作者:禅与计算机程序设计艺术
1.简介
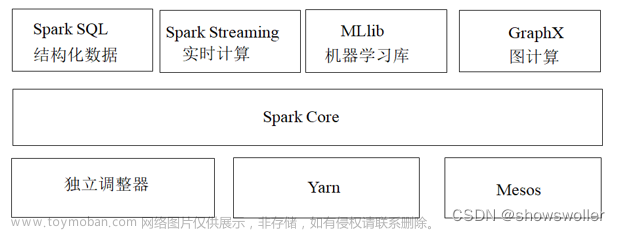
“Hadoop”是一个开源的分布式计算框架,基于云计算平台构建,提供海量数据的存储、分析处理和计算能力,广泛应用于金融、电信、互联网、移动通信等领域。Hadoop生态系统中存在大量的工程师和科学家,但这些人的水平参差不齐,各有所长,有些人擅长Linux开发、云计算、机器学习等,有些人更偏重于Hadoop基础设施建设、运维管理、架构设计和安全防护等方面,还有一些人具有丰富的产品经验、产品思维、沟通协调能力,能够有效解决复杂的业务需求并推动公司业务发展。因此,在Hadoop生态系统中建立起高端的人才队伍是当前和今后重要的工作。
一般来说,Hadoop生态系统的招聘要求如下:
-
本科及以上学历,熟悉计算机、编程语言、数据库、网络等相关知识,能够独立完成相关项目。
-
大数据专业毕业或者相关专业毕业者优先考虑。
-
对Hadoop生态系统有着浓厚兴趣,对大数据有强烈的热情,能够快速掌握新的工具或技术。
-
有良好的职业操守,诚实守信,具备良好的沟通表达和团队合作能力。
除了上述基本要求外,还有一些个人特质因素也会影响到招聘结果。例如:
-
英文听说读写能力:招聘主要根据英文简历筛选,如果候选人英文水平较差,则需要寻求其他工作机会。文章来源:https://www.toymoban.com/news/detail-698570.html
-
技术专长:尽管大部分Hadoop工程师都有多年的技术积累,但是在某些方面,他们却可以达到甚至超过行业前沿。此外,还有些Hadoop工程师比较擅长开源软件,因此喜欢研究开源社区的最新技术进展。文章来源地址https://www.toymoban.com/news/detail-698570.html
</
到了这里,关于Hadoop生态系统中的大数据基础知识教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!