Annoy 和 Milvus 都是用于向量索引和相似度搜索的开源库,它们可以高效地处理大规模的向量数据。
Annoy(Approximate Nearest Neighbors Oh Yeah):
- Annoy 是一种近似最近邻搜索算法,它通过构建一个树状结构来加速最近邻搜索。
- Annoy 支持支持欧氏距离,曼哈顿距离,余弦距离,汉明距离或点(内)乘积距离等多种度量方式。
- Annoy 是一个轻量级的库,易于使用和集成,如果向量维度不是太多(例如<100维),效果会比较好。
- 目前 Annoy 主要支持 Python 和 C++ 接口。
Milvus:
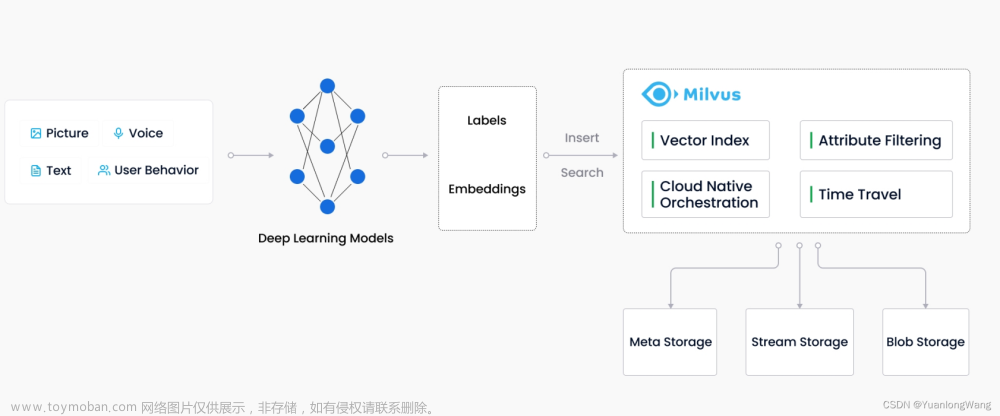
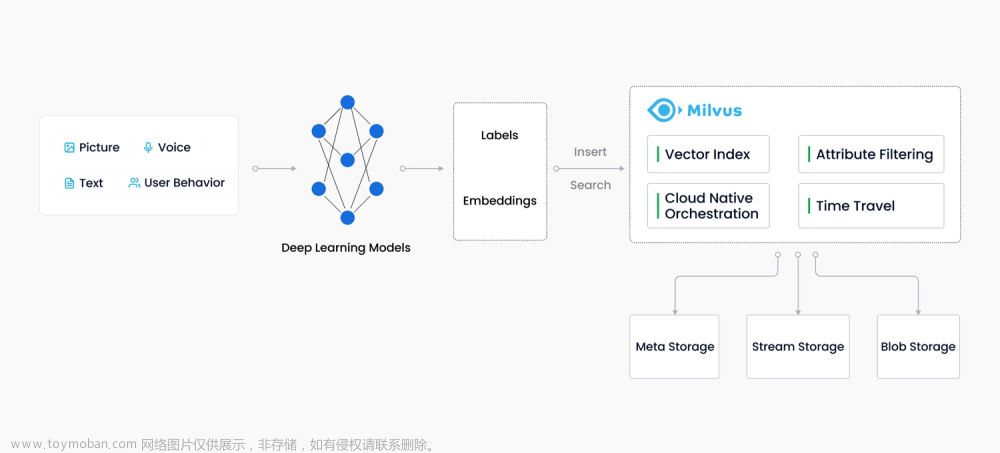
- Milvus 是一个基于向量相似度搜索的开源引擎,它可以将大规模向量数据快速存储和检索。
- Milvus 使用了各种索引和算法优化技术,提供了高效的向量搜索能力。
- Milvus 支持欧式距离、内积相似度等多种度量方式,且具有扩展性和可定制性。
- Milvus 提供了 Python、Java 和 Go 等多种编程语言的接口。
- Milvus 还提供了图形用户界面 (GUI) 和可视化工具来辅助管理和查询向量数据库。
选择 Annoy 还是 Milvus 取决于您的具体需求和应用场景:
- 如果对于
近似最近邻搜索的速度和轻量级集成更为关注,可以选择 Annoy。(demo入门) - 如果需要
管理和查询大规模的向量数据库,并希望具备更多的功能和可扩展性,可以选择 Milvus。(工业级应用)
1. Annoy
Annoy (Approximate Nearest Neighbors Oh Yeah)是一个带有Python bindings的C ++库,用于搜索空间中给定查询点的近邻点。它还会创建大型的基于文件的只读数据结构,并将其映射到内存中,以便许多进程可以共享相同的数据。annoy的学习成本非常低,能较快的掌握,非常适合项目的快速开发,于此对比的是,faiss和Milvus的学习成本较高,用起来较为复杂。
用于空间检索近邻的数据。检索过程分成三步:
- 建立索引过程;
- 近邻查询过程;
- 返回最终近邻节点;
首先先来一张2D数据分布图:
接下来按照步骤1,2和3进行分析。
1.1 建立索引过程
Annoy的目标是建立一个数据结构,使得查询一个点的最近邻点的时间复杂度是次线性。Annoy 通过建立一个二叉树来使得每个点查找时间复杂度是O(log n)。以下图为例,随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点。这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。
在划分的子空间内进行不停的递归迭代继续划分,直到每个子空间最多只剩下K个数据节点。

通过多次递归迭代划分的话,最终原始数据会形成类似下图的二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。

根据上述步骤,建立多棵二叉树树,构成一个森林。
1.2 近邻查询过程
上面已完成节点索引建立过程。如何进行对一个数据点进行查找相似节点集合呢?比如下图的红色节点,查找的过程就是不断看他在分割超平面的哪一边。从二叉树索引结构来看,就是从根节点不停的往叶子节点遍历的过程。通过对二叉树每个中间节点(分割超平面相关信息)和查询数据节点进行相关计算来确定二叉树遍历过程是往这个中间节点左孩子节点走还是右孩子节点走。通过以上方式完成查询过程。

查询过程采用优先队列机制:采用一个优先队列来遍历二叉树,从根节点往下的路径,根据查询节点与当前分割超平面距离进行排序。

1.3 返回最终近邻节点
步骤1会构建多棵二叉树树,每棵树都返回一堆近邻点后,如何得到最终的Top N相似集合呢?首先所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离,最终根据距离值从近距离到远距离排序,返回Top-N近邻节点集合。
1.4 完整的Python API
-
AnnoyIndex(f, metric)返回可读写的新索引,用于存储f维度向量。metric 可以"angular","euclidean","manhattan","hamming","dot"。 -
a.add_item(i, v)用于给索引添加向量v,i(任何非负整数)是给向量v的表示。 -
a.build(n_trees)用于构建 n_trees 的森林。查询时,树越多,精度越高。在调用build后,无法再添加任何向量。 -
a.save(fn, prefault=False)将索引保存到磁盘。保存后,不能再添加任何向量。 -
a.load(fn, prefault=False)从磁盘加载索引。如果prefault设置为True,它将把整个文件预读到内存中。默认值为False。 -
a.unload()释放索引。 -
a.get_nns_by_item(i, n, search_k=-1, include_distances=False)返回第i 个item的n个最近邻的item。在查询期间,它将检索多达search_k(默认n_trees * n)个点。search_k为您提供了更好的准确性和速度之间权衡。如果设置include_distances为True,它将返回一个包含两个列表的2元素元组:第二个包含所有对应的距离。 -
a.get_nns_by_vector(v, n, search_k=-1, include_distances=False)与上面的相同,但按向量v查询。 -
a.get_item_vector(i)返回第i个向量前添加的向量。 -
a.get_distance(i, j)返回向量i和向量j之间的距离。注意:此函数用于返回平方距离。 -
a.get_n_items()返回索引中的向量数。 -
a.get_n_trees()返回索引中的树的数量。 -
a.on_disk_build(fn)用以在指定文件而不是RAM中建立索引(在添加向量之前执行,在建立之后无需保存)。
Notes:
Annoy使用归一化向量的欧式距离作为其角距离,对于两个向量u,v,其等于 sqrt(2(1-cos(u,v)))
C ++ API非常相似:调用annoy只需使用#include "annoylib.h"。
权衡
调整Annoy仅需要两个主要参数:树的数量 n_trees 和搜索期间要检查的节点的数量search_k。文章来源:https://www.toymoban.com/news/detail-698090.html
-
n_trees在构建索引期间提供该值,并且会影响构建时间和索引大小。较大的值将给出更准确的结果,但索引较大。 -
search_k是在运行时提供的,并且会影响搜索性能。较大的值将给出更准确的结果,但返回时间将更长。
如果search_k未提供,它将默认为n * n_trees * D,n是近似最近邻居的数目,并且D是一个常数,取决于向量维度。否则,search_k和n_trees是大致独立的,即如果search_k保持不变,n_trees不会影响搜索时间,反之亦然。基本上,在您可以负担的内存使用量的情况下建议在n_trees可能大的值,并且在给定查询时间的限制的情况下建议设置search_k尽可能大。文章来源地址https://www.toymoban.com/news/detail-698090.html
到了这里,关于向量数据库Annoy和Milvus的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!