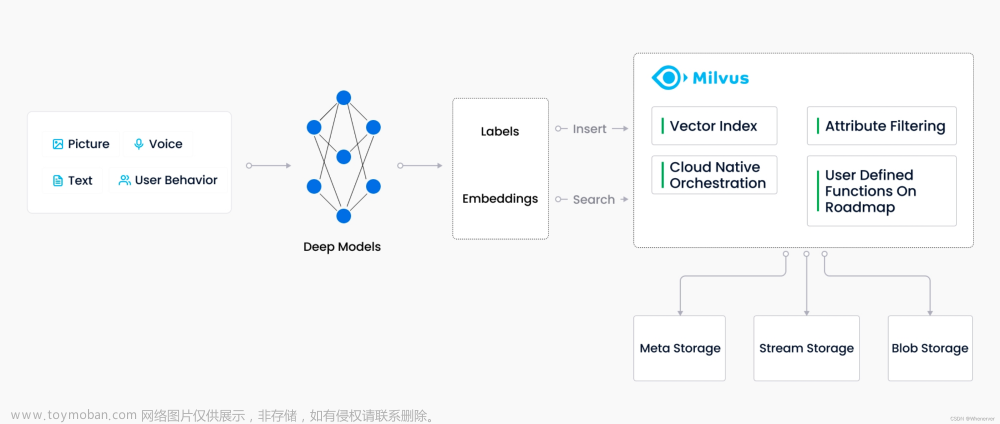
New Feature
-
Upsert 功能
支持用户通过 upsert 接口更新或插入数据。已知限制,自增 id 不支持 upsert;upsert 是内部实现是 delete + insert所以性能上会有一定损耗,如果明确知道是写入数据的场景请继续使用 insert。

-
Range Search 功能
支持用户通过输入参数指定 search 的 distance 进行查询,返回所有与目标向量距离位于某一范围之内的结果。例如:文章来源:https://www.toymoban.com/news/detail-698084.html
// add radius and range_filter to params in search_params
search_params = {"params": {"nprobe": 10, "radius": 10, "range_filter" : 20}, "metric_type": "L2"}
res = collection.search(
vectors, "float_vector", search_params, topK,
"int64 > 100", output_fields=["int64", "float"]
)
该例子中就会返回距离在 10~20 之间的向量。需要注意的是不同文章来源地址https://www.toymoban.com/news/detail-698084.html
到了这里,关于《向量数据库指南》——AI原生向量数据库Milvus Cloud 2.3新功能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!