《slog正式版来了:Go日志记录新选择![1]》一文发布后,收到了很多读者的反馈,意见集中在以下几点:
基于slog如何将日志写入文件
slog是否支持log轮转(rotation),如果slog不支持,是否有好的log轮转插件推荐?
如何与kafka集成
日志输出有哪些最佳实践
这篇文章就是对上述问题进行补充说明的,供大家参考,希望能给大家带去帮助。
1. 输出日志到文件
之所以《slog正式版来了:Go日志记录新选择![2]》一文中使用的例子[3]都以os.Stdout(标准输出)为log输出目的地,主要是因为基于云原生微服务架构模式下,应用都跑在容器中(k8s[4]的pod中),基本都是将log输出到Stdout,而不会写入某个具体的本地文件。但如果应用是基于虚拟机或裸机部署,那么将日志写入文件仍然是第一选项。
其实,使用slog内置的TextHandler和JSONHandler可以非常方便的将结构化的日志写入文件,因为slog.NewXXXHandler函数的第一个参数是一个io.Writer,这样通过将一个文件的描述符传递给NewXXXHandler,即可创建一个向文件写入日志的Logger。我们看下面示例代码:
//slog-in-action/log2file/main.go
package main
import (
"log/slog"
"os"
)
func main() {
f, err := os.Create("foo.log")
if err != nil {
panic(err)
}
defer f.Close()
logger := slog.New(slog.NewJSONHandler(f, nil))
slog.SetDefault(logger)
slog.Info("greeting", "say", "hello")
}在这个示例中,我们创建了目标日志文件foo.log,并将其描述符(*os.File)传给了NewJSONHandler函数,通过这种方式创建出来的Logger输出的日志内容将会被写入foo.log文件中:
$go run main.go
$cat foo.log
{"time":"2023-09-02T19:38:45.441782+08:00","level":"INFO","msg":"greeting","say":"hello"}这种方式应该可以满足大多数gopher的需求了。
2. 日志文件的管理
一旦将日志写入文件,后续就要对日志文件进行管理,比如:日志文件的轮转、压缩、归档以及定期清理(腾出磁盘空间)等。
关于如何对日志文件管理的方案大致有这么几种。
第一种是借助外部工具,比如在主流的Linux发行版上都有一个logrotate[5]工具程序,应用程序可以借助该工具对应用输出的日志进行rotate、压缩、归档和删除历史归档日志,这样可大幅简化应用的日志输出逻辑,应用仅需要将日志输出到一个具名文件中即可,其余都交给logrotate处理。关于如何使用logrotate,我在《写Go代码时遇到的那些问题[第1期]》[6]中有详细说明,感兴趣的朋友可以移步阅读一下,这里就不赘述了。
第二种就是log包自身支持。大多数log包都没有将日志文件管理作为自己的功能feature,slog包也是如此,没有原生提供此功能。
第三种就是通过支持log包相关插件接口的一些扩展包来支持。lumberjack[7]就是这样的一个插件包,它支持与很多知名的log包集成在一起实现对log文件的管理,比如logrus、zap等。我曾在《写Go代码时遇到的那些问题[第3期] 》[8]和《一文告诉你如何用好uber开源的zap日志库》[9]两篇文章中分别讲解了logrus和zap与lumberjack集成在一起对日志文件进行管理的方法。如果你对lumberjack不是很熟悉,建议你在继续阅读下面内容之前,温习一下这两篇文章。
在这一篇文章中,我们用示例来简单说说如何将slog与lumberjack集成以实现对log文件的管理功能。看下面示例:
//slog-in-action/lumberjack/main.go
package main
import (
"log/slog"
"gopkg.in/natefinch/lumberjack.v2"
)
func main() {
r := &lumberjack.Logger{
Filename: "./foo.log",
LocalTime: true,
MaxSize: 1,
MaxAge: 3,
MaxBackups: 5,
Compress: true,
}
logger := slog.New(slog.NewJSONHandler(r, nil))
slog.SetDefault(logger)
for i := 0; i < 100000; i++ {
slog.Info("greeting", "say", "hello")
}
}在这个示例中,我们看到:*lumberjack.Logger实现了io.Writer接口,因为只要将实例化后的*lumberjack.Logger以参数形式传入NewXXXHandler即可完成slog与lumberjack的集成。至于日志文件的管理行为则是通过lumberjack.Logger实例化过程的字段赋值来定制的。比如这里我们指定了目标日志文件名(Filename)为"./foo.log",指定当文件达到1M字节时(MaxSize)进行rotate,对rotate后的文件进行压缩(Compress),最多保留5个归档文件(MaxBackups)以及归档文件最多保存3天(MaxAge)等。
运行上述示例程序后,我们将在当前目录想得到如下文件:
$go run main.go
$ls
foo-2023-09-02T08-24-20.854.log.gz foo-2023-09-02T08-24-20.979.log.gz foo-2023-09-02T08-24-21.098.log.gz go.mod main.go
foo-2023-09-02T08-24-20.918.log.gz foo-2023-09-02T08-24-21.041.log.gz foo.log go.sumfoo.log是当前正在写入的日志文件,而其他带有时间戳、以gz为后缀的文件则是归档文件。由于有了lumberjack对日志文件的管理,我们就不用再担心日志文件size过大、归档文件过多没有清理而导致的磁盘被占满的问题了。
注:lumberjack.Logger的各个属性字段的配置要根据你的应用实际输出日志的情况、本地磁盘可用空间来确定。
3. 与kafka集成
在我们团队的一个生产项目中,日志是不落盘而直接写入kafka的,关于这个事情,我在《Go社区主流Kafka客户端简要对比》[10]一文中也曾提到过,并给出了基于zap和不同kafka客户端实现向kafka写入日志的方案。
slog与kafka集成的思路也是类似的,不同的是定制KafkaHandler的方法,基于slog,我们要让KafkaHandler实现slog.Handler接口。在《slog正式版来了:Go日志记录新选择![11]》一文中,我们给出了一个向channel写入结构化日志的示例[12],KakfaHandler完全可以借鉴其中的ChanHandler,也是通过字节切片来承接JSONHandler写出的日志,不同的是将写入Channel改为通过kafka client写入Kafka! 在这里我就不给出KakfaHandler的实现了,这个作业留给大家,记得实现KafkaHandler后,使用slog/slogtest对其正确性做一个测试!
注:注意在实现KakfaHandler时,考虑goroutine并发使用同一个基于KafkaHandler创建的slog.Logger的情况,也就是字节切片的并发访问和共享的问题。
4. 日志输出的实践建议
在《聊聊Go应用输出日志的工程实践[13]》一文中,我聊了一些在日常使用log时遇到的问题、解决方法以及Go团队对log支持上的问题。log/slog的正式发布,一定程度上解决或改善了那篇文章中提到的部分问题。
此外,在读者关心的日志输出内容方面有哪些实践建议,我也总结了以下几点:
1). 选择合适的日志级别。常见的日志级别包括 DEBUG、INFO、WARNING和ERROR。在生产环境中,我们通常将日志级别设置为WARNING或ERROR,最低是info,不能再低了,避免打印过多日志以影响应用性能。
2). 日志级别要支持热更新。在系统出现异常时,如果要做在线调试,支持热更新的日志级别就特别重要,我们可以在一个调试时间窗口将日志级别下调至info或debug,这样可以抓取到一段时间的详细日志,以供调试和诊断参考。
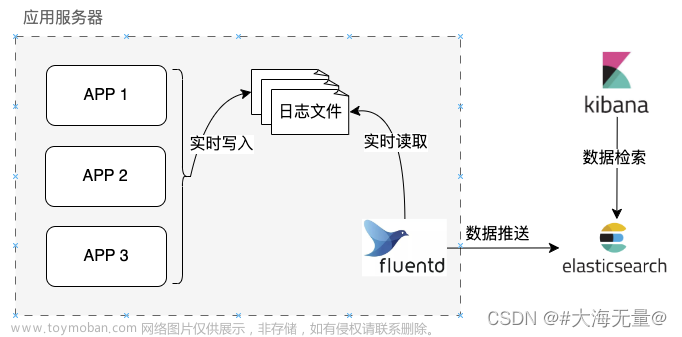
3). 优先选结构化日志。相对于文本日志更适合人类阅读,结构化日志更适于机器解析、索引和查询。大多数正常情况下,我们是不会去看日志的,日志都会被汇集到集中日志中心存储、管理并索引(比如常见的ELK方案、近来的grafana的PLG方案(Promtail, Loki and Grafana)[14]等),以便于后续做查询和展示。针对这样的情况,显然结构化日志更适合。
4). 无论使用结构化还是文本形式日志,日志格式都要清晰易读。每条日志至少要打印时间、日志级别、事件源、事件详情等信息,对于固定的字段,要用属性(attribute)来设置,以提高输出性能。
5). 考虑到排查和诊断业务问题,通常会为日志添加上下文信息。比如:在日志中增加关于当前用户、请求ID等上下文信息等。但不应该在日志中输出用户的隐私数据等敏感信息,要么移除,要么做打码处理。
6). 考虑到监控和告警的需要,有些时候我们会对错误日志进行监控,可能会在日志中放置一些具有监控意义的特征字段。
7). 对于日志写入文件的情况,就如本文前面提到的,要考虑日志文件的管理:设置合理的分割轮转日志文件策略以及日志文件的归档管理,避免日志文件的无限增长对磁盘带来的影响。
日志输出内容没有“固定标准”,需根据大家实际所处的业务环境以及相关要求确定。
5. 小结
本文是《slog正式版来了:Go日志记录新选择![15]》一文的“补充篇”,主要对将slog日志如何写入文件以及对文件的管理(轮转、归档、清理等方案)做了说明。对于将slog与外部系统(如kafka)进行集成的思路做了点拨,最后还给出了一些关于日志输出实践方面的参考意见,希望能帮助到大家!
本文涉及的示例代码可以在这里[16]下载。
“Gopher部落”知识星球[17]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[18]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) - https://gopherdaily.tonybai.com
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite
Gopher Daily归档 - https://github.com/bigwhite/gopherdaily

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
slog正式版来了:Go日志记录新选择!: https://tonybai.com/2023/09/01/slog-a-new-choice-for-logging-in-go
[2]slog正式版来了:Go日志记录新选择!: https://tonybai.com/2023/09/01/slog-a-new-choice-for-logging-in-go
[3]使用的例子: https://github.com/bigwhite/experiments/tree/master/slog-examples-go121
[4]k8s: https://tonybai.com/tag/k8s
[5]logrotate: https://github.com/logrotate/logrotate
[6]《写Go代码时遇到的那些问题[第1期]》: https://tonybai.com/2018/01/13/the-problems-i-encountered-when-writing-go-code-issue-1st
[7]lumberjack: https://github.com/natefinch/lumberjack
[8]《写Go代码时遇到的那些问题[第3期] 》: https://tonybai.com/2018/04/06/the-problems-i-encountered-when-writing-go-code-issue-3rd
[9]《一文告诉你如何用好uber开源的zap日志库》: https://tonybai.com/2021/07/14/uber-zap-advanced-usage
[10]《Go社区主流Kafka客户端简要对比》: https://tonybai.com/2022/03/28/the-comparison-of-the-go-community-leading-kakfa-clients
[11]slog正式版来了:Go日志记录新选择!: https://tonybai.com/2023/09/01/slog-a-new-choice-for-logging-in-go
[12]向channel写入结构化日志的示例: https://github.com/bigwhite/experiments/tree/master/slog-examples-go121/demo4
[13]聊聊Go应用输出日志的工程实践: https://tonybai.com/2022/03/05/go-logging-practice
[14]grafana的PLG方案(Promtail, Loki and Grafana): https://www.cncf.io/blog/2020/07/27/logging-in-kubernetes-efk-vs-plg-stack/
[15]slog正式版来了:Go日志记录新选择!: https://tonybai.com/2023/09/01/slog-a-new-choice-for-logging-in-go
[16]这里: https://github.com/bigwhite/experiments/tree/master/slog-in-action
[17]“Gopher部落”知识星球: https://public.zsxq.com/groups/51284458844544文章来源:https://www.toymoban.com/news/detail-696489.html
[18]链接地址: https://m.do.co/c/bff6eed92687文章来源地址https://www.toymoban.com/news/detail-696489.html
到了这里,关于slog实战:文件日志、轮转与kafka集成的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!