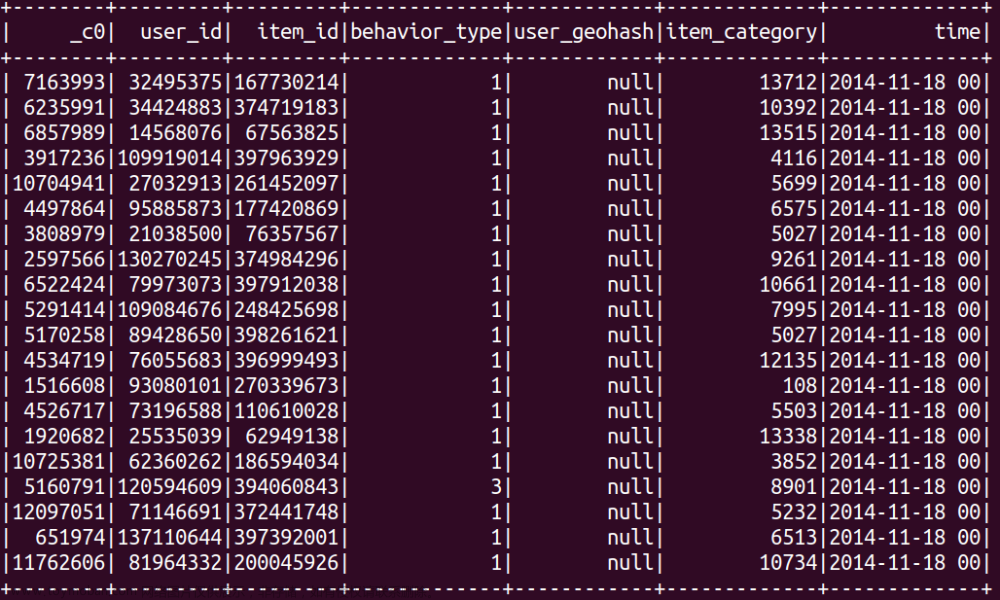
计算CSV文件中每列的数据覆盖率(非缺失值的百分比)时,您可以使用提供的Java代码来完成这项任务。以下是更详细的步骤:文章来源:https://www.toymoban.com/news/detail-697216.html
1. 导入所需库和设置Spark配置
首先,您需要导入所需的Java库,并设置Spark的配置。这些库包括Apache Spark的Java库以及用于数据处理和格式化的其他Java库。文章来源地址https://www.toymoban.com/news/detail-697216.html
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD到了这里,关于19 | spark 统计 每列的数据非缺失值的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!