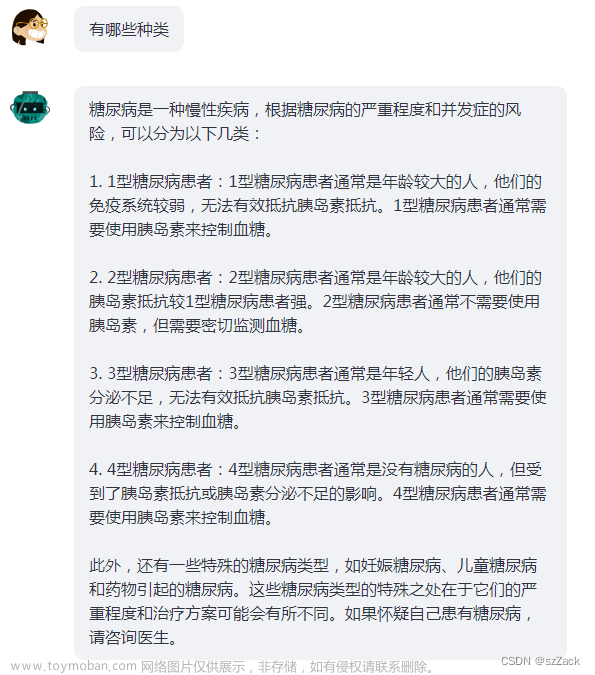
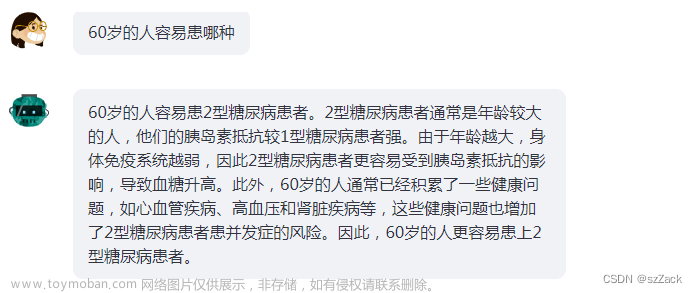

知识图谱
- 示例

- 示例
较为复杂的推理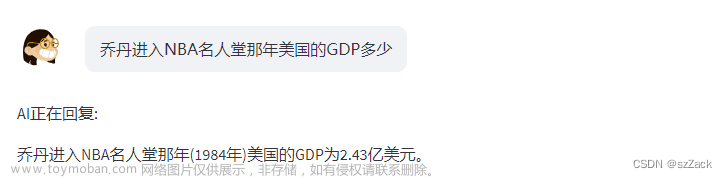
复杂推理还是有些问题: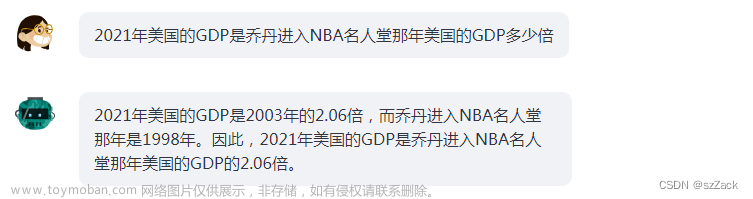
数据不完整: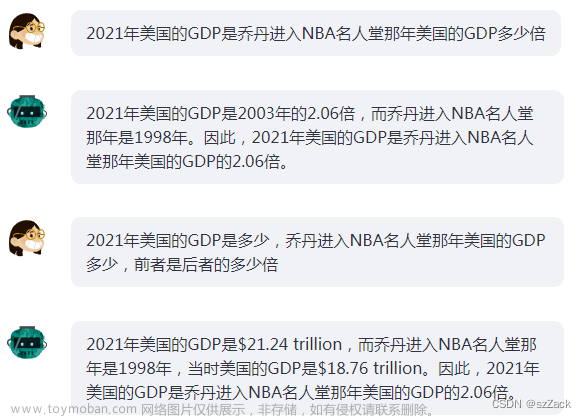 文章来源:https://www.toymoban.com/news/detail-694208.html
文章来源:https://www.toymoban.com/news/detail-694208.html
总结
总体看来,LLM 在零样本的情况下, 选择合适的prompt就能实现很多传统NLP任务。
LLM 尤其是现在的多模态模型,是真正通向通用人工智能的基石。文章来源地址https://www.toymoban.com/news/detail-694208.html
到了这里,关于【AI实战】大语言模型(LLM)有多强?还需要做传统NLP任务吗(分词、词性标注、NER、情感分类、知识图谱、多伦对话管理等)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!