当前,大规模预训练语言模型的强大对话问答、文本生成能力,将自然语言处理(NLP)的研究和应用推向了新一轮的热潮。NLP是计算机科学、人工智能和语言学等学科交叉的前沿领域。NLP的应用和研究范围非常的广泛,个人是没有找到那种特别好的、详细且成体系的文档的。
本文根据自然语言处理主要的几个子领域及其包含的主要任务简单总结了一份NLP的学习路线,也可以说是知识体系。后续个人的技术文章也将主要围绕NLP去展开,大致也会按照这个路线去记录相关的基础知识、方法、技术、工具及实践案例等等。所以本文不仅仅是整理了一份学习路线,更是个人未来很长一段时间的学习规划。
如果你也对NLP感兴趣,欢迎关注“九陌斋”了解后续更多精彩内容:微信公众号【九陌斋】、腾讯云开发者社区、CSDN、个人博客网站(www.jiumoz.com)
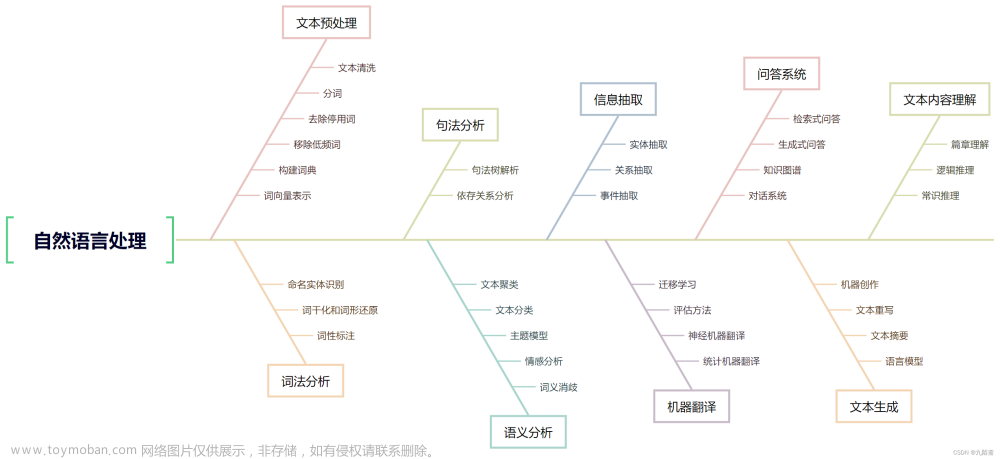
下面的鱼骨图就是个人整理的NLP相关的一个学习路线,某种意义上可以理解为一个知识体系,本文将尽量结合示例简单的去描述一下这些基本概念。
其实关于’NLP知识体系’或者’NLP学习路线’的相关文章是很多的,网上一搜就有不少。但是很多内容就是围绕学术角度展开的,不太契合个人的一个理解和规划,所以简单总结出了以下的一个简单的结构,当然这也并不是完全完善的一个体系。很多子任务的归属也不是特别的严谨。
简要概述
NLP概念
NLP也就是自然语言处理,是一门研究人与计算机之间用自然语言进行有效通信的学科。自然语言处理融合了语言学、计算机科学和数学等多个学科的理论和方法。NLP的工作原理是先接收由人类使用自然语言发送的信息,再通过基于概率的算法进行翻译和转换,最后输出可以被计算机理解和执行的结果。NLP的两个核心任务是自然语言理解(NLU)和自然语言生成(NLG)。自然语言理解指让计算机能够理解和解释人类的语言,而自然语言生成则是将非语言格式的数据转换成人类的语言格式,以达到人机交流的目的。
NLP发展历程
自然语言处理(NLP)的发展可以追溯到上个世纪50年代,经历了多个阶段和技术革新,以下是NLP发展的详细历程:
-
1950-1960年代:规则导向时期
在这个时期,NLP主要采用基于规则的方法,通过手工编写规则和语法来实现文本分析和处理。最早的成功案例是Shannon’s maze-running mouse(1950)和Weizenbaum的ELIZA人工对话系统(1964),它们使用强调规则的方法来通过模拟解决问题或产生输出。
-
1970-80年代:统计分析和语料库时期
随着计算机技术的发展,研究者们开始使用大规模的文本语料库,并采用统计分析等方法,所谓“从数据中学习”。在这一时期,基于语料库的方法和统计学习方法得到了广泛应用,并提出了重要的技术和算法,如隐马尔科夫模型、最大熵模型和条件随机场等。
-
1990年代:基于知识和混合方法时期
在这个时期,研究人员将基于规则和基于统计两种方法相结合,形成了混合方法。此外,还涌现出基于知识的方法和深度学习算法,如人工神经网络和支持向量机等。同时,标注语料库的构建和共享也成为了NLP发展的重要趋势,如Penn Treebank和WordNet等。
-
2000年代:深度学习时期
随着深度学习技术的崛起,NLP进入了新的发展时期。深度学习技术可以自动学习特征和模式,并以端到端方式解决多项任务,如文本分类、情感分析、机器翻译和问答系统等。重要的深度学习算法包括卷积神经网络(CNN)、长短时记忆网络(LSTM)和变压器网络(Transformer)等。
-
2010年代至今:预训练和语境理解时期
在这个时期,研究人员发现使用预训练模型能够显著提高NLP任务的性能。这些模型通常使用大规模无监督语料库进行预训练,在具体的任务中进行微调。此外,语境理解也成为了当前NLP领域中的重要研究方向,在这个方向上涌现了BERT、GPT等重要模型和技术。
NLP主要子领域
这一块简单的记录一下各个子任务的概念,更多内容还是要关注后续每个任务的详细博客;
文本预处理
-
文本清洗(Text Cleaning)
文本清洗指对原始文本进行处理以去除噪声和不相关的信息。常见的清洗操作包括去除HTML标签、特殊字符、标点符号、多余的空格等。文本清洗的目的是为后续处理提供更干净、更规范化的数据。
示例:假设我们有以下原始文本:
<div class="intro">Natural language processing (NLP) is a field of artificial intelligence which</div> focuses on enabling computers to understand and interpret human language.我们可以进行如下文本清洗操作:
- 删除HTML标签:
Natural language processing (NLP) is a field of artificial intelligence which focuses on enabling computers to understand and interpret human language. - 删除括号内的内容:
Natural language processing is a field of artificial intelligence which focuses on enabling computers to understand and interpret human language. - 将大写字母转换为小写:
natural language processing is a field of artificial intelligence which focuses on enabling computers to understand and interpret human language. - 删除句子末尾的句号:
natural language processing is a field of artificial intelligence which focuses on enabling computers to understand and interpret human language
- 删除HTML标签:
-
分词(Tokenization)
分词指将文本分割成离散的单词或标记的过程。分词是NLP中的重要步骤之一,为后续处理提供了基本的单位。
示例:假设我们有以下原始文本:
I love natural language processing.我们可以进行如下分词操作:
- 将文本分割成单词:
["I", "love", "natural", "language", "processing"]
- 将文本分割成单词:
-
去停用词(Stopword Removal)
去停用词指移除在文本处理中无实际意义或频率很高的常见词汇,如介词、冠词、连词等。这些词对于某些任务来说可能没有太多信息量,需要被移除。
示例:假设我们有以下原始文本:
I love natural language processing.我们可以进行如下去停用词操作:
- 移除停用词:
["love", "natural", "language", "processing"]
常见的停用词列表可以通过开源的NLP工具库(如NLTK)获得。
- 移除停用词:
-
移除低频词(Removing Low-Frequency Words)
移除低频词指移除在整个文本语料库中出现频率较低的单词,可以减少数据中的噪音和数据维度。一般通过设定一个阈值,移除在语料库中出现次数低于该阈值的单词。
示例:假设我们有以下原始文本:
I love natural language processing.如果我们将阈值设为2,则只有love和natural两个单词可以保留,而language和processing则会被移除。
-
构建词典(Building Vocabulary)
构建词典是为文本中的所有单词分配唯一的索引,以便后续进行处理和表示。一般通过遍历整个语料库,将每个单词与一个唯一的标识符(整数)相关联来构建词典。
示例:假设我们有以下原始文本:
I love natural language processing.我们可以进行如下构建词典操作:
- 构建的词典:
{"I": 0, "love": 1, "natural": 2, "language": 3, "processing": 4}
- 构建的词典:
-
词向量表示(Word Vector)
词向量表示是将文本中的单词转换为数值向量的过程。常见的词向量表示方法包括独热编码、词袋模型(Bag of Words)、词频-逆文档频率(TF-IDF)和词嵌入(Word Embedding)等。
示例:假设我们有以下原始文本:
I love natural language processing.我们可以进行如下词向量化操作:
- 词向量表示:
[[1, 0, 0, 0, 0], [0, 1, 0, 0, 0], [0, 0, 1, 0, 0], [0, 0, 0, 1, 0], [0, 0, 0, 0, 1]]
具体来说,独热编码表示每个单词位置上都是1,而其他位置上都是0;词袋模型表示每个单词出现的次数;TF-IDF表示单词出现的频率和它在整个语料库中出现的频率之间的关系;词嵌入通过计算单词之间的相似性来表示它们在向量空间中的位置。
- 词向量表示:
词法分析
-
命名实体识别(Named Entity Recognition)
命名实体识别是一种文本处理任务,用于识别出文本中具有特殊意义的命名实体,比如人名、地名、组织机构名等。这有助于我们从文本中提取关键信息,并理解实体之间的关系。
示例:假设我们有以下文本:
苹果公司成立于1976年,创始人是史蒂夫·乔布斯、史蒂夫·沃兹尼亚克和罗南·韦恩。在命名实体识别中,我们可以将文本中的命名实体识别为以下类别:
- 组织机构名:
苹果公司 - 人名:
史蒂夫·乔布斯、史蒂夫·沃兹尼亚克、罗南·韦恩
通过命名实体识别,我们可以识别文本中重要的实体信息。
- 组织机构名:
-
词干化和词形还原(Stemming and Lemmatization)
词干化和词形还原是将单词转化为其词干或基本形式的过程,以消除不同词形对文本分析的影响。词干化是一种较为简单的处理方式,只取词的基本部分,而词形还原则考虑了上下文和词性等因素。
示例:假设我们有以下文本:
Cats are running in the park, and they love to play with mice.在词干化和词形还原中,我们可以将文本中的单词进行如下处理:
- 词干化(Stemming)结果:
cat, are, run, in, the, park, and, they, love, to, play, with, mice - 词形还原(Lemmatization)结果:
cat, be, run, in, the, park, and, they, love, to, play, with, mouse
通过词干化和词形还原,我们可以将不同词形的单词统一为其基本形式,减少文本中的噪音和冗余。
- 词干化(Stemming)结果:
-
词性标注(Part-of-Speech Tagging)
词性标注是为文本中的每个单词赋予一个词性标签,用于表示单词在句子中的语法角色。标注的词性包括名词、动词、形容词等,对语法分析和其他NLP任务具有重要作用。
示例:假设我们有以下文本:
Cats are running in the park.词性标注可以为句子中的每个单词分配以下标签:
- 名词(Noun):
Cats, park - 动词(Verb):
are, running - 介词(Preposition):
in - 冠词(Article):
the
通过词性标注,可以更好地理解句子的语法结构和单词在句子中所扮演的角色。
- 名词(Noun):
句法分析
-
句法树解析
*句法树(syntactic tree)*解析是将句子分析为树状结构的过程,其中每个节点代表一个短语或单词,边表示它们之间的语法关系。我们可以通过逐步拆分句子来构建句法树,直到达到最小的短语和单词。
例如,考虑句子:“The cat is sitting on the mat.”(这只猫正坐在垫子上。)通过句法树解析,我们可以生成以下句法树:
sitting / \ is on / \ cat mat / The在句法树中,最顶层的节点是整个句子的根节点,而每个单词则成为树的叶子节点。边表示短语之间的语法关系,例如动词"sitting"与其主语"is"之间的关系,以及动词"sitting"与介词短语"on the mat"之间的关系。通过句法树解析,我们能够清晰地看到每个单词之间的层次关系和结构。
-
依存关系分析
依存关系分析是描述句子中单词之间依存关系的过程。每个单词都被看作一个节点,而边则表示这些单词之间的依存关系,即一个单词是另一个单词的修饰或从属关系。
以句子:“The cat is sitting on the mat.”(这只猫正坐在垫子上。)为例,通过依存关系分析,我们可以得到以下依存关系图
sitting / \ is mat / | cat on | The在这个依存关系图中,每个单词都表示为一个节点,而边表示单词之间的依存关系。例如,动词"sitting"依赖于"is",表示它是"is"的补足语;名词"mat"依赖于介词"on",表示它是"on"的修饰词;名词"cat"依赖于冠词"The",表示它是"The"修饰的名词。
通过依存关系分析,我们可以更好地理解句子中单词之间的修饰和从属关系,帮助我们解释和理解句子的语法结构
语义分析
-
文本聚类(Text Clustering)
文本聚类是将一组文本数据分成不同簇的过程,使得同一簇内的文本具有相似的特征或主题。文本聚类的目标是在不需要先验标签的情况下,发现隐藏在文本数据中的潜在结构或关系。常用的方法包括
层次聚类、k-means聚类和谱聚类等。假设我们有一组新闻文章,涵盖体育、科技、政治等不同主题。我们可以使用文本聚类算法,如k-means聚类,对这些文章进行聚类。通过计算文章之间的相似度,将相似主题的文章归为一类。例如,将所有体育类的文章聚为一簇,将科技类的文章聚为另一簇,以此类推。
-
文本分类(Text Classification)
文本分类是将未知文本自动分类到预定义类别的任务。文本分类的目标是训练一个分类器,以学习文本特征和类别之间的关系,并能对新文本进行准确的分类。常用的方法包括
朴素贝叶斯、支持向量机(SVM)、深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)等。假设我们要将一组电影评论分为正面评价、负面评价和中立评价。我们可以使用文本分类算法,如基于机器学习的朴素贝叶斯分类器。通过对标注好的训练数据进行学习,该分类器能够根据评论的特征将其归类到合适的类别中。然后,对于未标记的评论,我们可以使用这个分类器进行分类,确定其评价种类。
-
主题模型(Topic Modeling)
主题模型是一种从文本数据中发现隐藏主题的方法。它通过将文档集合中的词汇进行统计分析,推断每个主题的单词分布以及每篇文章属于每个主题的概率。常用的主题模型包括
Latent Dirichlet Allocation (LDA)和Probabilistic Latent Semantic Analysis (PLSA)等。假设我们有一组新闻文章,我们希望了解这些文章中的主题。通过应用主题模型(如LDA),我们可以发现每个主题的单词分布以及每篇文章属于每个主题的概率。这样一来,我们可以根据每个主题的特征来判断它是否与某个领域或话题相关。
-
情感分析(Sentiment Analysis)
情感分析是对文本进行情感倾向性分析的任务,即判断文本是正面情感、负面情感还是中立情感。情感分析的目标是识别和量化文本中的情感极性。常用的方法包括
基于规则的方法、基于机器学习的方法(如朴素贝叶斯、支持向量机)和深度学习模型(如循环神经网络、Transformer)等。假设我们有一组社交媒体上的用户评论,我们希望了解用户对于某款产品的情感倾向。通过情感分析,我们可以分析评论中的情感词汇出现频率,并根据情感词汇的极性判断评论的情感倾向。例如,如果评论中出现了积极的情感词汇频率较高,我们可以判断该评论是正面情感。
-
词义消歧(Word Sense Disambiguation)
词义消歧是指确定一个词在给定上下文中的确切含义的任务。由于许多词汇具有多个意义,根据上下文来推断词汇的正确语义对于理解文本非常重要。常用的方法包括
基于词典的方法、基于语境的方法和基于语义相似度的方法等。假设我们有一段文本:“钢琴家在舞台上奏出美妙的乐曲。”这里的“钢琴家”可能指音乐家,也可能指一种昆虫。通过词义消歧,我们可以考虑上下文信息,例如“奏出美妙的乐曲”,从而确定“钢琴家”的确切含义是指音乐家。
信息抽取
信息抽取在知识图谱构建和维护中扮演着重要的角色。
知识图谱是一种以图形结构存储和表示知识的方式,通过节点和边来表示实体和实体之间的关系。
信息抽取可以帮助从文本中自动抽取出结构化的知识,并将其填充到知识图谱中。
-
实体抽取
实体抽取是指从给定的文本中识别和提取出具有特定类型或类别的命名实体。命名实体可以是人物、地点、组织机构、日期、时间、货币、产品等等。实体抽取任务的目标是在文本中定位并标记出这些实体。
假设我们有一段新闻报道的文本:“谷歌总部位于美国加利福尼亚州的硅谷,成立于1998年。” 对于实体抽取任务,我们的目标是识别出文本中的两个实体:
谷歌(组织机构)和美国加利福尼亚州的硅谷(地点)。 -
关系抽取
关系抽取是指从文本中提取出不同实体之间的关系或相互作用。这些关系可以是预定义的,也可以是根据特定语境和任务进行自定义的。关系抽取任务的目标是识别和捕捉实体之间的关联关系,并将其表示为结构化的形式。
继续以新闻报道的文本为例:“谷歌总部位于美国加利福尼亚州的硅谷,成立于1998年。” 对于关系抽取任务,我们的目标是识别出
谷歌和硅谷之间的总部所在地关系(located_in)。 -
事件抽取
事件抽取是指从文本中提取出描述事件或动作的信息。它涉及到识别出文本中的事件 trigger(触发词)以及与该事件相关的参与者、时间、地点等要素。事件抽取任务的目标是对事件进行分析和归纳,从而获得对文本中事件内容的理解。
假设我们有这样一句话:“约翰昨天去了一家餐厅,点了一份披萨。” 对于事件抽取任务,我们的目标是识别出
“去”这个触发词,并抽取出相关的参与者(约翰、一家餐厅)、时间(昨天)和动作(去)。
机器翻译
-
迁移学习
迁移学习是指将在一个任务上学到的知识或经验应用于另一个相关任务中的机器学习方法。在机器翻译中,迁移学习可以通过在一个源语言-目标语言翻译任务上训练模型,并将学到的知识迁移到其他语言对的翻译任务上,以提高翻译质量和效果。
假设我们已经在英法翻译任务上训练了一个基于神经网络的机器翻译模型,并取得了不错的结果。现在我们希望在英德翻译任务上获得良好的性能。通过迁移学习,我们可以使用已训练好的模型作为初始模型,在英德翻译任务上进行微调,以利用已有的知识和经验。
-
评估方法
评估方法是用来衡量机器翻译系统输出结果质量的方式。评估方法通常包括自动评估和人工评估两种方式。自动评估方法利用指标或计算机算法来度量翻译结果与参考翻译之间的差距。人工评估则由人类评价者根据语义准确性、流畅性等标准对翻译结果进行打分。
常用的自动评估方法包括BLEU(双语评估下的词汇匹配度)、METEOR(基于单词、短语、句子层面的多种标准)和TER(短语错误率)等。而人工评估方法通常通过人类评价者对翻译结果进行质量评判,例如使用专业译员进行评审或借助调查问卷获得用户反馈。
-
神经机器翻译
神经机器翻译(NMT)是使用神经网络模型来实现机器翻译的方法。它通过将源语言句子作为输入,直接生成目标语言句子作为输出,无需像传统的基于规则或特征的方法那样进行翻译过程中的中间表示。
在神经机器翻译中,通常使用编码器-解码器结构,其中编码器将源语言句子编码为一个固定长度的向量表示,解码器根据该向量生成目标语言句子。通过大规模并行处理和端到端训练,神经机器翻译在一些语言对上取得了很好的翻译效果。
-
统计机器翻译
统计机器翻译(SMT)是一种基于概率和统计建模的机器翻译方法。它利用大规模的双语语料库和统计模型来建立源语言和目标语言之间的映射关系。
在统计机器翻译中,常见的模型包括基于短语的模型和基于句法的模型。基于短语的模型将输入句子分割为若干短语,然后进行翻译和重组;而基于句法的模型则利用句法树等结构信息进行翻译。统计机器翻译在过去几十年中一直是机器翻译领域的主流方法,但近年来逐渐被神经机器翻译所取代。
问答系统
-
检索式问答
检索式问答是指根据用户提出的问题,在事先构建好的知识库或文本语料库中快速查找与之匹配的答案并返回给用户的问答方式。通常会使用特定的搜索
算法和查询语句来实现问题与答案的匹配。假设有一个问题:“中国的首都是哪里?”对于这个问题,我们可以在事先构建好的地理知识库中进行检索,通过搜索“中国首都”相应的实体,返回正确的答案“北京”。
-
生成式问答
生成式问答是指根据用户提出的问题,利用自然语言处理技术在知识库和其他数据源中生成答案并返回给用户的问答方式。通常需要
对自然语言理解、语言生成、实体识别等多个模块进行深度学习和优化。假设有一个问题:“你见过克里斯蒂亚诺·罗纳尔多吗?”对于这个问题,我们需要识别问题中的实体“克里斯蒂亚诺·罗纳尔多”,并从多个数据源中获得相关信息,最终生成答案“是的,他是一位职业足球运动员,曾经效力于皇家马德里和曼联等多家豪门俱乐部。”
-
知识图谱
知识图谱是指以图形方式表示各种实体及其属性、关系以及其他语义信息的知识库。它是大规模语义网应用的核心技术之一,常用于自然语言处理、语义搜索等领域。
假设有一个问题:“马拉松比赛的历史起源是什么?”对于这个问题,我们可以从知识图谱中查找“马拉松”该实体,获取该实体的属性和关系信息,进而回答问题。
-
对话系统
对话系统是指与用户进行自然语言对话,根据用户提供的信息和语境上下文,提供相应的服务和解决方案的系统。通常需要涵盖
自然语言理解、对话管理、自然语言生成等多个方面的技术。假设有一个用户需要查询旅游信息,对话系统可以通过与用户交互来确定用户需求,例如通过意图识别确定用户想要查询的目的地、时间和住宿信息,然后返回相应的旅游方案和预订服务。
文本生成
-
机器创作
机器创作是指利用机器学习和自然语言处理技术,使机器能够生成各种形式的文本作品,如诗歌、小说、音乐等。机器通过学习大量的文本数据,并运用语言模型和创作算法,能够产生独立创作的文本内容。
假设我们有一个机器创作模型,经过训练后可以生成古诗。当用户提供一个主题“秋夜月”,机器创作系统可以生成以下句子:
“秋夜月悬空,寒风吹落杨梢。静夜思悠悠,一弯明月伴我闲游。” -
文本重写
文本重写是指利用自然语言处理技术,对已有的文本进行修改和改写,以达到更好的表达、改进语法或者简化复杂的句子结构等目的。重写后的文本保留了原始文本的主要信息,但具有更高的可读性和准确性。
假设我们有一段原始文本:“数字化技术正在深刻改变人们的生活,对各行各业产生了巨大的影响。”通过文本重写,可以改写成:
“数字化技术正深刻地改变着人们的生活,对各个行业都有巨大的影响。” -
文本摘要
文本摘要指的是从长篇文档中自动抽取或生成几句话,以概括出文档的主要内容。文本摘要通常需要考虑到文档的关键信息、重要事件、实体等,并生成简洁、准确的摘要内容。
假设我们有一篇长篇新闻报道,题目是“科学家发现新型治疗癌症的方法”。通过文本摘要技术,可以生成以下摘要:
“科学家近日发现一种新型的治疗癌症的方法,该方法基于基因编辑技术,有望在临床应用中取得重要突破。” -
语言模型
语言模型是利用统计和机器学习方法来建模自然语言序列的概率分布。它能够预测给定上下文的下一个词或短语,并根据已有的语言规则和训练数据对生成的文本进行评估。语言模型在文本生成、机器翻译、语音识别等任务中有广泛的应用。
假设我们有一个基于语言模型的文本生成系统。当用户输入一个句子的前半部分:“今天的天气非常”,语言模型可以预测并生成下一个词或短语,如“晴朗”,从而完成句子的生成:
“今天的天气非常晴朗。”
文本内容理解
-
篇章理解
篇章理解是指对一篇完整的文本进行整体的理解和分析,包括理解文本的结构、主题、段落之间的关系以及上下文的含义等。篇章理解需要考虑到文本的上下文信息,从而可以更好地把握文章的意义和目的。
假设我们有一篇文章描述了一个人的旅行经历。通过篇章理解,我们能够理解
这篇文章的结构,如开头介绍旅行的背景,中间叙述具体的旅行经历,最后总结旅行的感受和体验。 -
逻辑推理
逻辑推理是指根据已有的信息和逻辑规则,推出新的结论或判断。在文本内容理解中,逻辑推理可以帮助我们从文字中推断出隐含的信息、推理作者的观点或判断某个事件的因果关系等。
假设我们有一段文本:“小明喜欢吃苹果。他今天去了超市。”通过逻辑推理,我们可以得出结论:
“小明今天去超市的目的可能是买苹果。” -
常识推理
常识推理是基于人们对现实世界的常识和经验进行推理的过程。在文本内容理解中,常识推理能够帮助我们理解隐含的信息、填补文本中的间隙,以及根据常识来推理和理解文本中的事件和现象。
假设我们有一句文本:“他打开冰箱,拿出了一盒牛奶。”通过常识推理,我们可以得出结论:
“牛奶应该需要冷藏保存,所以它被放在冰箱里。”
*后续文章思路
后续文章,也就是后续在NLP这一块博主的行文蓝图,大家一定要关注啊!!!
-
需要掌握的基本技能
这一块也是针对后续的一些文章内容的,不是针对小白或者有一定了解的同学的;
主要是两方面:
首先就是编程基础,要对python有基本的概念,对其语法有一些了解;不能代码结构都看不懂,或者安装包都不会吧。
然后就是数据结构和算法,熟悉常见的数据结构,如列表、字典等,了解常见的算法,如查找、排序等。
-
大致的规划
后续的学习过程,主要还是针对案例的,基本上每篇文章应该都会有实践;
例如分词,可能会针对常见的包去做一些基本的学习,结合应用场景去实现,不完全讲使用方法,例如导入文件,分词后的存储等等;
然后可能还会结合web开发和GUI程序开发去实践,例如写一个通用的web接口,上传一段文字,返回分词结果;以便于很多不会编程的直接拿来使用;当然内容还是更多的是基于技术和实现过程的!
需要掌握的基本技能**
这一块也是针对后续的一些文章内容的,不是针对小白或者有一定了解的同学的;
主要是两方面:
首先就是编程基础,要对python有基本的概念,对其语法有一些了解;不能代码结构都看不懂,或者安装包都不会吧。
然后就是数据结构和算法,熟悉常见的数据结构,如列表、字典等,了解常见的算法,如查找、排序等。
-
大致的规划
后续的学习过程,主要还是针对案例的,基本上每篇文章应该都会有实践;
例如分词,可能会针对常见的包去做一些基本的学习,结合应用场景去实现,不完全讲使用方法,例如导入文件,分词后的存储等等;
然后可能还会结合web开发和GUI程序开发去实践,例如写一个通用的web接口,上传一段文字,返回分词结果;以便于很多不会编程的直接拿来使用;当然内容还是更多的是基于技术和实现过程的!
以上就是个人整理的NLP的知识体系的全部内容,请期待后续的文章吧!!!
感谢阅读!文章来源:https://www.toymoban.com/news/detail-696611.html
原文链接:【精品】NLP自然语言处理学习路线(知识体系)文章来源地址https://www.toymoban.com/news/detail-696611.html

到了这里,关于【精品】NLP自然语言处理学习路线(知识体系)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!