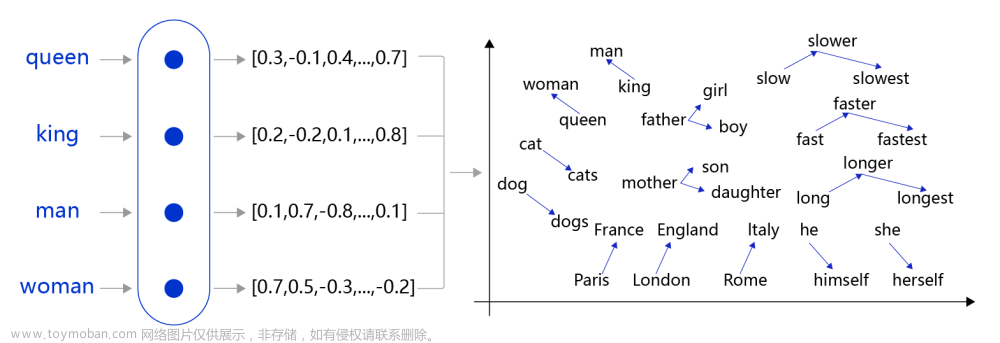
本文全面回顾了自然语言处理(NLP)从20世纪50年代至今的历史发展。从初创期的符号学派和随机学派,到理性主义时代的逻辑和规则范式,再到经验主义和深度学习时代的数据驱动方法,以及最近的大模型时代,NLP经历了多次技术革新和范式转换。文章不仅详细介绍了每个阶段的核心概念和技术,还提供了丰富的Python和PyTorch实战代码。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、引言
自然语言处理(Natural Language Processing,简称NLP)是一个跨学科的领域,它主要关注如何使计算机能够理解、生成和与人类使用的自然语言进行有效交流。NLP不仅是实现人与计算机之间更紧密合作的关键技术,而且也是探究人类语言和思维复杂性的一种途径。
什么是自然语言处理?
自然语言处理包括两个主要的子领域:自然语言理解(Natural Language Understanding,简称NLU)和自然语言生成(Natural Language Generation,简称NLG)。NLU致力于让计算机理解自然语言的语义和上下文,从而执行特定任务,如信息检索、机器翻译或者情感分析。而NLG则关注如何从数据或者逻辑表达中生成自然、准确和流畅的自然语言文本。
语言与人类思维
语言是人类区别于其他动物的最显著特征之一。它不仅是人们日常沟通的工具,还是逻辑思维和知识传播的主要媒介。由于语言的复杂性和多样性,使得自然语言处理成为一个充满挑战和机会的领域。
自然语言的复杂性
如果人工智能(AI)希望真正地与人类互动或从人类知识中学习,那么理解不精确、有歧义、复杂的自然语言是不可或缺的。这样的复杂性使NLP成为人工智能领域中最具挑战性的子领域之一。
NLP的历史轨迹

自然语言处理的研究可以追溯到1947年,当时Warren Weaver提出了利用计算机进行语言翻译的可能性。几年之后,1950年,Alan Turing发表了开创性的论文《Computing Machinery and Intelligence》,标志着人工智能和自然语言处理研究的正式起步。从那时起,NLP经历了多个发展阶段,包括20世纪50年代末到60年代的初创期、70年代到80年代的理性主义时代、90年代到21世纪初的经验主义时代,以及2006年至今的深度学习时代。
在本文中,我们将深入探索NLP的各个发展阶段,分析其历史背景、主要技术和影响。这将帮助我们更全面地了解NLP的发展,以及预见其未来可能的方向。
接下来,让我们一同启程,回顾这个令人着迷的学科如何从一个概念走到了今天这一步。
二、20世纪50年代末到60年代的初创期
20世纪50年代末到60年代初是自然语言处理(NLP)的萌芽时期,这一阶段主要分为两大流派:符号学派和随机学派。在这一段时间内,人们开始意识到计算机的潜能,不仅仅在数学计算上,还包括模拟人类语言和思维。
符号学派
符号学派的核心思想是通过明确的规则和符号来表示自然语言。这种方法强调逻辑推理和形式语法,认为通过精确定义语言结构和规则,计算机可以实现语言理解和生成。
重要的研究和突破
-
1950年:Alan Turing的《Computing Machinery and Intelligence》

这篇论文提出了“图灵测试”,用以判断一个机器是否具备智能。这一标准也被应用于评估计算机是否能够理解和生成自然语言。 -
1954年:Georgetown-IBM实验
Georgetown大学和IBM合作进行了一次名为“Georgetown Experiment”的实验,成功地使用机器将60多个俄语句子翻译成英文。虽然结果并不完美,但这标志着机器翻译和NLP的第一次重大尝试。
随机学派
与符号学派侧重于逻辑和规则不同,随机学派注重使用统计方法来解析自然语言。这种方法主要基于概率模型,如马尔可夫模型,来预测词汇和句子的生成。
重要的研究和突破
-
1958年:Noam Chomsky的“句法结构”(Syntactic Structures)
这本书对形式语法进行了系统的描述,尽管Chomsky本人是符号学派的代表,但他的这一工作也催生了统计学派开始使用数学模型来描述语言结构。 -
1960年:Zellig Harris的“方法论”(Method in Structural Linguistics)
Harris提出了使用统计和数学工具来分析语言的方法,这些工具后来被广泛应用于随机学派的研究中。
这一时期的研究虽然初级,但它们为后来的NLP研究奠定了基础,包括词性标注、句法解析和机器翻译等。符号学派和随机学派虽然方法不同,但都在试图解决同一个问题:如何让计算机理解和生成自然语言。这一时期的尝试和突破,为后来基于机器学习和深度学习的NLP研究铺平了道路。
三、20世纪70年代到80年代的理性主义时代
在自然语言处理(NLP)的历史长河中,20世纪70年代至80年代标志着一段理性主义时代。在这个阶段,NLP研究的焦点从初级的规则和统计模型转向了更为成熟、复杂的理论框架。这一时代主要包括三大范式:基于逻辑的范式、基于规则的范式和随机范式。
基于逻辑的范式
基于逻辑的范式主要侧重于使用逻辑推理来理解和生成语言。这一方法认为,自然语言中的每个句子都可以转化为逻辑表达式,这些表达式可以通过逻辑演算来分析和操作。
重要的研究和突破
-
1970年:第一次“逻辑程序设计”(Logic Programming)的引入
在这一年,逻辑程序设计被首次引入作为一种能够执行逻辑推理的计算模型。Prolog(Programming in Logic)便是这一范式下的代表性语言。 -
1978年:Terry Winograd的《Understanding Natural Language》

Winograd介绍了SHRDLU,一个能够理解和生成自然语言的计算机程序,这一程序主要基于逻辑和语义网。
基于规则的范式
基于规则的范式主要聚焦于通过明确的规则和算法来解析和生成语言。这些规则通常都是由人类专家设计的。
重要的研究和突破
-
1971年:Daniel Bobrow的STUDENT程序
STUDENT程序能解决代数文字问题,是基于规则的自然语言理解的早期尝试。 -
1976年:Roger Schank的“Conceptual Dependency Theory”
这一理论提出,所有自然语言句子都可以通过一组基本的“概念依赖”来表示,这为基于规则的范式提供了理论基础。
随机范式
尽管随机范式在50至60年代已有所涉猎,但在70至80年代它逐渐走向成熟。这一范式主要使用统计方法和概率模型来处理自然语言。
重要的研究和突破
-
1979年:Markov模型在语音识别中的应用
尽管不是纯粹的NLP应用,但这一突破标志着统计方法在自然语言处理中的日益增长的重要性。 -
1980年:Brown语料库的发布
Brown语料库的发布为基于统计的自然语言处理提供了丰富的数据资源,这标志着数据驱动方法在NLP中的崭露头角。
这一时代的三大范式虽然有所不同,但都有着共同的目标:提升计算机对自然语言的理解和生成能力。在这一时代,研究人员开始集成多种方法和技术,以应对自然语言处理中的各种复杂问题。这不仅加深了我们对自然语言处理的理解,也为后续的研究打下了坚实的基础。
四、20世纪90年代到21世纪初的经验主义时代
这个时期代表着自然语言处理(NLP)由理论导向向数据驱动的转变。经验主义时代强调使用实际数据来训练和验证模型,而不仅仅依赖于人为定义的规则或逻辑推理。在这个时代,NLP研究主要集中在两个方面:基于机器学习的方法和数据驱动的方法。
基于机器学习的方法

机器学习在这个时代开始被广泛地应用于自然语言处理问题,包括但不限于文本分类、信息检索和机器翻译。
重要的研究和突破
-
1994年:决策树用于词性标注
Eric Brill首次展示了如何使用决策树进行词性标注,这代表了一种从数据中自动学习规则的新方法。 -
1999年:最大熵模型在NLP中的引入
最大熵模型被首次应用于自然语言处理,尤其在词性标注和命名实体识别方面取得了突出的表现。
数据驱动的方法
这个范式主张使用大量的文本数据来“教”计算机理解和生成自然语言,通常通过统计方法或机器学习算法。
重要的研究和突破
-
1991年:发布了Wall Street Journal语料库
这个广泛使用的语料库对许多后续基于数据的NLP研究起到了推动作用。 -
1993年:IBM的统计机器翻译模型
IBM研究团队提出了一种革新性的统计机器翻译模型,标志着从基于规则的机器翻译向基于数据的机器翻译的转变。
提出逻辑过程
-
数据收集和预处理
随着互联网的快速发展,数据变得越来越容易获取。这促使研究人员开始集中精力预处理这些数据,并将其用于各种NLP任务。 -
模型选择和优化
选择适当的机器学习模型(如决策树、支持向量机或神经网络)并对其进行优化,以提高其在特定NLP任务上的性能。 -
评估和微调
使用验证集和测试集进行模型评估,并根据需要进行微调。
这个经验主义时代的主要贡献是它把自然语言处理推向了一种更为实用和可扩展的方向。依靠大量的数据和高度复杂的算法,NLP开始在商业和日常生活中发挥越来越重要的作用。这一时代也为随后的深度学习时代奠定了坚实的基础。
五、2006年至今的深度学习时代
自2006年以来,深度学习的兴起彻底改变了自然语言处理(NLP)的面貌。与经验主义和理性主义时代相比,深度学习带来了巨大的模型复杂性和数据处理能力。这个时代主要集中在两个方面:深度神经网络和向量表示。
深度神经网络

深度神经网络模型由多层(通常大于三层)的网络结构组成,这使它们能够学习更复杂、更高级的特征。
重要的研究和突破
-
2008年:递归神经网络(RNN)
在这一年,研究人员首次证明了递归神经网络能够有效地处理诸如文本生成和机器翻译等序列任务。 -
2013年:词嵌入(Word Embeddings)和Word2Vec模型
Tomas Mikolov等人发布了Word2Vec,这是一种能有效地将词语转换为向量表示的方法。 -
2014年:序列到序列(Seq2Seq)模型
Google的研究团队提出了序列到序列模型,标志着NLP应用(尤其是机器翻译)的一个重要转折点。 -
2015年:注意力机制(Attention Mechanism)
注意力机制被引入到NLP中,特别是用于解决机器翻译等序列到序列任务的问题。
向量表示
这里主要是指将文本和其他语言元素转换成数学向量,通常用于后续的机器学习任务。
重要的研究和突破
-
2013年:GloVe模型
GloVe(全局向量)模型被提出,为词嵌入提供了一种全新的统计方法。 -
2018年:BERT模型
BERT(双向编码器表示从变换器)模型被发布,它改变了我们对文本处理和理解的方式,尤其是在任务如文本分类、命名实体识别和问题回答方面。
提出逻辑过程
-
从浅层模型到深度模型
随着计算能力的提升和数据量的增加,研究人员开始探索更复杂的模型结构。 -
优化和正则化
针对深度神经网络,研究人员开发了各种优化算法(如Adam、RMSprop等)和正则化技术(如Dropout)。 -
预训练和微调
凭借大量可用的文本数据,研究人员现在通常会先对一个大型模型进行预训练,然后针对特定任务进行微调。 -
解释性和可解释性
由于深度学习模型通常被认为是“黑箱”,因此后续的研究也开始集中在提高模型可解释性上。
深度学习时代不仅提高了NLP任务的性能,还带来了一系列全新的应用场景,如聊天机器人、自动问答系统和实时翻译等。这一时代的研究和应用无疑为NLP的未来发展打下了坚实的基础。
六、2018年至今的大模型时代

从2018年开始,超大规模语言模型(例如GPT和BERT)走入人们的视野,它们以其强大的性能和多样的应用场景在NLP(自然语言处理)领域引发了一场革命。这一时代被大模型所定义,这些模型不仅在规模上大大超过以往,而且在处理复杂任务方面也有显著的优势。
超大规模语言模型
在这一阶段,模型的规模成为了一种关键的优势。比如,GPT-3模型具有1750亿个参数,这使它能够进行高度复杂的任务。
重要的研究和突破
-
2018年:BERT(Bidirectional Encoder Representations from Transformers)
BERT模型由Google提出,通过双向Transformer编码器进行预训练,并在多项NLP任务上达到了最先进的表现。 -
2019年:GPT-2(Generative Pre-trained Transformer 2)
OpenAI发布了GPT-2,虽然模型规模较小(与GPT-3相比),但它展示了生成文本的强大能力。 -
2020年:GPT-3(Generative Pre-trained Transformer 3)
OpenAI发布了GPT-3,这一模型的规模和性能都达到了一个新的高度。 -
2021年:CLIP(Contrastive Language-Image Pre-training)和DALL-E
OpenAI再次引领潮流,发布了可以理解图像和文本的模型。
提出逻辑过程
-
数据驱动到模型驱动
由于模型的规模和计算能力的增长,越来越多的任务不再需要大量标注的数据,模型自身的能力成为了主导。 -
自监督学习
大规模语言模型的训练通常使用自监督学习,这避免了对大量标注数据的依赖。 -
预训练与微调的普遍化
通过在大量文本数据上进行预训练,然后针对特定任务进行微调,这一流程已经成为业界标准。 -
多模态学习
随着CLIP和DALL-E的出现,研究开始从纯文本扩展到包括图像和其他类型的数据。 -
商业应用和伦理考量
随着模型规模的增加,如何合理、安全地部署这些模型也成为一个重要议题。
趋势与影响
-
减少对标注数据的依赖
由于大模型本身具有强大的表示学习能力,标注数据不再是性能提升的唯一手段。 -
任务泛化能力
这些大型模型通常具有出色的任务泛化能力,即使用相同的预训练模型基础上进行不同任务的微调。 -
计算资源的问题
模型的规模和复杂性也带来了更高的计算成本,这在一定程度上限制了其普及和应用。
2018年至今的大模型时代标志着NLP进入一个全新的发展阶段,这一阶段不仅改变了研究的方向,也对实际应用产生了深远的影响。从搜索引擎到聊天机器人,从自动翻译到内容生成,大模型正在逐渐改变我们与数字世界的互动方式。
七、Python和PyTorch实战每个时代
在自然语言处理(NLP)的发展历史中,不同的时代有着各自代表性的方法和技术。在本节中,我们将使用Python和PyTorch来实现这些代表性方法。
20世纪50年代末到60年代的初创期:符号学派和随机学派
在这个时代,一个经典的方法是正则表达式用于文本匹配。
正则表达式示例
import re
def text_matching(pattern, text):
result = re.findall(pattern, text)
return result
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
text = "My email is example@email.com"
result = text_matching(pattern, text)
print("输出:", result)
输入: 文本和正则表达式
输出: 符合正则表达式的文本片段
20世纪70年代到80年代的理性主义时代:基于逻辑的范式、基于规则的范式和随机范式
在这一时代,基于规则的专家系统在NLP中有广泛应用。
基于规则的名词短语识别
def noun_phrase_recognition(sentence):
rules = {
'noun': ['dog', 'cat'],
'det': ['a', 'the'],
}
tokens = sentence.split()
np = []
for i, token in enumerate(tokens):
if token in rules['det']:
if tokens[i + 1] in rules['noun']:
np.append(f"{token} {tokens[i + 1]}")
return np
sentence = "I see a dog and a cat"
result = noun_phrase_recognition(sentence)
print("输出:", result)
输入: 一句话
输出: 名词短语列表
20世纪90年代到21世纪初的经验主义时代:基于机器学习和数据驱动
这一时代的代表性方法是朴素贝叶斯分类。
朴素贝叶斯文本分类
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import LabelEncoder
texts = ["I love Python", "I hate bugs", "I enjoy coding"]
labels = ["positive", "negative", "positive"]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
clf = MultinomialNB()
clf.fit(X, y)
sample_text = ["I hate Python"]
sample_X = vectorizer.transform(sample_text)
result = clf.predict(sample_X)
print("输出:", label_encoder.inverse_transform(result))
输入: 文本和标签
输出: 分类标签
2006年至今的深度学习时代
这个时代是由深度神经网络和向量表示主导的,其中一个代表性的模型是LSTM。
LSTM文本生成
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size)
self.fc = nn.Linear(hidden_size, vocab_size)
def forward(self, x):
x = self.embedding(x)
output, _ = self.lstm(x)
output = self.fc(output)
return output
# 省略模型训练和预测代码
输入: 文本的词索引
输出: 下一个词的概率分布
通过这些例子,我们可以看到各个时代在自然语言处理中的不同方法和应用。这些代码示例帮助我们更好地理解这些方法是如何从输入到输出进行工作的。
八、总结
自然语言处理(NLP)是一个跨学科的领域,涉及计算机科学、人工智能、语言学等多个学科。从20世纪50年代至今,该领域经历了多个不同的发展阶段,每个阶段都有其独特的方法论和技术特点。
简述历史脉络
- 20世纪50年代末到60年代的初创期:这一阶段以符号学派和随机学派为代表,主要集中在基础理论和模式识别等方面。
- 20世纪70年代到80年代的理性主义时代:基于逻辑的范式、基于规则的范式和随机范式在这一时期得到了广泛的研究和应用。
- 20世纪90年代到21世纪初的经验主义时代:基于机器学习和大量数据的方法开始占据主导地位。
- 2006年至今的深度学习时代:深度神经网络,特别是循环神经网络和Transformer架构,带来了前所未有的模型性能。
- 2018年至今的大模型时代:超大规模的预训练语言模型,如GPT和BERT,开始在各种NLP任务中展现出色的性能。
洞见与展望
-
融合多种范式:尽管每个时代都有其主导的方法论和技术,但未来的NLP发展可能需要融合不同范式,以达到更好的效果。
-
可解释性与健壮性:随着模型复杂度的提高,如何确保模型的可解释性和健壮性将是一个重要的研究方向。
-
数据多样性:随着全球化的推进,多语言、多文化环境下的自然语言处理问题也日益突出。
-
人与机器的交互:未来的NLP不仅需要从大量文本中提取信息,还需要更好地理解和生成自然语言,以实现更自然的人机交互。
-
伦理与社会影响:随着NLP技术在各个领域的广泛应用,其伦理和社会影响也不能忽视。如何避免算法偏见,保护用户隐私,将是未来研究的重要主题。文章来源:https://www.toymoban.com/news/detail-697503.html
通过本文,我们希望能给读者提供一个全面而深入的视角,以理解自然语言处理的历史发展和未来趋势。从正则表达式到超大规模语言模型,NLP领域的飞速发展充分展示了其在解决实际问题中的强大潜力,也让我们对未来充满期待。文章来源地址https://www.toymoban.com/news/detail-697503.html
到了这里,关于自然语言处理历史史诗:NLP的范式演变与Python全实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!