每一种算法都最好看完第一篇再去找要看的博客,因为这样会帮你梳理好思路,看接下来的博客也就更轻松了。当然,我也会尽量在写每一篇时都可以让不懂这个算法的人也能边看边理解。
1、动规思路简介
动规的思路有五个步骤,且最好画图来理解细节,不要怕麻烦。当你开始画图,仔细阅读题时,学习中的沉浸感就体验到了。
状态表示
状态转移方程
初始化
填表顺序
返回值
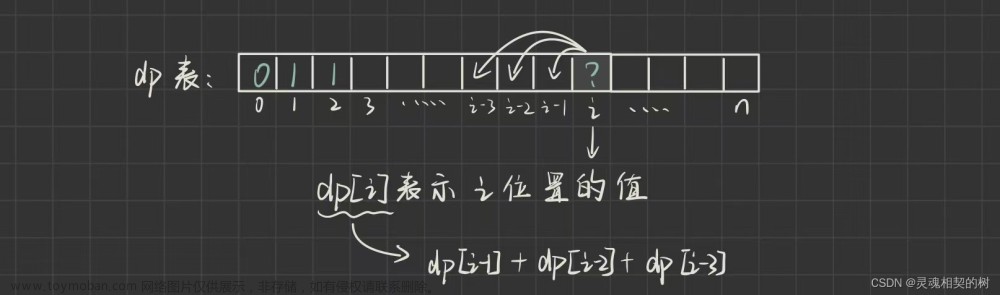
动规一般会先创建一个数组,名字为dp,这个数组也叫dp表。通过一些操作,把dp表填满,其中一个值就是答案。dp数组的每一个元素都表明一种状态,我们的第一步就是先确定状态。
状态的确定可能通过题目要求来得知,可能通过经验 + 题目要求来得知,可能在分析过程中,发现的重复子问题来确定状态。还有别的方法来确定状态,但都大同小异,明白了动规,这些思路也会随之产生。状态的确定就是打算让dp[i]表示什么,这是最重要的一步。
状态转移方程,就是dp[i]等于什么,状态转移方程就是什么。像斐波那契数列,dp[i] = dp[i - 1] + dp[i - 2]。这是最难的一步。一开始,可能状态表示不正确,但不要紧,大胆制定状态,如果没法推出转移方程,没法得到结果,那这个状态表示就是错误的。所以状态表示和状态转移方程是相辅相成的,可以帮你检查自己的思路。
初始化,就是要填表,保证其不越界。像第一段所说,动规就是要填表。比如斐波那契数列,如果要填dp[1],那么我们可能需要dp[0]和dp[-1],这就出现越界了,所以为了防止越界,一开始就固定好前两个值,那么第三个值就是前两个值之和,也不会出现越界。
填表顺序。填当前状态的时候,所需要的状态应当已经计算过了。还是斐波那契数列,填dp[4]的时候,dp[3]和dp[2]应当都已经计算好了,那么dp[4]也就出来了,此时的顺序就是从左到右。
返回值,要看题目要求。
2、第N个泰波那契数列
1137. 第 N 个泰波那契数

泰波那契数列从T0开始,而不是从1开始,这也是和斐波那契数列不同的点,但本质上思路都很相似。接下来要用动态规划来解决问题。
在这个题目中,我们让dp表的每一个元素都存储一个泰波那契数列,0下标对应T0,1下标对应T1。为什么要确定成这样的状态?题目要求拿到Tn的值,并且也存在T0,和数组下标一致,那么我们最好就把所有的数都填上,然后n作为下标,dp[n]一下子就能拿到结果。
根据上面的解析,我们这样写
int tribonacci(int n) {
//1. 状态表示: dp[i]就是第i个泰波那契数
//2. 状态转移方程: 题目给了,Tn+3 = Tn + Tn+1 + Tn+2
//处理边界情况,n如果小于3,那么只能取0, 1, 2,也可以走下面循环,但不如创建dp表之前就返回对应的值,减少空间消耗
if(n == 0) return 0;
if(n == 1 || n == 2) return 1;
vector<int> dp(n + 1);
dp[0] = 0, dp[1] = dp[2] = 1;//3. 初始化
for(int i = 3; i <= n; i++)
{
dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3];//4. 填表顺序,也体现了状态转移方程
}
return dp[n];//5. 返回值
}
这道题还可以优化一下空间。动规里要优化空间通常用滚动数组。当一个状态仅需要前面若干个状态来确定时,就可以用滚动数组。N^2的空间复杂度可以优化成N。当dp[3]确定后,我们让前四个值设为abcd,起初a是dp[0],b是dp[1],c是dp[2],d是dp[3],要算dp[4]的时候,就让abcd往后挪一位,也就是a是dp[1],d是dp[4],然后d = a + b + c,求出dp[4],算dp[5]的时候,还是一样的操作,让a来到dp[2]的位置,d则是dp[5]。这几个变量我们可以创建一个小数组来存储,也可以就创建四个变量。当开始滚动时,我们让a = b, b = c, c = d这样就能滚动了,但不能反向赋值,也就是c = d, b = c, a = b因为b要的是c之前的值,而c已经被赋值成d了,所以不行。使用变量来求值后,我们就可以不需要dp表了,只用四个变量来求出结果
int tribonacci(int n) {
//1. 状态表示: dp[i]就是第i个泰波那契数
//2. 状态转移方程: 题目给了,Tn+3 = Tn + Tn+1 + Tn+2
//处理边界情况,n如果小于3,那么只能取0, 1, 2,也可以走下面循环,但不如创建dp表之前就返回对应的值,减少空间消耗
if(n == 0) return 0;
if(n == 1 || n == 2) return 1;
int a = 0, b = 1, c = 1, d = 0;//3. 初始化
for(int i = 3; i <= n; i++)
{
d = a + b + c;//4. 顺序
a = b; b = c; c = d;//循环结束后,d就是最终的值
}
return d;//5. 返回值
}
3、三步问题
面试题 08.01. 三步问题

可1可2还可3,这个状态转移方程应当如何算?先不要着急,一步步看题。根据题目,我们可以知道状态是到达i位置时,总共有几种方式,dp[i]记录着方式的个数。接下来就是找状态转移方程。虽然题目有三种计算,但我们不妨算几个值来看看,n = 1,2,3,4时,分别是1,2,4,7,如果仔细去加每一个n值的方法个数,会发现每一个n值就是前面3个n值的和,比如1 +2 + 4 = 7,所以这个题是有规律的,那么它的状态转移方程就是dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3]。从1开始,dp[1],dp[2],dp[3]就分别初始化为1,2,4。填表顺序就是从左到右。返回值就是dp[n]。
由于本题中数目会过大,要取模,如果加完3个数再取模会不通过,要加完2个数就取模,然后再整体取模。
int waysToStep(int n) {
if(n == 1 || n == 2) return n;
if(n == 3) return 4;
const int MOD = 1e9 + 7;
vector<int> dp(n + 1);
dp[1] = 1, dp[2] = 2, dp[3] = 4;
for(int i = 4; i <= n; i++)
{
dp[i] = ((dp[i - 1] + dp[i - 2]) % MOD + dp[i - 3]) % MOD;
}
return dp[n];
}
当然这个题也可以空间优化,和上一个题一样。
int waysToStep(int n) {
if(n == 1 || n == 2) return n;
if(n == 3) return 4;
const int MOD = 1e9 + 7;
int a = 1, b = 2, c = 4, d = 0;
for(int i = 4; i <= n; i++)
{
d = ((a + b) % MOD + c) % MOD;
a = b; b = c; c = d;
}
return d;
}
4、使用最小花费爬楼梯
746. 使用最小花费爬楼梯

10,15,20,当你在10的位置,你会花费10块钱,往后走一次或者两次,当你在15的位置,你会花费15块钱,向后走一次或两次。但给的数组中最右边的元素不是楼顶,所有元素都是楼梯,楼顶在最后一个元素的下一个位置,比如示例1,在15的位置,花费15块钱,一次性跨2个楼梯,就到达了楼顶。
这道题的状态表示是什么样的?像一维dp数组,根据以上两道题来看,都是以i位置结尾来做状态表示,这道题也是一样,计算到i位置处最少需要的钱,所以dp[1],dp[2]就是到达1,2位置时最少的花费。
状态转移方程如何确定?看到现在,我们可以总结出一个规律,利用之前或者之后的状态,推导出dp[i]的值,比如dp[i]由dp[i - 1],dp[i - 2]等或者dp[i + 1], dp[i + 2]来确定。这道题来看,dp[i]要么从i - 1处走1步到达i,要么i - 2处走2步到达i,两种情况比较大小来得到dp[i]的值,而dp[i - 1],dp[i - 2]又是之前推导过来的。所以dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2])。
初始化的时候,要不越界,需要初始化最前面的2个位置,根据题目,我们可以从0位置或者1位置开始,那么这两个位置就初始化成0即可。填表顺序是从左到右。返回值是dp[i]。
根据以上分析,写出代码
int minCostClimbingStairs(vector<int>& cost) {
int n = cost.size();
vector<int> dp(n + 1);
for(int i = 2; i <= n; i++)
{
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
return dp[n];
}
这道题还可以用另一种状态表示来写。上面是yii位置为结尾,这次是以i位置为起点。此时的dp[i]是从i位置出发,到达楼顶的最小花费,这个i从0开始。
这次的状态转移方程如何确定?从i位置出发,可以走一步,走两步,所以也分成2种情况,走一步,从i + 1位置到终点;走两步,从i + 2位置到终点,然后再算i + 1或者i + 2处算最小花费。第一种情况是dp[i + 1] + cost[i],第二种情况是dp[i + 2] + cost[i],去两者之小。
这次的初始化应该如何做?上一次是取dp[i - 1]和dp[i - 2],我们初始化最左边的两个值,现在是取dp[i + 1]和dp[i + 2],那最容易确定的就是最右边的两个值,dp[n - 1]和dp[n - 2],它们俩就分别是花费当前位置的钱即可。这次的填表顺序就是从右到左。返回值则是dp[0]和dp[1]的最小值,楼顶是n位置处。
思路其实相似,不过就是反过来了。这次开辟的数组就不用n + 1了,之前我们需要算到dp[n],而现在n - 1处是起始点。
int minCostClimbingStairs(vector<int>& cost) {
int n = cost.size();
/*vector<int> dp(n + 1);
for(int i = 2; i <= n; i++)
{
dp[i] = min(dp[i - 1] + cost[i - 1], dp[i - 2] + cost[i - 2]);
}
return dp[n];*/
vector<int> dp(n);
dp[n - 1] = cost[n - 1], dp[n - 2] = cost[n - 2];
for(int i = n - 3; i >= 0; i--)
{
dp[i] = min(dp[i + 1], dp[i + 2]) + cost[i];//因为都要加一个cost[i],所以就提出来
}
return min(dp[0], dp[1]);
}
5、解码方法
91. 解码方法


这道题还是可以用上面的分析。状态表示我们先表示为以i位置结尾。字符串有i个字符,i位置的数字应当是从第一个字符开始到i位置的字符总共能编码的个数,所以dp[i]是以i位置为结尾时,解码方法的总数。
状态转移方程如何确定?根据上面那些题的分析,我们知道要根据最近的一步,来划分问题,i位置处自己可能可以编码,i - 1和i位置处也可能可以编码,而由于是以i位置为结尾,所以i和i + 1就不管,不能i - 2位置组合起来编码是因为字母所代表的数字最多是两位数,所以这点就可以帮助我们确定方程。
现在是两种情况,dp[i]单独解码,dp[i- 1]和dp[i]组合解码。每个情况都有成功失败,如果dp[i]可以解码成功,那就说明从0到i - 1位置的所有编码方案后面加上一个i位置的字符就可以了,所以此时dp[i]的方案数就是dp[i - 1]的方案数。如果dp[i]单独编码失败,那么前面所有的可解码方案就全失败了,那么就是0了。
dp[i - 1]和dp[i]解码,也有成功失败。如果成功,那么i - 1处字符对应的数字乘10 + i处字符对应的数字应当>= 10 && <= 26,因为题目中说了不可能出现06这种情况,所以只能是一个正常的两位数,10及以上。把i - 1和i看作一个整体,这时候就相当于dp[i - 2]的所有方案后面都加上两个字符即可,所以就是dp[i - 2]的方案数。如果失败,也是一样,前面的全失败了,为0。
根据以上的分析,dp[i] = dp[i - 1] + dp[i - 2],但这两个并不是一定都加得上,可能为0。
初始化应当如何做?有两个方法。dp[i]既然是由前两个位置决定的,那么初始化时就得考虑一下dp[0]和dp[1],dp[0]要么是1,要么是0,它只有一个字符,dp[1]代表2种字符,2个字符都能单独解码是1种情况,2个字符组合才能解码是另一种情况,满足其中一个就是1,两个都满足就是2,都不满足就是0,所以dp[1]是0,1,2三个情况。
填表顺序是从左到右。而返回值,我们要解码到最后一个位置,所以应当是dp[n - 1]。
int numDecodings(string s) {
int n = s.size();
vector<int> dp(n);
dp[0] = s[0] != '0' ? 1 : 0;//判断dp[0]能否单独解码
if(n == 1) return dp[0];//处理边界情况
if(s[0] != '0' && s[1] != '0') dp[1] += 1;//判断dp[0]dp[1]能否都单独解码
int t = (s[0] - '0') * 10 + s[1] - '0';
if(t >= 10 && t <= 26) dp[1] += 1;//判断dp[0]dp[1]组合能否解码
for(int i = 2; i < n; i++)
{
if(s[i] != '0') dp[i] += dp[i - 1];//判断能否单独解码
int t = (s[i - 1] - '0') * 10 + s[i] - '0';//判断能否组合解码
if(t >= 10 && t <= 26) dp[i] += dp[i - 2];
}
return dp[n - 1];
}
现在写一下另一种初始化方法。上面的代码可以看出,有段代码是重复的
if(s[0] != '0' && s[1] != '0') dp[1] += 1;//判断dp[0]dp[1]能否都单独解码
int t = (s[0] - '0') * 10 + s[1] - '0';
if(t >= 10 && t <= 26) dp[1] += 1;//判断dp[0]dp[1]组合能否解码
if(s[i] != '0') dp[i] += dp[i - 1];//判断能否单独解码
int t = (s[i - 1] - '0') * 10 + s[i] - '0';//判断能否组合解码
if(t >= 10 && t <= 26) dp[i] += dp[i - 2];
之前的dp表示[0, n - 1],现在我们给它扩充一个元素,变成[0, n],那么之前的dp[1],就相当于新表的dp[2],之前的dp[0]就是现在的dp[1],之前的dp[n - 1]就是新的dp[n],新表的dp[0]就是一个虚拟节点,用来更方便的初始化,下面能看到它起作用的地方。这个方法有一些注意的点。一个是要保证字符串中1位置处的字符能对应到dp[2],也就是保证映射关系;另一个就是新表中的dp[0],如何初始化它来保证结果正确。
我们要让循环从i = 2开始,使用相同的判断方法,dp[1]不是问题,而dp[0],对于dp[2]来说,就是dp[i - 2],那么如果原字符串中0和1位置,也就是新表的1和2位置处的字符能够组合编码,那就应该+dp[i - 2],也就是+1,所以dp[0]应当初始化为1。
字符串从0位置开始走,判断0位置的字符,对应的新表的1位置,i是在新表中走的,也就是此时i = 1,那应当判断s[1 - 1]的位置,也就是s[i - 1]的位置,就可以保证映射关系了。
int numDecodings(string s) {
int n = s.size();
//优化
vector<int> dp(n + 1);
dp[0] = 1;
dp[1] = s[1 - 1] != '0' ? 1 : 0;//s[0]
for(int i = 2; i <= n; i++)
{
if(s[i - 1] != '0') dp[i] += dp[i - 1];//判断能否单独解码
int t = (s[i - 2] - '0') * 10 + s[i - 1] - '0';//判断能否组合解码
if(t >= 10 && t <= 26) dp[i] += dp[i - 2];
}
return dp[n];
}
6、动规分析总结
状态的表示通常是以某个位置为结尾或者起点
状态转移方程的确定需要分析最近的一步
初始化的第二种方法是设立虚拟节点,注意事项就是如何初始化虚拟节点的数值来保证填表的结果是正确的,以及新表和旧表的映射关系的维护
填表顺序要看分析而决定文章来源:https://www.toymoban.com/news/detail-694325.html
结束。文章来源地址https://www.toymoban.com/news/detail-694325.html
到了这里,关于C++算法 —— 动态规划(1)斐波那契数列模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!