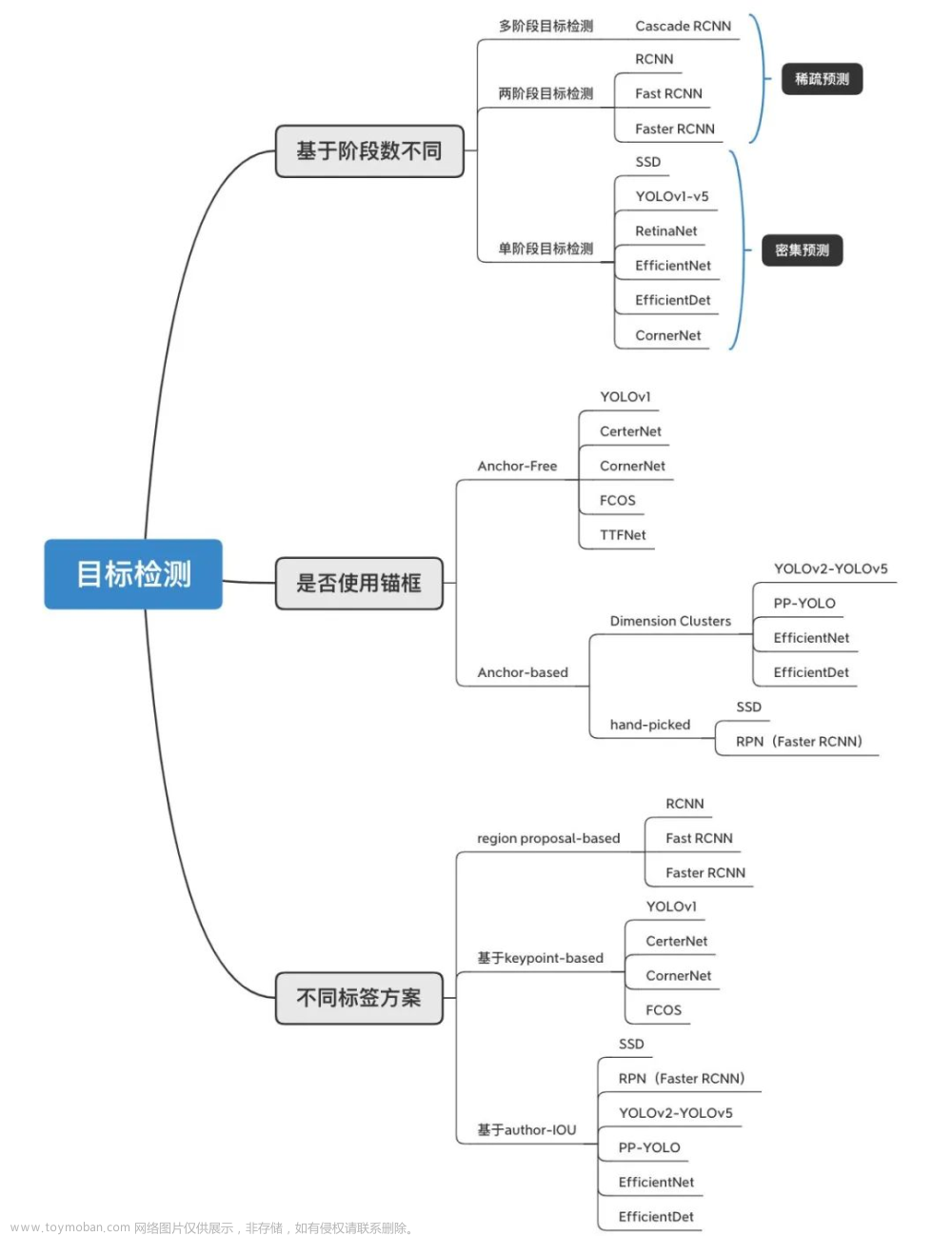
Yolov5网络构架实现文章来源:https://www.toymoban.com/news/detail-697325.html
 文章来源地址https://www.toymoban.com/news/detail-697325.html
文章来源地址https://www.toymoban.com/news/detail-697325.html
import torch
import torch.nn as nn
class SiLU(nn.Module):
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def autopad(k, p=None):
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k]
return p
class Focus(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x):
# 320, 320, 12 => 320, 320, 64
return self.conv(
# 640, 640, 3 => 320, 320, 12
torch.cat(
[
x[..., ::2, ::2],
x[..., 1::2, ::2],
x[..., ::2, 1::2],
x[..., 1::2, 1::2]
], 1
)
)
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act = SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat(
(
self.m(self.cv1(x)),
self.cv2(x)
)
, dim=1))
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class CSPDarknet(nn.Module):
def __init__(self, base_channels, base_depth, phi, pretrained):
super().__init__()
#-----------------------------------------------#
# 输入图片是640, 640, 3
# 初始的基本通道base_channels是64
#-----------------------------------------------#
#-----------------------------------------------#
# 利用focus网络结构进行特征提取
# 640, 640, 3 -> 320, 320, 12 -> 320, 320, 64
#-----------------------------------------------#
self.stem = Focus(3, base_channels, k=3)
#-----------------------------------------------#
# 完成卷积之后,320, 320, 64 -> 160, 160, 128
# 完成CSPlayer之后,160, 160, 128 -> 160, 160, 128
#-----------------------------------------------#
self.dark2 = nn.Sequential(
# 320, 320, 64 -> 160, 160, 128
Conv(base_channels, base_channels * 2, 3, 2),
# 160, 160, 128 -> 160, 160, 128
C3(base_channels * 2, base_channels * 2, base_depth),
)
#-----------------------------------------------#
# 完成卷积之后,160, 160, 128 -> 80, 80, 256
# 完成CSPlayer之后,80, 80, 256 -> 80, 80, 256
# 在这里引出有效特征层80, 80, 256
# 进行加强特征提取网络FPN的构建
#-----------------------------------------------#
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2),
C3(base_channels * 4, base_channels * 4, base_depth * 3),
)
#-----------------------------------------------#
# 完成卷积之后,80, 80, 256 -> 40, 40, 512
# 完成CSPlayer之后,40, 40, 512 -> 40, 40, 512
# 在这里引出有效特征层40, 40, 512
# 进行加强特征提取网络FPN的构建
#-----------------------------------------------#
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2),
C3(base_channels * 8, base_channels * 8, base_depth * 3),
)
#-----------------------------------------------#
# 完成卷积之后,40, 40, 512 -> 20, 20, 1024
# 完成SPP之后,20, 20, 1024 -> 20, 20, 1024
# 完成CSPlayer之后,20, 20, 1024 -> 20, 20, 1024
#-----------------------------------------------#
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2),
SPP(base_channels * 16, base_channels * 16),
C3(base_channels * 16, base_channels * 16, base_depth, shortcut=False),
)
if pretrained:
url = {
's' : 'https://github.com/bubbliiiing/yolov5-pytorch/releases/download/v1.0/cspdarknet_s_backbone.pth',
'm' : 'https://github.com/bubbliiiing/yolov5-pytorch/releases/download/v1.0/cspdarknet_m_backbone.pth',
'l' : 'https://github.com/bubbliiiing/yolov5-pytorch/releases/download/v1.0/cspdarknet_l_backbone.pth',
'x' : 'https://github.com/bubbliiiing/yolov5-pytorch/releases/download/v1.0/cspdarknet_x_backbone.pth',
}[phi]
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", model_dir="./model_data")
self.load_state_dict(checkpoint, strict=False)
print("Load weights from ", url.split('/')[-1])
def forward(self, x):
x = self.stem(x)
x = self.dark2(x)
#-----------------------------------------------#
# dark3的输出为80, 80, 256,是一个有效特征层
#-----------------------------------------------#
x = self.dark3(x)
feat1 = x
#-----------------------------------------------#
# dark4的输出为40, 40, 512,是一个有效特征层
#-----------------------------------------------#
x = self.dark4(x)
feat2 = x
#-----------------------------------------------#
# dark5的输出为20, 20, 1024,是一个有效特征层
#-----------------------------------------------#
x = self.dark5(x)
feat3 = x
return feat1, feat2, feat3
到了这里,关于【目标检测】理论篇(3)YOLOv5实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!