0目录
| 1.linux 安装hive 2.hive入门 3.hive高级语法1 |
1.linux 安装hive
| 先确保linux虚拟机中已经安装jdk;mysql和hadoop 并可以成功启动hadoop和mysql |
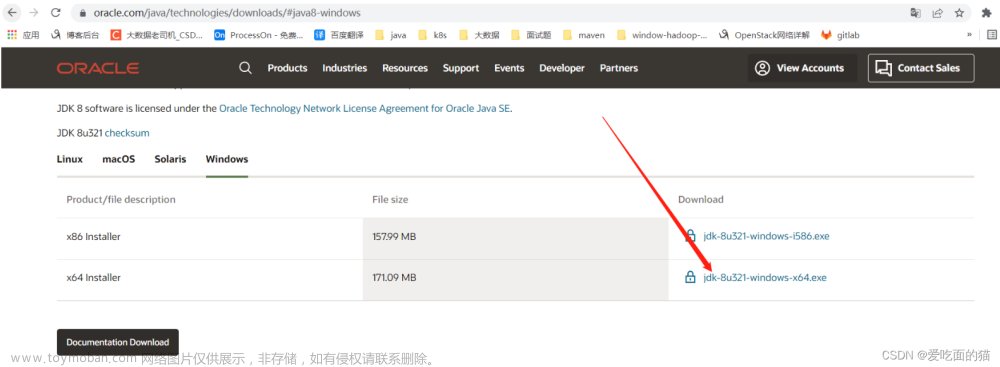
| 下载hive对应版本到opt/install目录下并解压到opt/soft目录下
|
| 重命名 hive312
|
| 配置profile 文件,加入hive环境变量 vim /etc.profile
更新资源 source /etc/profile |
| 拷贝mysql connector 到cd/opt/soft/hive312/lib目录下
|
| 进入 cd/opt/soft/hive312/conf目录 新建vim ./hive-site.xml 编辑
|
| cd /opt/soft/hadoop313目录下查找juava*开头的文件
|
| cd /opt/soft/hive312/lib目录下删除
|
| 拷贝juava* (确保版本相同) cp /opt/soft/hadoop313/share/hadoop/common/lib/guava-27.0-jre.jar ./ |
| 初始化hive hive初始化 [root@kb129 hive312]# schematool -dbType mysql -initSchema
|
| 输入hive命令
|
| show databases;
|
| 启动metastore和hiveserver2
|
| 与数据库建立连接
|













2.hive基本语法
| 查看数据库
|
| 选择数据库
|
| 创建表和添加数据
|
| 强制删除某个数据库
|
| 产看表信息
|
| 覆盖原有数据
|
| 重命名表名和添加和替换列名
|
| 创建内部表
|
| 指定上传路径(两种方式)location(hdfs路径) 和load data local inpath(虚拟机路径)
|
| 分区表(手动分区,根据一个字段名)
|
| 分区表(手动分区,根据多个字段名) ;添加和删除分区
|
| 动态分区 创建studenttp 导入数据
|
| 创建studenttp1 指定分区字段(age和gender)
|
| 插入数据完成
|
| 创建外外部表
路径为hdfs路径
|
| 内部表和外部表区别 删除内部表时,表结构和文件同时被删除,外部表只删除表结构 |
| 练习(内部表,路径是虚拟机系统路径)
|
| 外部表(路径是hdfs路径)
记得上传 cd/opt/kb23路径下 hdfs dfs -put ./employee.txt /user/hive/warehouse/kb23hivedb.db/stu/employeefile
|
| union拼接查询结果
|
| 写法2
|
| 将r1的结果作为r2查询的表(类似sqi子查询)
|
| 子查询(先性别男然后名字will)
结果
|





























3.hive高级查询1
|
|
| 删除、修改表
|
| 分桶表
|
| 创建分桶表
Hdfs查看
随机
|
| 创建视图
|
| 侧视图
|
|
|
| CTE查询
|
| 关联查询
|
| Union
|
| hive四大排序
|
| 补充in和exists
exists的返回值是true和false |
| wordCount案例 新建表结构和加载数据
|
|
|
| Case when语句
|
| 列转行
|
| 练习 新建App表和userapp表
|
|
|
































 文章来源:https://www.toymoban.com/news/detail-696557.html
文章来源:https://www.toymoban.com/news/detail-696557.html
到了这里,关于Hadoop Hive入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!