Title: Occlusion Handling in Generic Object Detection: A Review
Abstract: The significant power of deep learning networks has led to enormous development in object detection. Over the last few years, object detector frameworks have achieved tremendous success in both accuracy and efficiency. However, their ability is far from that of human beings due to several factors, occlusion being one of them. Since occlusion can happen in various locations, scale, and ratio, it is very difficult to handle. In this paper, we address the challenges in occlusion handling in generic object detection in both outdoor and indoor scenes, then we refer to the recent works that have been carried out to overcome these challenges. Finally, we discuss some possible future directions of research.
Keywords: Object detection; Indoor scene; Outdoor scene; Generative Adversarial Network; Amodal Perception; Instance segmentation; Compositional models
题目:通用对象检测中的遮挡处理研究综述
摘要:深度学习网络的强大力量已经促进了物体检测的巨大发展。在过去的几年里,对象检测框架在准确性和效率方面都取得了巨大的成功。然而,由于几个因素,它们的能力与人类相去甚远,遮挡就是其中之一。由于遮挡可能发生在不同的位置、比例和比例,因此处理起来非常困难。在本文中,我们解决了室外和室内场景中通用对象检测中遮挡处理的挑战,然后我们参考了最近为克服这些挑战而开展的工作。最后,我们讨论了未来可能的研究方向。
关键词:对象检测、室内场景、室外场景、生成对抗性网络、情感感知、实例分割、合成模型
1.引言
作为人类,即使在物体部分可见的各种条件下,我们也能快速准确地检测和识别周围环境中的物体。我们的大脑能够补偿不可见的部分,并将可见区域联系起来以识别物体[1]。计算机离完成这项任务还有很长的路要走。然而,自从深度神经网络的发展和大量数据的可用性以来,在计算机视觉领域,特别是物体检测领域,已经取得了显著的进展。对象检测包括两个子任务:对象的分类和定位。
目标检测器分为两类:一阶段检测和两阶段检测器。后者使用区域建议网络来产生感兴趣区域(ROI),并应用深度神经网络将每个建议分类为类别。然而,第一种类型将对象检测视为一个回归问题,因此它使用统一的框架来学习类概率和边界框的坐标。这使得一阶段检测器与同类探测器相比速度更快。最有效的检测器是Faster RCNN[2]、SSD[3]和YOLO[4]。
然而,由于杂波、成像条件、大量物体类别和实例以及遮挡等诸多因素,物体检测是一项具有挑战性的任务 [5]。遮挡发生在物体被同一类型的物体遮挡时,这称为类内遮挡;或者物体被固定元素或其他类型的物体遮挡时,这称为类间遮挡。在部分遮挡的情况下,与人类相比,基于深度神经网络的分类器的鲁棒性较差[6],并且会恶化检测器的性能[7]。因此,遮挡处理已被广泛研究,如行人检测[8][9][10][11]、物体跟踪[12][13][14]、人脸检测[15][16]、立体图像[17]、汽车检测[18][19]、语义部分检测[20][21]等。然而,由于物体类别和实例的巨大差异,从单张静态图像中进行通用物体检测的遮挡处理要困难得多。
然而,由于物体类别和实例的巨大差异,从单张静态图像中进行通用物体检测的遮挡处理要困难得多。遮挡也在室内场景中进行了研究,但有几个问题使其具有挑战性。首先,家具的刚性限制了从不同角度全面观察物体。其次,没有用于遮挡的真实室内场景的大规模数据集。最后,与在户外发现的物体相比,物体的大小相对较小,这意味着当它们被遮挡时,可见区域可能没有足够的信息来识别。因此,重新生成被遮挡的对象变得更加困难。
文献中有几篇关于物体检测的综述和调查论文。其中最新的是刘等人在[5]中的工作,该工作调查了基于深度学习的通用对象检测的可用数据集和方法。此外,Chen等人[22]提出了小物体检测的挑战和解决方案,赵等人[23]对最近用于物体检测的深度学习方法进行了回顾和分析。
然而,据我们所知,近期还没有关于遮挡处理的文献综述。鉴于在一般物体检测中处理遮挡问题的重要性,我们对最近在这一领域所做的工作进行了回顾。然后,我们提出了一些未来研究的方向。这篇综述是关于静止图像中的对象检测进行的。因此,其他应用程序中的遮挡处理不在本工作的范围内。
2. 物体检测的应用
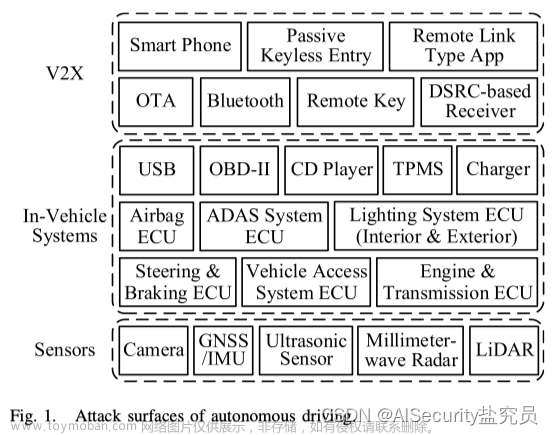
物体检测在户外场景中的两个重要应用是自动驾驶[24][25]和物体跟踪。在自动驾驶汽车中,汽车需要具有检测道路上各种物体的能力,如其他车辆、行人、交通和路标、障碍物等[26]。另一方面,在室内环境中检测物体最明显的应用是“提取和交付”任务,这是服务机器人的主要功能[27]。机器人不仅需要识别周围的物体以找到它要寻找的物体,而且还必须对它所处的空间区域进行语义标记并对其进行分类,这是另一种称为场景理解和分类的应用[28]。
3. 数据集
自深度神经网络发展以来,数据集一直是计算机视觉领域进步的关键因素。用于通用对象检测的最广泛使用的数据集是PASCAL VOC[29]、MS COCO[30]、ImageNet[31]和Open Images[32]。刘等人[5]对这些数据集进行了深入的讨论。为了避免重复[5]中已经解释的内容,我们将重点关注室内环境中图像的数据集。
Ehsani等人介绍了一个可用的数据集,在[33]中称为DYCE数据集,该数据集包含合成遮挡对象。这些照片是在室内拍摄的。共有11个合成场景,包括5个客厅和6个厨房。每个场景有60个对象,每个图像的可见(至少10个可见像素)对象数为17.5。
此外,作者在[34]中提出了TUT室内数据集,该数据集包含2213个帧,包含来自7个类的4595个对象实例。每帧的大小为1280×720。但是实例的数量在类之间并不相等。单个类的最大实例数为1684个,最小实例数为81个。数据集具有不同的背景、光照条件、遮挡和高度的类间变化。对象检测器(使用ResNet-101[35]的Faster RCNN)被训练为生成一半数据集的建议标注。而另一半则由人工手动标注。因此,在研究中提出了一种更快的边界框标注。
为了有效地训练真实室内场景中的遮挡模型,我们需要一个大规模的全标注数据集,该数据集具有场景中被遮挡对象的地面实况标签。不幸的是,目前还没有这样的数据集。
对于室外场景,Qi 等人[36] 从 KITTI[37] 中创建了 KINS 数据集,用于模态实例分割。该数据集包含模态实例分割掩码和相应的遮挡顺序。三位专家标注者对每张图像进行标注。通过众包解决模糊问题,以确保遮挡区域的标记一致。
除了前面提到的数据集,还有其他数据集,如ScanObjectNN(包含用CAD数据创建的室内场景)[38]、BigBird[39]、NYC v2[40]、Places[41],以及[42]中提到的用于3D室内重建和同步定位与映射(SLAM)的数据集。但这些都超出了本次审查的范围。
4. 户外场景中的遮挡处理
在本节中,我们将讨论户外环境中遮挡处理的挑战以及每种挑战的解决方案。
A.数据收集
由于对象类别和实例的多样性,收集和标记数据集似乎不可能对每个类别中的每个实例进行可能的遮挡。因此,许多研究依赖于合成数据集或自动生成的示例:
1) 生成对抗网络(GAN):自Goodfellow等人[43]发明以来,生成对抗网络已被广泛研究以训练生成模型。该框架有两个同时训练的对抗性网络,即生成器和鉴别器。生成器被训练来学习将样本从随机潜在空间映射到数据,而鉴别器被训练来区分真实样本和生成的(假)样本。生成器的目标是通过制作看起来尽可能与真实数据相似的样本来欺骗鉴别器。为了确保生成的数据来自特定的类或数据,可以使用条件生成对抗性网络(cGAN)[44]。
王等人[45]认为,即使是大规模数据集也无法覆盖潜在的遮挡和变形。因此,他们提出了一种策略,使用两个对抗性网络(如“图1”所示)从COCO数据集中生成快速RCNN难以分类的示例。第一个对抗性网络是学习如何遮挡对象的对抗性空间丢弃网络(ASDN),第二个网络是学习怎样旋转对象部分以产生变形的对抗性时空变换器网络(ASTN)。通过针对快速RCNN同时训练这两个网络,后者学会了处理遮挡和变形。
2) 非模态感知:是当物体的某些部分被遮挡时,推断物体物理结构的能力。最近的研究如[46][47][36]已经将其用于分割。模态分割对遮挡处理非常重要,因为通过比较非模态和模态分割遮挡,可以推断出遮挡的存在、程度、轮廓和部位 [46]。
尽管如此,非模态实例分割的数据准备难度使其成为一项具有挑战性的任务。因此,Li和Malik[46]通过在模态掩模中添加合成遮挡来创建模态训练数据。首先,随机裁剪具有至少一个前景对象实例的图像块。然后,它被从其他图像中提取的随机对象实例覆盖。覆盖对象的随机位置和比例可确保与底部面片的轻度遮挡。然后通过使用原始模态分割掩模将每个块中与掩模一致的像素标记为正(属于对象),负(背景)和未知(属于其他对象)。最终,原始模态掩膜包含合成图像中被遮挡对象的原始可见部分。这就成为了复合批次的真正的非模态分割掩码。生成的合成图像和模态掩码用于训练 CNN,以获得原始掩码。在有真实遮挡的图像上进行测试时,即使该模型是在合成数据上训练出来的,它也能有效预测模态遮挡。

B.遮挡检测
遮挡处理中的一个关键问题是确定所讨论的对象是否被其他对象遮挡。很难判断图像中观察到的物体外观是物体的真实形状还是遮挡的结果。
Qi等人在[36]中提出了具有遮挡分类分支的多级编码(MLC)网络,以提高推断遮挡部位的模态感知能力。MLC有两个分支:提取和组合。在第一个分支中,提取对象的抽象全局特征。若要为可见和不可见零件生成掩膜,组合分支会融合全局特征和特定局部特征。同时,遮挡分类预测了遮挡的存在,增强了网络的畸形感知。在KINS数据集上的实验结果表明,使用该模型可以增强非模态和in-modal实例分割。
C.生成遮挡区域
处理遮挡的一个主要挑战是确定如何恢复对象的不可见部分。目前有三种解决方案:
1) 非模态实例分割:除了先前在非模态实例分割方面的工作外,Follmann等人[48]提出了一种端到端可训练的非模态实例分割模型,称为Occlusion R-CNN(ORCNN)。该模型是Mask R-CNN的扩展,具有非模态掩码头和遮挡掩码头,用于在单个正向过程中同时预测对象实例的amodal、in-modal和遮挡掩码(如“图2”所示)。作者还介绍了一个新的D2S amodal数据集和COCOA-cls。第一个基于D2S[49],后者源自[47]的COCOA数据集。数据扩充用于在D2S amodal数据集中包括中度到重度遮挡的对象。结果验证了该模型在没有任何阿莫达尔注释数据的情况下在D2S阿莫达尔上获得了有竞争力的结果,甚至在COCOA cls数据集上的性能优于其基线。
2) 部分完成:Zhan等人[50]开发的一个自监督框架,用于部分完成被遮挡对象,以实现场景去遮挡。该框架取决于部分完成概念的两个原则。首先,在一个对象被几个其他对象遮挡的情况下,可以在一次涉及一个对象的情况下逐步执行部分完成。其次,通过有意修剪被遮挡的对象并训练网络来重新创建未修剪的对象,网络可以学习部分完成被遮挡的物体。作者通过两个网络实现部分完成:部分完成网络掩码(PCNet-M)和部分完成网络内容(PCNet-C)。当第一网络用于生成与遮挡对象相对应的遮挡对象的遮挡掩膜时,第二网络为掩膜提供RGB内容。该框架在KINS[36]数据集和COCOA[47]上进行了测试,结果表明,尽管该框架在没有基本事实遮挡排序和阿莫达尔掩码的情况下进行了训练,但其性能与完全监督基线相似。
3) 上下文编码器:Pathak等人[51]提出了一种卷积神经网络(CNN),该网络能够基于上下文生成图像的缺失补丁。所提出的模型具有编码器和解码器。当编码器从图像的上下文产生紧凑的潜在特征表示时,解码器可以从产生的表示产生图像的缺失部分。由于其无监督性质,该模型必须学习图像的语义,并为缺失部分生成合理的假设。因此,训练模型以减少基于上下文捕捉缺失部分的结构的重建损失,以及从分布中选择特定模式的对抗性损失。结果表明,该模型能够比其基线更好地修复图像的语义部分。但是,模型的性能会随着高级纹理区域而恶化。
D.遮挡对象检测
最先进的对象检测器和基于深度神经网络的分类器的准确性随着部分遮挡而降低[52][7]。因此,许多研究都集中在提高当前方法识别和定位被遮挡物体的能力上。我们将其分为两类:
1)分类(Classification):根据Fawzi和Frossard[53],深度卷积神经网络(DCNN)在部分遮挡下不具有鲁棒性。
DeVries 和 Taylor [54] 认为,CNN 容易过度拟合,导致在闭塞情况下泛化效果不佳。 因此,他们为 CNN 提出了一种简单的正则化技术--Cutout,即用部分闭塞图像来增强训练数据。对于每张输入图像,都会随机选择一个像素点作为固定大小的零掩码的中心点,以剔除图像的邻近部分。然而,增加训练数据会导致训练时间和成本的增加 [7]。
另一方面,Xiao等人[55]提出了TDAPNet来解决DCNN中的两个问题:过拟合和特征提取过程中的遮挡污染。他们提出了TDAPNet,这是一个由三部分组成的深度网络:原型学习、部分匹配和自上而下的注意力机制。前两部分有助于解决第一个问题,而第三部分处理第二个问题。在DCNN提取特征后,应用原型学习。然后,部分匹配通过仅比较可见部分来比较特征和原型,从而去除不相关的特征向量。最后,自上而下的注意力调节通过过滤遮挡引起的不规则激活,在遮挡物周围产生更纯粹的特征。通过去除较低层中被遮挡的特征,模型对遮挡变得更加稳健。但基于Kortylewski等人[7]对真实遮挡图像所做的实验,该模型不如人工遮挡模型可靠。

5. 室内场景中的遮挡处理
由于室内场景结构、杂波、遮挡和照明的布局复杂多样,与室外场景相比,物体检测更具挑战性[42]。在本节中,我们介绍了室内环境中物体遮挡处理的挑战,以及文献中解决这些挑战的现有方法:
A.场景结构
室内元素和家具的布局和设计,在某些情况下会阻止获得物体的全景,甚至部分视图。例如,在橱柜里的其他物体后面寻找一个隐藏的盒子。由于橱柜的静态和刚性,不可能从不同的角度观察物体。为了解决这个问题,有两种解决方案:
1)转盘(Turntable):用于通过将物体放置在圆桌上来避免遮挡,并允许安装在机器人上的相机绕着桌子旋转,以捕捉不同视点的物体[64]。不同的视图用于提供对象的下一个最佳视图(NBV),以对不可见部分进行建模。
2)交互式操作(Interactive manipulation):[65]的作者认为,在杂乱的场景中找到被遮挡的物体不能通过使用单个图像来完成。因此,使用手腕安装RGB和深度相机的机械臂,应用主动感知和交互式感知来寻找感兴趣的对象。虽然主动感知是指移动相机从多个视点捕捉对象,但交互式感知可以通过交互更好地理解场景。然后使用基于强化学习的控制算法和颜色检测器来寻找特定颜色的目标对象。虽然在仿真过程中,主体会使用分离式抓手进行训练,但在现实世界中,某些末端执行器姿势在运动学上并不可行。
Dogar等人[66]还指出,搜索对象的问题需要感知和操纵来移动可能隐藏目标对象的对象。他们提出了两种搜索算法,贪婪搜索算法考虑了对象之间的可见性和可访问性关系;以及利用期望时间来找到目标作为优化准则的连通分量算法。
Krainin等人[67]使用机械臂在静态相机前对物体进行交互式操作来生成物体的3D模型。
尽管在适用的某些情况下,上述技术可能是必要和必要的,但它们需要一个受控的环境设置,这是不现实的,在现实世界中并不总是可能的。

B.训练数据
没有可用于室内场景的对象遮挡的大型数据库。
Georgakis等人[27]认为,创建包含室内环境所有可能性的注释数据集,如视角、照明条件、遮挡和杂乱,既费力又耗时。同时,经过训练的模型在各种环境和背景下的泛化能力较差。因此,他们提出了一种从另外两个数据集生成新数据集的方法:GMU Kitchens和Washington RGB-D Scenes v2。合成图像是通过在多个位置、比例、姿势和位置叠加对象实例来生成的。
另一方面,Dwibedi等人[68]提出了一种简单的剪切粘贴方法,以最小的工作量合成训练数据。他们的关键直觉是基于最先进的检测器,如Faster RCNN,这些检测器主要基于局部区域的特征,而不是基于全局的特征。该方法会自动剪切对象实例并将其粘贴到随机背景上。然而,为了避免细微的像素伪影,训练算法被迫忽略伪影,转而专注于对象外观。
C.恢复遮挡区域
遮挡可能发生在不同的规模、位置和级别。因此,很难训练模型来重新生成对象的不可见区域。以下方法用于分割和重新生成对象的遮挡区域:
1)GAN: Ehsani等人[33]使用GAN来解决生成对象遮挡区域的问题。他们提出的名为SeGAN的模型首先分割不可见的部分,然后通过绘画产生其外观。基于输入图像和对象的可见区域的分割,该模型生成RGB图像,其中重建对象的不可见区域。为此,该模型由两个部分组成:分割部分是一个CNN,它通过使用来自可见区域的信息来输出对象的掩码,绘制部分使用cGAN来生成对象的遮挡部分。SeGAN模型的损失函数是分割和绘画损失的组合。“图3”显示了SeGAN模型的架构。作者在他们的照片逼真的DYCE数据集上报告了SeGAN与其基线相比更好的结果。
2)语义分割(Semantic segmentation):Purkait等人[69]提出,可以实现一组指示每个像素的可见性或不可见性的语义标签,而不是为图像中的每个像素分配一个标签。他们的工作使用了一个从SUNCG数据集扩展而来的合成数据集来预测可见区域和遮挡区域的语义类别。他们使用U-Net架构[70],该架构具有带有ReLU的编码器和解码器,但在最后一层中,S形激活函数与分组softmax一起使用。从编码器到解码器之间存在跳过连接。
将具有交叉熵损失的网络的结果与利用分组语义损失的网络进行比较,后者在预测被遮挡像素的语义标签方面产生了更好的结果。然而,由于训练集是合成的,因此所提出的方法的实现局限于找到这种合成模型的环境。在现实世界场景中,必须考虑对遮挡部分的某些估计。
3)实例分割(Instance segementation):通过扩展Mask RCNN架构,Wada等人[71]提出了一种用于遮挡分割的模型,他们称之为“重新查找Mask RCNN”。为了训练他们的模型,作者创建了一个由物体实例创建的一堆物体的合成图像数据集。作者没有将实例遮挡分割视为单一类(仅可见)问题,而是将其视为多类(可见、遮挡)问题。它们还考虑掩膜之间的关系,以正确推断实例的遮挡状态。为了学习关系,将从Mask RCNN预测的实例掩码转换为密度图,以预测第二阶段(重新查找阶段)中的实例掩码。作为输出,模型预测三个掩膜:可见掩膜、遮挡掩膜和其他掩膜(不属于对象)。
所提出的系统在一堆对象中进行了实际拾取任务的测试,报告的结果表明了该系统的有效性。然而,该系统需要一个具有对象的遮挡状态及其相应标签和掩膜的所有可能性的数据集,实现这一点的努力随着对象数量的增加呈指数级增加。

4)背景信息(Contextual information):Hueting等人[72]介绍了SEETHROUGH模型,该模型利用了室内场景中物体共现的规律性。通过将共现信息视为显式先验,即使在严重的类间或类内遮挡的情况下,也可以预测对象的身份、位置和方向。作者在真实的室内注释图像上训练神经网络来提取2D关键点。提取的关键点被馈送到3D候选对象生成阶段。然后,使用从大型3D场景数据库中提取的对象同现统计来解决3D对象建议之间的选择问题。重复该过程以使用已经发现的对象的位置来递增地检测具有低关键点响应的附近候选。结果表明,即使在中等或重度遮挡的场景中,SeeThrough也能比其两个基线Faster-3D RCNN和SeeingChairs更准确地检测椅子。
D. 讨论和未来方向
基于GAN、amodal分割和组成模型的报告结果,我们看到了这些技术在遮挡检测和处理方面的巨大潜力。当小物体检测中没有足够的GAN时,GAN已被有效地用于增强特征[73],并用于再生被遮挡的人脸[74]。
然而,在遮挡处理方面仍然存在一系列关键问题,这些问题可能成为该领域未来的研究方向。
首先,没有大规模的数据集可以用于室内环境中的对象遮挡。目前可用的大多是合成数据集,这意味着当模型在这样的数据集上训练时,它可能无法很好地推广到现实世界场景中。此外,户外场景的可用数据集缺乏对遮挡区域的足够注释。
其次,为了对对象应用去遮挡,我们首先确定对象是否被遮挡是至关重要的。尽管amodal分割可以用来解决这个问题,但如果注释不正确或不充分,这种解决方案可能无效。
最后,使用真实世界的训练数据而不是合成数据,提高当前模型在不同遮挡程度下重新生成被遮挡对象的能力。文章来源:https://www.toymoban.com/news/detail-694829.html
E. 结论
自从基于区域的网络发明以来,对象检测已经走过了漫长的道路。它们不仅比以前更准确,而且还实现了实时结果。尽管在一般和特定对象类别检测方面有大量的研究,但一般对象检测中的遮挡处理仍然相对未被探索。许多突出的模型在物体被遮挡时无法检测到物体。在这篇综述中,我们介绍了最新的工作,这些工作致力于解决遮挡问题,并在许多情况下重新生成对象。如果我们想在通用对象检测中克服遮挡处理的挑战,我们还讨论了未来的研究方向。文章来源地址https://www.toymoban.com/news/detail-694829.html
到了这里,关于论文阅读--通用对象检测中的遮挡处理研究综述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!