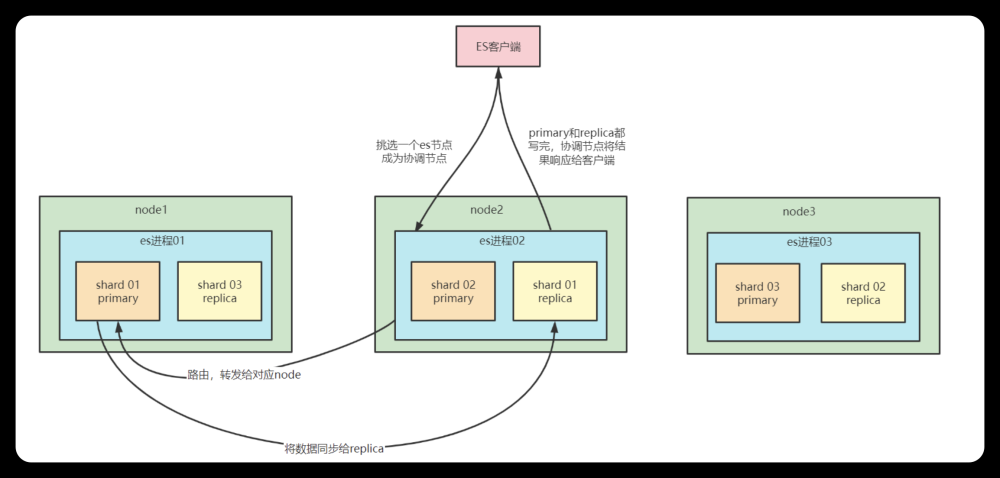
一直有个疑问“学习最新版lucene 数据写入相关的源码,应该看哪些源码,以什么顺序看(先看什么,后看什么)?”
对于Lucene的数据写入过程,可以分为以下几个阶段
在学习Lucene的数据写入相关的源码时,可以按照以下阶段的顺序进行学习和理解,以便更好地掌握Lucene的数据写入过程。同时,也需要了解一些相关的类和方法,例如DocumentsWriter、SegmentInfo、IndexWriterConfig等类和方法。
文档解析阶段:将文档转化为Lucene内部的Document对象。可以使用Analyzer进行文本分析和处理,例如分词、过滤、大小写转换等操作。
文档加入缓存阶段:将解析出的Document对象加入到内存中的缓存中,通常称为DocumentsWriter。
索引写入阶段:DocumentsWriter会将缓存中的文档转换成Segment,并将Segment写入磁盘。如果内存缓存中的文档数量达到一定的阈值,DocumentsWriter会触发一次Segment的写入。
Segment合并阶段:Lucene的索引存储结构是由多个Segment组成的。当多个Segment的数量达到一定的阈值时,Lucene会进行Segment的合并操作,以便优化索引的查询效率和存储空间使用。
索引刷新阶段:将内存中的Segment刷新到磁盘中,并将新的Segment信息添加到SegmentInfo中。
索引提交阶段:当多个Segment的数量达到一定的阈值或者IndexWriter关闭时,Lucene会将索引提交,以便保存索引的信息。
在具体的源码学习中,可以按照以下步骤进行
了解IndexWriter的基本用法和实现原理。可以查看官方文档和相关书籍,了解IndexWriter的构造函数、commit方法、addDocument方法、deleteDocuments方法等基本用法,并对IndexWriter的实现原理有一个大概的了解。
学习DocumentsWriter的实现原理。DocumentsWriter是Lucene内存中的一个缓存,用于将文档加入缓存中,并将缓存中的文档转换为Segment进行写入。可以查看DocumentsWriter的源码,了解DocumentsWriter的实现原理和主要方法。
学习Document、Field、Term等相关类的实现原理。Document、Field、Term等类是Lucene索引中的基本单位,需要深入了解它们的实现原理和相关方法。
学习Analyzer、TokenStream等相关类的实现原理。Analyzer、TokenStream等类是Lucene用于对文本进行分析和处理的类,需要了解它们的实现原理和相关方法。
学习Segment的实现原理和写入过程。Segment是Lucene索引中的一个单元,需要了解Segment的实现原理和写入过程,以及Segment合并的实现原理和过程。
学习IndexWriterConfig、IndexCommit等相关类的实现原理。IndexWriterConfig、IndexCommit等类是Lucene用于配置IndexWriter和管理索引提交的类,需要了解它们的实现原理和相关方法。
在学习过程中,可以使用调试工具和日志输出等方式,深入了解Lucene的数据写入过程和相关类和方法的实现细节,以便更好地理解和掌握Lucene的数据写入相关的源码。同时,也需要结合Lucene的官方文档、参考书籍、技术博客等资源进行学习和实践,加深对Lucene的理解和应用。
列出来lucene相关的源码
在学习这些类时,应该注意它们之间的关系和依赖关系,以便更好地理解Lucene的内部工作原理。同时,也应该查阅Lucene官方文档和源代码注释,以便更好地理解这些类的实现和用法。
要学习最新版的Lucene数据写入相关的源码,可以按照以下顺序阅读:
IndexWriter类: IndexWriter类是Lucene用于创建和更新索引的主要入口点。这个类负责将文档写入索引并管理索引的打开和关闭。可以从IndexWriter类的构造函数开始学习它的实现。
DocumentsWriter类: DocumentsWriter类是IndexWriter的一个内部类,它负责将文档写入内存缓冲区,并在缓冲区满时将其刷新到磁盘上的单个段中。学习这个类可以了解Lucene是如何将文档写入磁盘的。
SegmentWriter类: SegmentWriter类是DocumentsWriter的一个内部类,它负责将文档写入单个段。了解这个类可以深入了解Lucene索引的内部工作原理。
FieldsWriter类: FieldsWriter类是SegmentWriter的一个内部类,它负责将文档字段写入磁盘。学习这个类可以深入了解Lucene索引的字段写入流程。
TermsHash类: TermsHash类是DocumentsWriter的另一个内部类,它负责将文档中的术语写入内存哈希表中。了解这个类可以更好地理解Lucene是如何进行分词和词项化的。
TermVectorsWriter类: TermVectorsWriter类是FieldsWriter的一个内部类,它负责将文档的术语向量写入磁盘。学习这个类可以了解Lucene是如何处理术语向量的。
相关的其他类: 除了以上列出的类之外,还有一些其他的类与Lucene的数据写入有关。例如,Analyzer类、Document类和Field类等都可以深入了解。
学习这些类的实现可以深入了解Lucene是如何在内存和磁盘之间管理和传输数据的。在学习这些类时,可以查阅Lucene官方文档和源代码注释,以便更好地理解这些类的实现和用法。
FSDirectory类: FSDirectory类是Lucene用于管理索引目录的类。在将文档写入索引时,需要将索引写入磁盘,而FSDirectory类就是负责管理这些索引文件的类。可以学习这个类来了解Lucene是如何在磁盘上管理索引文件的。
IndexOutput和IndexInput类: 这些类是Lucene用于在磁盘上读取和写入二进制文件的类。在将文档写入磁盘时,需要将文档的二进制数据写入磁盘文件中,而IndexOutput类就是负责将数据写入磁盘的类。在读取磁盘上的索引文件时,需要使用IndexInput类读取这些文件的内容。
Codec类: Codec类是Lucene用于对索引进行编解码的类。Lucene支持多种编解码方式,例如默认的Lucene70Codec和其他定制的编解码器。了解这个类可以深入了解Lucene的索引编解码过程。
DocValuesWriter和DocValuesConsumer类: DocValuesWriter和DocValuesConsumer类是Lucene用于将文档值写入磁盘的类。这些值可以用于排序、聚合和筛选等操作。了解这些类可以深入了解Lucene是如何处理文档值的。
NormsWriter和NormsConsumer类: NormsWriter和NormsConsumer类是Lucene用于将规范化因子写入磁盘的类。规范化因子用于在搜索时对字段进行加权,了解这些类可以深入了解Lucene是如何进行字段加权的。
这些类主要涉及Lucene的索引和搜索功能,其中包括索引创建、读取、提交,搜索查询和结果排序等。在学习时,可以结合具体的应用场景,选择相应的类进行深入了解。同时,也需要注意Lucene的性能和安全等问题,对Lucene进行合理配置和使用。
这些类主要涉及Lucene的搜索功能,其中包括对搜索结果的处理和展示,以及对搜索条件的过
滤、模糊搜索、数值范围搜索、词项范围搜索、前缀搜索等功能的实现。如果要学习最新版Lucene数据写入相关的源码,可以先从IndexWriter类开始,该类是Lucene用于写入索引数据的类。可以先了解IndexWriter类的基本用法和实现原理,然后再深入了解相关的类和方法,例如DocumentsWriter、Document、Field、Term、SegmentInfo、SegmentInfoPerCommit等类和方法。
在学习IndexWriter类的过程中,可以涉及到Lucene的索引存储结构、索引优化、多线程写入、数据合并等方面的知识。同时,也需要了解一些相关的类和方法,例如Analyzer、IndexOptions、FieldType、IndexWriterConfig、IndexCommit等类和方法。在学习过程中,建议先从简单的类和方法开始,逐渐深入复杂的类和方法,以便更好地理解Lucene的数据写入相关的源码。
LiveDocsFormat类: LiveDocsFormat类是Lucene用于管理删除文档的类。在索引文档时,有时需要删除某些文档,而LiveDocsFormat类就是负责管理这些已删除文档的类。了解这个类可以深入了解Lucene是如何删除文档的。
MergePolicy和MergeScheduler类: MergePolicy和MergeScheduler类是Lucene用于控制索引段合并的类。在将文档写入索引时,Lucene会将文档写入多个索引段中,当这些段达到一定大小时,就需要将它们合并为更大的段。MergePolicy和MergeScheduler类就是负责管理这个过程的类。了解这些类可以深入了解Lucene的索引合并过程。
DirectoryReader和SegmentReader类: DirectoryReader和SegmentReader类是Lucene用于读取索引的类。在搜索文档时,需要从索引中读取数据,而这些类就是负责读取索引的类。了解这些类可以深入了解Lucene是如何读取索引的。
PostingFormat类: PostingFormat类是Lucene用于管理词项位置和频率信息的类。在将文档写入索引时,Lucene会记录文档中每个词项的位置和出现频率,而PostingFormat类就是负责管理这个信息的类。了解这个类可以深入了解Lucene是如何记录文档中的词项信息的。
Similarity类: Similarity类是Lucene用于计算文档相似度的类。在搜索文档时,需要计算文档与查询之间的相似度,而Similarity类就是负责计算相似度的类。了解这个类可以深入了解Lucene是如何计算文档相似度的。
FuzzyQuery类: FuzzyQuery类是Lucene用于模糊搜索的类。在搜索时,有时候需要考虑单词的拼写错误或变体,而FuzzyQuery类就是用于实现这个功能的类。
PhraseQuery类: PhraseQuery类是Lucene用于短语搜索的类。在搜索时,有时候需要匹配文档中的短语,而PhraseQuery类就是用于实现这个功能的类。
QueryParser类: QueryParser类是Lucene用于解析用户查询语句的类。在搜索时,用户输入的查询语句需要经过解析,将其转换为Lucene可以理解的查询对象,而QueryParser类就是用于实现这个功能的类。
IndexWriterConfig类: IndexWriterConfig类是Lucene用于配置IndexWriter对象的类。在创建IndexWriter对象时,需要指定一些参数,而IndexWriterConfig类就是用于设置这些参数的类。
Directory类: Directory类是Lucene用于表示索引存储位置的类。在创建IndexWriter或IndexSearcher对象时,需要指定索引存储位置,而Directory类就是用于表示这个位置的类。
Analyzer类: Analyzer类是Lucene用于对文档进行分词和处理的类。在将文档写入索引时,需要对文档进行分词和处理,而Analyzer类就是用于实现这个功能的类。
Document类: Document类是Lucene用于表示文档的类。在将文档写入索引时,需要将文档转换为Lucene可以理解的对象,而Document类就是用于表示这个对象的类。
IndexSearcher类: IndexSearcher类是Lucene用于搜索索引的类。在搜索时,需要创建IndexSearcher对象,并使用它来执行搜索操作。
BooleanQuery类: BooleanQuery类是Lucene用于实现布尔查询的类。在搜索时,有时候需要将多个查询条件组合起来进行查询,而BooleanQuery类就是用于实现这个功能的类。
TopDocs类: TopDocs类是Lucene用于存储搜索结果的类。在执行搜索操作后,会返回TopDocs对象,其中包含了满足查询条件的文档列表和相关的文档评分信息。
ScoreDoc类: ScoreDoc类是Lucene用于表示搜索结果中的文档和评分信息的类。在TopDocs对象中,每个文档都对应一个ScoreDoc对象,其中包含了文档的编号和评分信息。
Explanation类: Explanation类是Lucene用于解释评分结果的类。在搜索时,评分是一个很重要的指标,而Explanation类就是用于帮助我们理解评分结果的类。
Sort类: Sort类是Lucene用于排序搜索结果的类。在搜索时,有时候需要按照某个字段进行排序,而Sort类就是用于实现这个功能的类。
QueryFilter类: QueryFilter类是Lucene用于实现查询过滤器的类。在搜索时,有时候需要对搜索结果进行过滤,而QueryFilter类就是用于实现这个功能的类。
CachingWrapperFilter类: CachingWrapperFilter类是Lucene用于实现缓存过滤器的类。在搜索时,有时候需要对搜索结果进行缓存,而CachingWrapperFilter类就是用于实现这个功能的类。
CustomScoreQuery类: CustomScoreQuery类是Lucene用于实现自定义评分的类。在搜索时,有时候需要根据业务需求进行自定义评分,而CustomScoreQuery类就是用于实现这个功能的类。
MultiSearcher类: MultiSearcher类是Lucene用于在多个索引之间进行搜索的类。在搜索时,有时候需要同时搜索多个索引,而MultiSearcher类就是用于实现这个功能的类。
FuzzyQuery类: FuzzyQuery类是Lucene用于实现模糊查询的类。在搜索时,有时候需要进行拼写错误纠正或者模糊匹配,而FuzzyQuery类就是用于实现这个功能的类。
PhraseQuery类: PhraseQuery类是Lucene用于实现短语查询的类。在搜索时,有时候需要查询文本中的短语,而PhraseQuery类就是用于实现这个功能的类。
PrefixQuery类: PrefixQuery类是Lucene用于实现前缀查询的类。在搜索时,有时候需要查询文本中以某个前缀开头的单词,而PrefixQuery类就是用于实现这个功能的类。
RangeQuery类: RangeQuery类是Lucene用于实现范围查询的类。在搜索时,有时候需要查询文本中某个字段的值在一定范围内的文档,而RangeQuery类就是用于实现这个功能的类。
TermQuery类: TermQuery类是Lucene用于实现词项查询的类。在搜索时,有时候需要查询文本中某个单词的出现情况,而TermQuery类就是用于实现这个功能的类。
WildcardQuery类: WildcardQuery类是Lucene用于实现通配符查询的类。在搜索时,有时候需要查询文本中符合一定规则的单词,而WildcardQuery类就是用于实现这个功能的类。
BooleanQuery类: BooleanQuery类是Lucene用于实现布尔查询的类。在搜索时,有时候需要查询满足多个条件的文档,而BooleanQuery类就是用于实现这个功能的类。它可以将多个查询条件进行组合,包括AND(交集)、OR(并集)和NOT(排除)等操作。
BoostQuery类: BoostQuery类是Lucene用于实现查询加权的类。在搜索时,有时候需要对某些查询条件进行加权,以达到更精确的搜索结果,而BoostQuery类就是用于实现这个功能的类。
ConstantScoreQuery类: ConstantScoreQuery类是Lucene用于实现常量得分查询的类。在搜索时,有时候需要对多个查询条件进行组合,并对所有满足条件的文档都赋予一个相同的分值,而ConstantScoreQuery类就是用于实现这个功能的类。
DisjunctionMaxQuery类: DisjunctionMaxQuery类是Lucene用于实现最大化查询的类。在搜索时,有时候需要查询满足多个条件中最相关的文档,而DisjunctionMaxQuery类就是用于实现这个功能的类。它可以将多个查询条件进行组合,并找出其中得分最高的文档。
MultiPhraseQuery类: MultiPhraseQuery类是Lucene用于实现多短语查询的类。在搜索时,有时候需要查询文本中包含多个短语的文档,而MultiPhraseQuery类就是用于实现这个功能的类。
PayloadScoreQuery类: PayloadScoreQuery类是Lucene用于实现payload得分查询的类。在搜索时,有时候需要根据文档中的payload信息来计算得分,而PayloadScoreQuery类就是用于实现这个功能的类。
SynonymQuery类: SynonymQuery类是Lucene用于实现同义词查询的类。在搜索时,有时候需要将某些词语视为同义词,并进行查询,而SynonymQuery类就是用于实现这个功能的类。
FunctionScoreQuery类: FunctionScoreQuery类是Lucene用于实现自定义评分查询的类。在搜索时,有时候需要根据自定义的评分函数来计算得分,而FunctionScoreQuery类就是用于实现这个功能的类。
TermVectorsReader类:TermVectorsReader类是Lucene用于读取词向量的类。在搜索时,有时候需要对词向量进行查询和分析,而TermVectorsReader类就是用于实现这个功能的类。
FieldInvertState类:FieldInvertState类是Lucene用于表示索引中的文档域信息的类。在创建索引时,需要对文档域进行分析,并将其存储到索引中,而FieldInvertState类就是用于表示这些信息的类。
IndexCommit类:IndexCommit类是Lucene用于表示索引提交信息的类。在创建索引时,需要将索引进行提交,以便进行搜索,而IndexCommit类就是用于表示这些提交信息的类。
Sort类:Sort类是Lucene用于实现搜索结果排序的类。在搜索时,有时候需要对搜索结果进行排序,而Sort类就是用于实现这个功能的类。
SortField类:SortField类是Lucene用于表示排序字段的类。在进行搜索结果排序时,需要指定排序的字段和排序方式,而SortField类就是用于表示这些信息的类。
QueryRescorer类:QueryRescorer类是Lucene用于在搜索结果中重新计算得分的类。在搜索时,有时候需要根据一些特定的规则对搜索结果进行二次排序,而QueryRescorer类就是用于实现这个功能的类。
IndexWriterConfig类:IndexWriterConfig类是Lucene用于配置索引写入器的类。在创建索引时,需要对索引写入器进行配置,以满足不同的需求,而IndexWriterConfig类就是用于实现这个功能的类。
DirectoryReader类:DirectoryReader类是Lucene用于读取索引的类。在搜索时,需要读取索引来获取搜索结果,而DirectoryReader类就是用于实现这个功能的类。
ParallelCompositeReader类:ParallelCompositeReader类是Lucene用于将多个索引合并成一个索引的类。在搜索时,有时候需要同时搜索多个索引,而ParallelCompositeReader类就是用于实现这个功能的类。
SegmentInfos类:SegmentInfos类是Lucene用于表示索引中的段信息的类。在创建索引时,需要将索引分成多个段,以便进行优化和管理,而SegmentInfos类就是用于表示这些段信息的类。
SegmentReader类:SegmentReader类是Lucene用于读取索引中的一个段的类。在进行搜索时,需要读取索引中的一个或多个段来获取搜索结果,而SegmentReader类就是用于实现这个功能的类。
ChecksumIndexInput类:ChecksumIndexInput类是Lucene用于读取索引数据并校验校验和的类。在读取索引数据时,需要进行校验以确保数据的完整性,而ChecksumIndexInput类就是用于实现这个功能的类。
ChecksumIndexOutput类:ChecksumIndexOutput类是Lucene用于写入索引数据并计算校验和的类。在写入索引数据时,需要计算校验和以确保数据的完整性,而ChecksumIndexOutput类就是用于实现这个功能的类。
FilteredQuery类:FilteredQuery类是Lucene用于对搜索结果进行过滤的类。在搜索时,有时候需要根据一些条件对搜索结果进行过滤,而FilteredQuery类就是用于实现这个功能的类。
FuzzyQuery类:FuzzyQuery类是Lucene用于进行模糊搜索的类。在搜索时,有时候需要进行模糊搜索以获取更全面的搜索结果,而FuzzyQuery类就是用于实现这个功能的类。
NumericRangeQuery类:NumericRangeQuery类是Lucene用于进行数值范围搜索的类。在搜索时,有时候需要根据一定的数值范围来获取搜索结果,而NumericRangeQuery类就是用于实现这个功能的类。
TermRangeQuery类:TermRangeQuery类是Lucene用于进行词项范围搜索的类。在搜索时,有时候需要根据一定的词项范围来获取搜索结果,而TermRangeQuery类就是用于实现这个功能的类。
TopDocs类:TopDocs类是Lucene用于表示搜索结果的类。在进行搜索时,需要获取搜索结果并对其进行处理和展示,而TopDocs类就是用于表示这些搜索结果的类。
TopFieldDocs类:TopFieldDocs类是Lucene用于表示带有排序字段的搜索结果的类。在进行搜索结果排序时,需要获取带有排序字段的搜索结果并对其进行处理和展示,而TopFieldDocs类就是用于表示这些搜索结果的类。文章来源:https://www.toymoban.com/news/detail-698449.html
PrefixQuery类:PrefixQuery类是Lucene用于进行前缀搜索的类。在搜索时,有时候需要根据词项的前缀来获取搜索结果,而PrefixQuery类就是用于实现这个功能的类。文章来源地址https://www.toymoban.com/news/detail-698449.html
SegmentInfos类:SegmentInfos类是Lucene用于表示索引中的段信息的类。在创建索引时,需要将索引分成多个段,以便进行优化和管理,而SegmentInfos类就是用于表示这些段信息的类。
SegmentReader类:SegmentReader类是Lucene用于读取索引中的一个段的类。在进行搜索时,需要读取索引中的一个或多个段来获取搜索结果,而SegmentReader类就是用于实现这个功能的类。
ChecksumIndexInput类:ChecksumIndexInput类是Lucene用于读取索引数据并校验校验和的类。在读取索引数据时,需要进行校验以确保数据的完整性,而ChecksumIndexInput类就是用于实现这个功能的类。
ChecksumIndexOutput类:ChecksumIndexOutput类是Lucene用于写入索引数据并计算校验和的类。在写入索引数据时,需要计算校验和以确保数据的完整性,而ChecksumIndexOutput类就是用于实现这个功能的类。
FilteredQuery类:FilteredQuery类是Lucene用于对搜索结果进行过滤的类。在搜索时,有时候需要根据一些条件对搜索结果进行过滤,而FilteredQuery类就是用于实现这个功能的类。
FuzzyQuery类:FuzzyQuery类是Lucene用于进行模糊搜索的类。在搜索时,有时候需要进行模糊搜索以获取更全面的搜索结果,而FuzzyQuery类就是用于实现这个功能的类。
NumericRangeQuery类:NumericRangeQuery类是Lucene用于进行数值范围搜索的类。在搜索时,有时候需要根据一定的数值范围来获取搜索结果,而NumericRangeQuery类就是用于实现这个功能的类。
TermRangeQuery类:TermRangeQuery类是Lucene用于进行词项范围搜索的类。在搜索时,有时候需要根据一定的词项范围来获取搜索结果,而TermRangeQuery类就是用于实现这个功能的类。
TopDocs类:TopDocs类是Lucene用于表示搜索结果的类。在进行搜索时,需要获取搜索结果并对其进行处理和展示,而TopDocs类就是用于表示这些搜索结果的类。
TopFieldDocs类:TopFieldDocs类是Lucene用于表示带有排序字段的搜索结果的类。在进行搜索结果排序时,需要获取带有排序字段的搜索结果并对其进行处理和展示,而TopFieldDocs类就是用于表示这些搜索结果的类。
PrefixQuery类:PrefixQuery类是Lucene用于进行前缀搜索的类。在搜索时,有时候需要根据词项的前缀来获取搜索结果,而PrefixQuery类就是用于实现这个功能的类。
到了这里,关于ChatGPT 学习 ES & lucene 底层写入原理,源码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!